

ml.dmlc.xgboost4j.java.XGBoostError: XGBoostModel training failed 原因分析与解决
先说下使用基本环境:spark 2.4.5 、 scala2.11 、 xgboost4j 0.90
问题:在基于spark环境使用scala版本的xgboost4j进行回归模型训练时,发现xgb4j偶尔会训练失败,偶尔训练成功,造成模型训练不稳定,训练失败时提示 XGBoostModel training failed报错,具体报错日志信息如下:
21/01/06 10:12:27 [dispatcher-event-loop-2] INFO TaskSetManager: Starting task 2.1 in stage 24.0 (TID 7447, BJHTYD-Hope-11-7-133-134.hadoop.jd.local, executor 9, partition 2, PROCESS_LOCAL, 7749 bytes) 21/01/06 10:12:27 [dispatcher-event-loop-2] INFO TaskSetManager: Starting task 18.1 in stage 24.0 (TID 7448, BJHTYD-Hope-11-11-23-143.hadoop.jd.local, executor 53, partition 18, PROCESS_LOCAL, 7749 bytes) 21/01/06 10:12:27 [dispatcher-event-loop-2] INFO TaskSetManager: Starting task 28.1 in stage 24.0 (TID 7449, BJHTYD-Guldan-46-40.hadoop.jd.local, executor 48, partition 28, PROCESS_LOCAL, 7749 bytes) 21/01/06 10:12:27 [dispatcher-event-loop-2] INFO BlockManagerInfo: Added broadcast_22_piece0 in memory on BJHTYD-Hope-11-7-133-134.hadoop.jd.local:31567 (size: 9.7 KB, free: 11.8 GB) 21/01/06 10:12:27 [dispatcher-event-loop-3] INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 13 to 11.7.133.134:38744 21/01/06 10:12:28 [task-result-getter-3] INFO TaskSetManager: Killing attempt 0 for task 2.0 in stage 24.0 (TID 7419) on BJHTYD-Hope-221-226.hadoop.jd.local as the attempt 1 succeeded on BJHTYD-Hope-11-7-133-134.hadoop.jd.local 21/01/06 10:12:28 [task-result-getter-3] INFO TaskSetManager: Finished task 2.1 in stage 24.0 (TID 7447) in 939 ms on BJHTYD-Hope-11-7-133-134.hadoop.jd.local (executor 9) (28/30) 21/01/06 10:12:28 [task-result-getter-2] INFO TaskSetManager: Killing attempt 0 for task 28.0 in stage 24.0 (TID 7445) on BJHTYD-Hope-11-11-23-143.hadoop.jd.local as the attempt 1 succeeded on BJHTYD-Guldan-46-40.hadoop.jd.local 21/01/06 10:12:28 [task-result-getter-2] INFO TaskSetManager: Finished task 28.1 in stage 24.0 (TID 7449) in 1073 ms on BJHTYD-Guldan-46-40.hadoop.jd.local (executor 48) (29/30) 21/01/06 10:12:28 [task-result-getter-1] WARN TaskSetManager: Lost task 28.0 in stage 24.0 (TID 7445, BJHTYD-Hope-11-11-23-143.hadoop.jd.local, executor 53): TaskKilled (another attempt succeeded) 21/01/06 10:12:28 [task-result-getter-1] INFO TaskSetManager: Task 28.0 in stage 24.0 (TID 7445) failed, but the task will not be re-executed (either because the task failed with a shuffle data fetch failure, so the previous stage needs to be re-run, or because a different copy of the task has already succeeded). 21/01/06 10:12:28 [spark-listener-group-shared] ERROR XGBoostTaskFailedListener: Training Task Failed during XGBoost Training: TaskKilled(another attempt succeeded,Vector(AccumulableInfo(629,None,Some(3973),None,false,true,None), AccumulableInfo(631,None,Some(0),None,false,true,None), AccumulableInfo(645,None,Some(0),None,false,true,None), AccumulableInfo(646,None,Some(0),None,false,true,None), AccumulableInfo(647,None,Some(52163715),None,false,true,None)),Vector(LongAccumulator(id: 629, name: Some(internal.metrics.executorRunTime), value: 3973), LongAccumulator(id: 631, name: Some(internal.metrics.resultSize), value: 0), LongAccumulator(id: 645, name: Some(internal.metrics.shuffle.write.bytesWritten), value: 0), LongAccumulator(id: 646, name: Some(internal.metrics.shuffle.write.recordsWritten), value: 0), LongAccumulator(id: 647, name: Some(internal.metrics.shuffle.write.writeTime), value: 52163715))), stopping SparkContext 21/01/06 10:12:28 [Thread-196] INFO AbstractConnector: Stopped Spark@6267f2d7{HTTP/1.1,[http/1.1]}{0.0.0.0:0} 21/01/06 10:12:28 [Thread-196] INFO SparkUI: Stopped Spark web UI at http://BJHTYD-Hope-163-2.hadoop.jd.local:20364 21/01/06 10:12:29 [task-result-getter-0] INFO TaskSetManager: Killing attempt 0 for task 18.0 in stage 24.0 (TID 7435) on BJHTYD-Guldan-46-4.hadoop.jd.local as the attempt 1 succeeded on BJHTYD-Hope-11-11-23-143.hadoop.jd.local 21/01/06 10:12:29 [task-result-getter-0] INFO TaskSetManager: Finished task 18.1 in stage 24.0 (TID 7448) in 1850 ms on BJHTYD-Hope-11-11-23-143.hadoop.jd.local (executor 53) (30/30) 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: ShuffleMapStage 24 (rdd at DataUtils.scala:92) finished in 4.732 s 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: looking for newly runnable stages 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: running: Set() 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: waiting: Set(ResultStage 25) 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: failed: Set() 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: Submitting ResultStage 25 (MapPartitionsRDD[101] at mapPartitions at XGBoost.scala:343), which has no missing parents 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO YarnClusterScheduler: Cancelling stage 25 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO YarnClusterScheduler: Killing all running tasks in stage 25: Stage cancelled 21/01/06 10:12:29 [dag-scheduler-event-loop] INFO DAGScheduler: ResultStage 25 (foreachPartition at XGBoost.scala:452) failed in 0.090 s due to Job aborted due to stage failure: Task serialization failed: java.lang.IllegalStateException: Cannot call methods on a stopped SparkContext. This stopped SparkContext was created at:
问题分析:
第一步:首先检查自己的训练数据是否符合要求,例如含有缺失值,只要有缺失值,XGB4j就会training failed,由于DataFrame数据已经进行na.fill处理,就没有在意缺失值,然后将一部分训练数据打印出来,发现的确存在部分缺失数据,对缺失数据进行修复,发现的确存在缺失值,将缺失值进行修复,重新进行训练,发现依然存在训练失败。
第二步:在第二次进行训练失败的日志中,可以看到存在【Task 28.0 in stage 24.0 (TID 7445) failed, but the task will not be re-executed】,部分executor的task失败或者超时,或者集群分配的node由于资源设置不合理导致失败,由于spark具有推测执行spark.speculation机制,会针对task创建副本,如果副本先运行成功,会杀掉主task,发现这个逻辑与xgb4j 0.90的逻辑存在冲突,xgb4j 0.90发现如果有worker运行失败(worker概念参考xgboost4j的原理解析文档),就会杀掉spark,无法进行后续的所有任务。
第三步:针对第二步存在的问题,有两种解决方法,第一种是依然还使用现有环境和xgb4j版本,关闭spark的spark.speculation机制,需要需要训练的样本量调整spark资源,包括executor的资源(内存)、超时时间等信息,防止executor的task运行失败,可以成功进行模型训练,这种方法较简单,不过偶尔因为环境或者资源问题还是会训练失败,不够稳定,第二种是根据xgboost4j的GitHub,发现xgb4j官方在一个月之前对此bug进行fix,发布了xgboost4j 1.3.0版本【https://github.com/dmlc/xgboost/releases】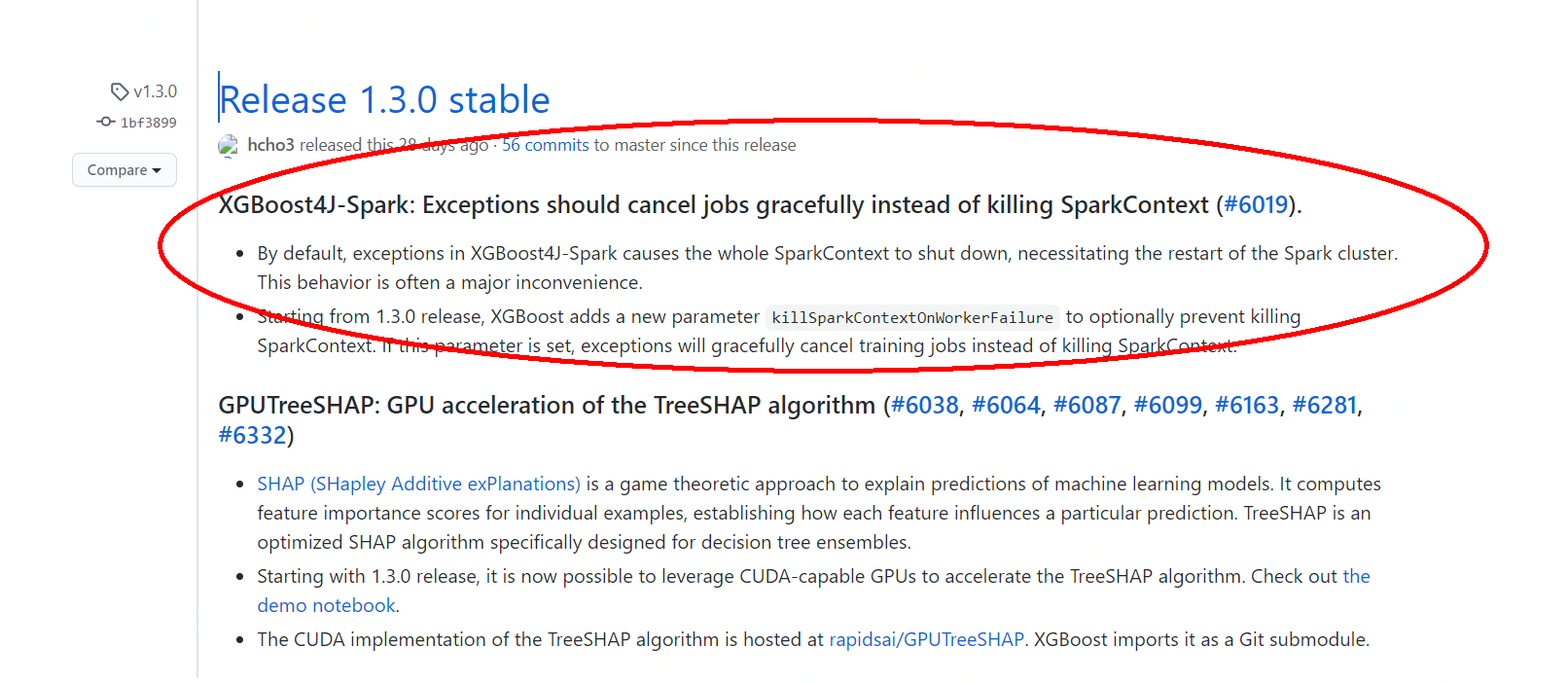 ,也能够解决此类问题,不过xgboost4j 1.3.0需要scala版本是2.12,由于spark集群环境限制,需要使用spark 3.0的环境,目前也可以解决此类问题。
,也能够解决此类问题,不过xgboost4j 1.3.0需要scala版本是2.12,由于spark集群环境限制,需要使用spark 3.0的环境,目前也可以解决此类问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号