scrapy介绍
目录
scrapy
scrapy介绍
# requsets bs4 selenium 模块
# 框架 :django ,scrapy--->专门做爬虫的框架,爬虫界的django,大而全,爬虫有的东西,它都自带
-
安装
# 安装 (win看人品,linux,mac一点问题没有) -pip3.8 install scrapy -装不上,基本上是因为twisted装不了,单独装 1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs 3、pip3 install lxml 4、pip3 install pyopenssl 5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/ 6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl 8、pip3 install scrapy -
架构分析
爬虫:spiders(自己定义的,可以有很多),定义爬取的地址,解析规则 引擎:engine ---》控制整个框架数据的流动,大总管 调度器:scheduler---》要爬取的 requests对象,放在里面,排队 下载中间件:DownloaderMiddleware---》处理请求对象,处理响应对象 下载器:Downloader ----》负责真正的下载,效率很高,基于twisted的高并发的模型之上 爬虫中间件:spiderMiddleware----》处于engine和爬虫直接的(用的少) 管道:piplines---》负责存储数据
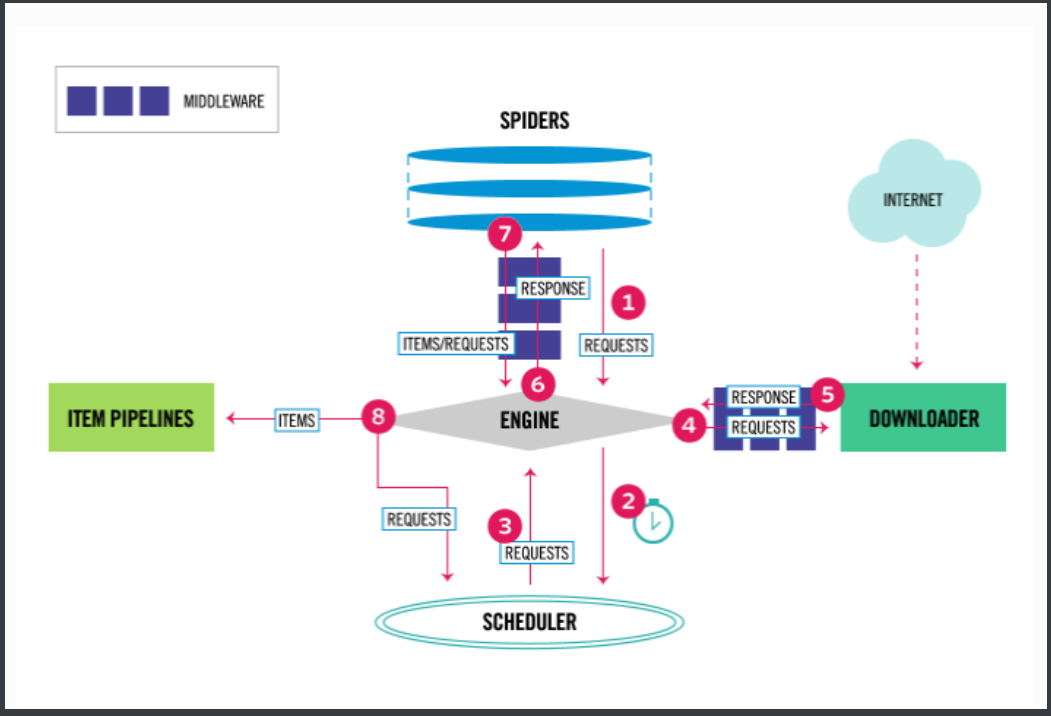
-
pycharm打开scrapy项目
# 创建出scrapy项目--下载scrapy会携带可执行文件 scrapy startproject firstscrapy # 创建项目 scrapy genspider 名字 网址 # 创建爬虫 等同于 创建app eg:scrapy genspider crewdel https://www.cnblogs.com/ # pycharm打开
scrapy架构介绍

# 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)--->在这里写代码
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事:设置请求头,设置cookie,使用代理,集成selenium
# 爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
scapy的一些命令
# 安装完成后,会有scrapy的可执行文件
# 创建项目
scrapy startproject 项目名字 # 跟创建django一样,pycharm能直接创建django
# 创建爬虫
scrapy genspider 名字 域名 # 创建爬虫 django的创建app
# pycharm打开scrapy的项目
# 运行爬虫
scrapy crawl 爬虫名字
# 想点击绿色箭头运行爬虫
新建一个run.py,写入,以后右键执行即可
from scrapy.cmdline import execute
execute(['scrapy','crawl','cnblogs','--nolog'])
# 补充:爬虫协议
http://www.cnblogs.com/robots.txt
scrapy项目目录结构
firstscrapy # 项目名
firstscrapy # 文件夹名字,核心代码,都在这里面
spiders # 爬虫的文件,里面有所有的爬虫
__init__.py
baidu.py # 百度爬虫
cnblogs.py #cnblogs爬虫
items.py # 有很多模型类---》以后存储的数据,都做成模型类的对象,等同于django的models.py
middlewares.py # 中间件:爬虫中间件,下载中间件都写在这里面
pipelines.py #项目管道---》以后写持久化,都在这里面写
run.py # 自己写的,运行爬虫
settings.py # 配置文件 django的配置文件
scrapy.cfg # 项目上线用的,不需要关注
scrapy解析数据
1 response对象有css方法和xpath方法
-css中写css选择器
-xpath中写xpath选择
2 重点1:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
3 重点2:
.extract_first() 取一个
.extract() 取所有
解析cnblogs
# def parse(self, response):
# # 解析数据 css解析
# article_list = response.css('article.post-item')
# for article in article_list:
# title = article.css('div.post-item-text>a::text').extract_first()
# author_img = article.css('div.post-item-text img::attr(src)').extract_first()
# author_name = article.css('footer span::text').extract_first()
# desc_old = article.css('p.post-item-summary::text').extract()
# desc = desc_old[0].replace('\n', '').replace(' ', '')
# if not desc:
# desc = desc_old[1].replace('\n', '').replace(' ', '')
# url=article.css('div.post-item-text>a::attr(href)').extract_first()
# # 文章真正的内容,没拿到,它不在这个页面中,它在下一个页面中
# print(title)
# print(author_img)
# print(author_name)
# print(desc)
# print(url)
def parse(self, response):
# 解析数据 xpath解析
article_list = response.xpath('//*[@id="post_list"]/article')
# article_list = response.xpath('//article[contains(@class,"post-item")]')
for article in article_list:
title = article.xpath('.//div/a/text()').extract_first()
author_img = article.xpath('.//div//img/@src').extract_first()
author_name = article.xpath('.//footer//span/text()').extract_first()
desc_old = article.xpath('.//p/text()').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
url = article.xpath('.//div/a/@href').extract_first()
# 文章真正的内容,没拿到,它不在这个页面中,它在下一个页面中
print(title)
print(author_img)
print(author_name)
print(desc)
print(url)
settings相关配置,提高爬虫效率
scrapy 项目有项目自己的配置文件,还有内置的
1. 基础配置
#1 了解
BOT_NAME = "firstscrapy" #项目名字,整个爬虫名字
#2 爬虫存放位置 了解
SPIDER_MODULES = ["firstscrapy.spiders"]
NEWSPIDER_MODULE = "firstscrapy.spiders"
#3 记住 是否遵循爬虫协议,一般都设为False
ROBOTSTXT_OBEY = False
# 4 记住
USER_AGENT = "firstscrapy (+http://www.yourdomain.com)"
#5 记住 日志级别
LOG_LEVEL='ERROR'
#6 记住 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#7 记住 后面学 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
#8 后面学 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
#9 后面学 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
2. 增加爬虫的爬取效率
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。
#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False
# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s
持久化方案
# 方式一:(parse必须有return值,必须是列表套字典形式--->使用命令,可以保存到json格式中,csv中。。。)
scrapy crawl cnblogs -o cnbogs.json
# 方式二:我们用的,使用pipline存储---》可以存到多个位置
-第一步:在item.py中写一个类
class FirstscrapyItem(scrapy.Item):
title = scrapy.Field()
author_img = scrapy.Field()
author_name = scrapy.Field()
desc = scrapy.Field()
url = scrapy.Field()
# 博客文章内容,但是暂时没有
content = scrapy.Field()
-第二步:在pipline.py中写代码,写一个类:open_spide,close_spider,process_item
-open_spide:开启爬虫会触发
-close_spider:爬完会触发
-process_ite:每次要保存一个对象会触发
class FirstscrapyFilePipeline:
def open_spider(self, spider):
print('我开了')
self.f=open('a.txt','w',encoding='utf-8')
def close_spider(self, spider):
print('我关了')
self.f.close()
# 这个很重要
def process_item(self, item, spider):
self.f.write(item['title']+'\n')
return item
-第三步:配置文件配置
ITEM_PIPELINES = {
"firstscrapy.pipelines.FirstscrapyFilePipeline": 300, # 数字越小,优先级越高
}
-第四步:在解析方法parse中yield item对象
全站爬取cnblogs文章
1.request和response对象传递参数
# Request创建:在parse中,for循环中,创建Request对象时,传入meta
yield Request(url=url, callback=self.detail_parse,meta={'item':item})
# Response对象:detail_parse中,通过response取出meta取出item,把文章详情写入
yield item
2.解析下一页并继续爬取
import scrapy
from bs4 import BeautifulSoup
from firstscrapy.items import FirstscrapyItem
from scrapy.http.request import Request
class CnblogsSpider(scrapy.Spider):
name = "cnblogs"
allowed_domains = ["www.cnblogs.com"]
start_urls = ["http://www.cnblogs.com/"]
# 解析出下一页地址,继续爬取
def parse(self, response):
article_list = response.xpath('//*[@id="post_list"]/article')
# article_list = response.xpath('//article[contains(@class,"post-item")]')
# l=[]
for article in article_list:
item = FirstscrapyItem()
title = article.xpath('.//div/a/text()').extract_first()
item['title'] = title
author_img = article.xpath('.//div//img/@src').extract_first()
item['author_img'] = author_img
author_name = article.xpath('.//footer//span/text()').extract_first()
item['author_name'] = author_name
desc_old = article.xpath('.//p/text()').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
item['desc'] = desc
url = article.xpath('.//div/a/@href').extract_first()
item['url'] = url
# print(title)
# yield item对象 不完整,缺文章的content,而文章的content在下一个页面中,而此处要yield一个Request对象
# yield item
yield Request(url=url,callback=self.parser_detail,meta={'item':item}) # 爬完后执行的解析方法
next='https://www.cnblogs.com'+response.css('div.pager>a:last-child::attr(href)').extract_first()
print(next) # 继续爬取
yield Request(url=next,callback=self.parse)
# 解析详情的方法
def parser_detail(self,response):
# print(response.status)
# 解析出文章内容
content=response.css('#cnblogs_post_body').extract_first()
# print(str(content))
# 如何放到item中
item=response.meta.get('item')
if content:
item['content']=content
else:
item['content'] = '没查到'
yield item
爬取的数据,存到mysql中
scrapy解析返回数据格式的两种方式
# 解析返回的数据
"""方式一:使用bs4,解析 """
# print(response.text)
# soup=BeautifulSoup(response.text,'lxml')
# print(soup.text)
""" 方式二:scrapy自带的解析"""
# response.css()
# response.xpath()
代码展示
1.""" 解析数据 css解析"""
def parse(self, response):
article_list=response.css('article.post-item')
for article in article_list:
title=article.css('div.post-item-text>a::text').extract_first()
author_img=article.css('div.post-item-text>p>a>img::attr(src)').extract_first()
author_name=article.css('footer.post-item-foot>a>span::text').extract_first()
desc_old=article.css('p.post-item-summary::text').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
url = article.css('div.post-item-text>a::attr(href)').extract_first()
print(title)
print(author_img)
print(author_name)
print(desc)
print(url)
2. 解析数据 xpath解析
def parse(self, response):
"""
//任意路径下 /仅邻路径下 div下的a标签 .是当前路径下
"""
article_list = response.xpath('//*[@id="post_list"]/article')
# article_list = response.xpath('//article[contains(@class,"post-item")]')
for article in article_list:
title = article.xpath('.//div/a/text()').extract_first()
author_img = article.xpath('.//div//img/@src').extract_first()
author_name = article.xpath('.//footer//span/text()').extract_first()
desc_old = article.xpath('.//p/text()').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
url = article.xpath('.//div/a/@href').extract_first()
# 文章真正的内容,没拿到,它不在这个页面中,它在下一个页面中
print(title)
print(author_img)
print(author_name)
print(desc)
print(url)
爬取的数据存到mysql中
# 存到mysql中
class FirstscrapyMySqlPipeline:
def open_spider(self, spider):
print('我开了')
self.conn = pymysql.connect(
user='root',
password="",
host='127.0.0.1',
database='cnblogs',
port=3306)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
print('我关了')
self.cursor.close()
self.conn.close()
# 这个很重要
def process_item(self, item, spider):
sql = '''INSERT INTO aritcle (title,author_img,author_name,`desc`,url,content) VALUES(%s,%s,%s,%s,%s,%s);'''
print(len(item['content'])) # 可能会超长
# print('-----')
self.cursor.execute(sql,
args=[item['title'], item['author_img'], item['author_name'], item['desc'], item['url'],item['content']
])
self.conn.commit()
return item
爬虫和下载中间件
爬虫中间件:处于爬虫和引擎之间的
下载中间件:处于引擎和下载器之间的
主要用的是下载中间件,爬虫中间件,了解即可,在中间件里面:进来的时候是个'Request'对象,出去的时候是个'Response'对象
# 爬虫中间件
class FirstscrapySpiderMiddleware:
# 进入到爬虫时,触发它
def process_spider_input(self, response, spider):
return None
# 出爬虫时,触发它
def process_spider_output(self, response, result, spider):
for i in result:
yield i
#出异常时,触发它
def process_spider_exception(self, response, exception, spider):
pass
# 第一次爬取,
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
# 爬虫开启会触发
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
# 下载中间件
class FirstscrapyDownloaderMiddleware:
# 请求来了,从引擎进入到下载器会触发,这里有request对象
def process_request(self, request, spider):
# 必须返回以下情况:
# - return None:继续下一个中间件
# - return a Response object:结束掉,这个请求就不爬取了,回到引擎中
# - return a Request object :把请求对象给引擎,引擎把它再次放到调度器中,等待下一次调度
# - raise IgnoreRequest: 就会执行process_exception()
return None
def process_response(self, request, response, spider):
# 请求下载完成,回来经过:request请求对象, response响应对象
# - return a Response object:继续走下一个中间件的process_response
# - return a Request object :把请求对象给引擎,引擎把它再次放到调度器中,等待下一次调度
# - raise IgnoreRequest:就会执行process_exception()
return response
def process_exception(self, request, exception, spider):
中间件中抛异常会走到
pass
# 下载中间件的process_request,因为有request对象,就是要爬取的对象
-修改请求头
-加cookie
-加代理
--------
-集成selenium
加代理,cookies,header,加入selenium
1 加入代理
# 第一步:
-在下载中间件写process_request方法
def get_proxy(self):
import requests
res = requests.get('http://127.0.0.1:5010/get/').json()
if res.get('https'):
return 'https://' + res.get('proxy')
else:
return 'http://' + res.get('proxy')
def process_request(self, request, spider):
request.meta['proxy'] = self.get_proxy()
return None
# 第二步:代理可能不能用,会触发process_exception,在里面写
def process_exception(self, request, exception, spider):
print('-----',request.url) # 这个地址没有爬
return request
2 加入cookie,修改请求头,随机生成UserAgent
# 加cookie
def process_request(self, request, spider):
print(request.cookies)
request.cookies['name']='kimi'
return None
# 修改请求头
def process_request(self, request, spider):
print(request.headers)
request.headers['referer'] = 'http://www.lagou.com'
return None
# 动态生成User-agent使用
def process_request(self, request, spider):
# fake_useragent模块
from fake_useragent import UserAgent
ua = UserAgent()
request.headers['User-Agent']=str(ua.random)
print(request.headers)
return None
3集成selenium
# 集成selenium 因为有的页面,是执行完js后才渲染完,必须使用selenium去爬取数据才完整
# 第一步:在爬虫类中写
from selenium import webdriver
class CnblogsSpider(scrapy.Spider):
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.implicitly_wait(10)
def close(spider, reason):
spider.bro.close() #浏览器关掉
# 第二步:在中间件中
def process_request(self, request, spider):
# 爬取下一页这种地址---》用selenium,但是文章详情,就用原来的
if 'sitehome/p' in request.url:
spider.bro.get(request.url)
from scrapy.http.response.html import HtmlResponse
response = HtmlResponse(url=request.url, body=bytes(spider.bro.page_source, encoding='utf-8'))
return response
else:
return None
去重规则源码分析(布隆过滤去)
# 调度器可以去重,研究一下,如何去重的
# 要爬取的Request对象,在进入到scheduler调度器排队之前,先执行enqueue_request,它如果return False,这个Request就丢弃掉,不爬了----》如何判断这个Request要不要丢弃掉,执行了self.df.request_seen(request),它来决定的-----》RFPDupeFilter类中的方法----》request_seen---》会返回True或False----》如果这个request在集合中,说明爬过了,就return True,如果不在集合中,就加入到集合中,然后返回False
# 调度器源码
from scrapy.core.scheduler import Scheduler
# 这个方法如果return True表示这个request要爬取,如果return False表示这个网址就不爬了(已经爬过了)
def enqueue_request(self, request: Request) -> bool:
# request当次要爬取的地址对象
if self.df.request_seen(request):
# 有的请情况,在爬虫中解析出来的网址,不想爬了,就就可以指定
# yield Request(url=url, callback=self.detail_parse, meta={'item': item},dont_filter=True)
# 如果符合这个条件,表示这个网址已经爬过了
return False
return True
# self.df 去重类 是去重类的对象 RFPDupeFilter
-在配置文件中如果配置了:DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'表示,使用它作为去重类,按照它的规则做去重
-RFPDupeFilter的request_seen
def request_seen(self, request: Request) -> bool:
# request_fingerprint 生成指纹
fp = self.request_fingerprint(request) #request当次要爬取的地址对象
#判断 fp 在不在集合中,如果在,return True
if fp in self.fingerprints:
return True
#如果不在,加入到集合,return False
self.fingerprints.add(fp)
return False
# 传进来是个request对象,生成的是指纹
-爬取的网址:https://www.cnblogs.com/teach/p/17238610.html?name=lqz&age=19
-和 https://www.cnblogs.com/teach/p/17238610.html?name=lqz&age=19
-它俩是一样的,返回的数据都是一样的,就应该是一条url,就只会爬取一次
-所以 request_fingerprint 就是来把它们做成一样的(核心原理是把查询条件排序,再拼接到后面)
-生成指纹,指纹是什么? 生成的指纹放到集合中去重
-www.cnblogs.com?name=lqz&age=19
-www.cnblogs.com?age=19&name=lqz
-上面的两种地址生成的指纹是一样的
# 测试指纹
from scrapy.utils.request import RequestFingerprinter
from scrapy import Request
fingerprinter = RequestFingerprinter()
request1 = Request(url='http://www.cnblogs.com?name=lqz&age=20')
request2 = Request(url='http://www.cnblogs.com?age=20&name=lqz')
res1 = fingerprinter.fingerprint(request1).hex()
res2 = fingerprinter.fingerprint(request2).hex()
print(res1)
print(res2)
总结:
# 总结:scrapy的去重规则
-根据配置的去重类RFPDupeFilter的request_seen方法,如果返回True,就不爬了,如果返回False就爬
-后期咱们可以使用自己定义的去重类,实现去重
# 更小内存实现去重
-如果是集合:存的数据库越多,占内存空间越大,如果数据量特别大,可以使用布隆过滤器实现去重
# 布隆过滤器:https://zhuanlan.zhihu.com/p/94668361
#bloomfilter:是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素在一个集合内是否存在,具有很好的空间和时间效率。(典型例子,爬虫url去重)
# 原理: BloomFilter 会开辟一个m位的bitArray(位数组),开始所有数据全部置 0 。当一个元素(www.baidu.com)过来时,能过多个哈希函数(h1,h2,h3....)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。
# Python中使用布隆过滤器
# 测试布隆过滤器
# 可以自动扩容指定错误率,底层数组如果大于了错误率会自动扩容
# from pybloom_live import ScalableBloomFilter
# bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
# url = "www.cnblogs.com"
# url2 = "www.liuqingzheng.top"
# bloom.add(url)
# bloom.add(url2)
# print(url in bloom)
# print(url2 in bloom)
from pybloom_live import BloomFilter
bf = BloomFilter(capacity=10)
url = 'www.baidu.com'
bf.add(url)
bf.add('aaaa')
bf.add('ggg')
bf.add('deww')
bf.add('aerqaaa')
bf.add('ae2rqaaa')
bf.add('aerweqaaa')
bf.add('aerwewqaaa')
bf.add('aerereweqaaa')
bf.add('we')
print(url in bf)
print("wa" in bf)
# 如果有去重的情况,就可以使用集合---》但是集合占的内存空间大,如果到了亿级别的数据量,想一种更小内存占用,而去重的方案----》布隆过滤器
# 布隆过滤器:通过不同的hash函数,加底层数组实现的极小内存去重
# python中如何使用:pybloom_live
-指定错误率
-指定大小
# 使用redis实现布隆过滤器
-编译redis---》把第三方扩展布隆过滤器编译进去,才有这个功能
-https://zhuanlan.zhihu.com/p/94668736
# 重写scrapy的过滤类
scrapy-redis实现分布式爬虫
# 什么是分布式爬虫
-集群:一个项目,在多个机器上部署,每个机器完成完整的功能,称之为集群
-原来使用一台机器爬取cnblogs整站
-现在想使用3台机器爬取cnblogs整站
- 每台机器爬取数据是不一样的
- 最终组装成完整的数据
# 如果变成分布式,面临的问题
-1 去重集合,我们要使用同一个----》redis集合
-2 多台机器使用同一个调度器:Scheduler,排队爬取,使用同一个队列
# scrapy-redis 已经解决这个问题了,我只需要在我们单机基础上,改动一点,就变成了分布式爬虫
# 使用步骤
第一步:安装scrapy-redis ---》pip3 install scrapy-redis
第二步:改造爬虫类
from scrapy_redis.spiders import RedisSpider
class CnblogSpider(RedisSpider):
name = 'cnblog_redis'
allowed_domains = ['cnblogs.com']
# 写一个key:redis列表的key,起始爬取的地址
redis_key = 'myspider:start_urls'
第三步:配置文件配置
# 分布式爬虫配置
# 去重规则使用redis
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #看了源码
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 先进先出:队列,先进后出:栈
# 持久化:文件,mysql,redis
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsFilePipeline': 300,
'cnblogs.pipelines.CnblogsMysqlPipeline': 100,
'scrapy_redis.pipelines.RedisPipeline': 400, #简单看
}
第四步:在多台机器上启动scrapy项目,在一台机器起了多个scrapy爬虫进程,就相当于多台机器
第五步:把起始爬取的地址放到redis的列表中
lpush mycrawler:start_urls http://www.cnblogs.com/
拓展
# 原来的去重规则
class RFPDupeFilter(BaseDupeFilter):
def request_seen(self, request):
# request_fingerprint 生成指纹
fp = self.request_fingerprint(request) #request当次要爬取的地址对象
#判断 fp 在不在集合中,如果在,return True
if fp in self.fingerprints:
return True
#如果不在,加入到集合,return False
self.fingerprints.add(fp)
return False
# scrapy-redis的去重规则
class RFPDupeFilter(BaseDupeFilter):
def request_seen(self, request):
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
# 持久化
class RedisPipeline(object):
def process_item(self, item, spider):
return deferToThread(self._process_item, item, spider)
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item
作业
1.持久化忘记前三期密码
2.用scrapy框架把cnblgos整站爬取,存到数据库中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号