面向对象之继承、封装、多态及反射
面向对象三大特性
面向对象之继承
面向对象的三大特性
封装 继承 多态
1.三者中继承最为核心(实操最多,体验最强)
2.封装和多态略微抽象
-
继承的含义
在编程世界中继承表示类与类之间资源的从属关系
eg:类A继承类B 儿子继承父亲的家业
-
继承的目的
在编程世界中类A继承类B就拥有了类B中所有的数据和方法使用权限
-
继承的实操
一种父类与子类
# 父类
class A :
name = 'kiki'
def play(self):
print('后天看展')
# 子类
class B(A):
pass
# 1.通过子类中的类直接用父类中的数据和方法
print(B.name) # kiki
print(B.play) # <function A.play at 0x000002F5B78E94C0>
print(B.play(12)) # 后天看展
# 2.通过子类产生的对象直接调用父类中的数据和方法
obj =B()
print(obj.__dict__) # {}
print(obj.name) # kiki
obj.play() # 后天看展
多种父类与子类
class A1:
name = 'kimi'
class A2:
name1 = 'rose'
class A3:
name2 = 'kiki'
class B(A1,A2,A3):
pass
print(B.name) # kimi
print(B.name1) # rose
print(B.name2) # kiki
1.在定义类的时候类名后面可以加括号填写其他类名 ,意味着继承其他类
class B(A):
pass
2.在python支持多继承,在括号内填写多个类名彼此逗号隔开即可
class B(A1,A2,A3):
pass
"""
1.继承其他类的类 B
我们称为之为子类、派生类
2.被继承的类 A,A1,A2,A3
我们称之为父类、基类、超类
我们最常用就是父类与子类
"""
继承的本质
本质1:对象:数据和功能的结合体
类(子类):多个对象相同数据和功能的结合体
父类:多个类(子类)相同数据和功能的结合体
>>>>:类与父类本质都是为了节省代码
本质2:继承的本质应该分为两部分
抽象:将多个类相同的东西抽出去形成一个新的类
继承:将多个类继承刚刚抽取出来的新的类
- 第一种情况 独立的两种类
class Student():
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def choice_course(self):
print(f'{self.name}正在选课')
class Teacher():
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def choice_course(self):
print(f'{self.name}正在授课')
stu1 = Student('kiki',18,'female')
print(stu1.__dict__) # {'name': 'kiki', 'age': 18, 'gender': 'female'}
print(stu1.name) # kiki
stu1.choice_course() # kiki正在选课
stu2 = Teacher('rose',36,'male')
print(stu2.__dict__) # {'name': 'rose', 'age': 36, 'gender': 'male'}
print(stu2.name) # rose
stu2.choice_course() # rose正在授课
- 第二种情况,把相同的功能抽出来,优化代码
class Penson():
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
class Student(Penson):
def choice_course(self):
print(f'{self.name}正在选课')
class Teacher(Penson):
def choice_course(self):
print(f'{self.name}正在授课')
stu1 = Student('kiki',18,'female')
print(stu1.__dict__) # {'name': 'kiki', 'age': 18, 'gender': 'female'}
print(stu1.name) # kiki
stu1.choice_course() # kiki正在选课
stu2 = Teacher('rose',36,'male')
print(stu2.__dict__) # {'name': 'rose', 'age': 36, 'gender': 'male'}
print(stu2.name) # rose
stu2.choice_course() # rose正在授课
对象查找名字的顺序(非常重要)
1.不继承情况下名字的查找顺序
2.单继承情况下名字的查找顺序
3.多继承情况下名字的查找顺序
对象的名称空间只存放着对象独有的属性,而对象们相似的属性是存放于类中的,对象在访问属性时,会优先从对象本身的__dict__中去查找,其次是类中的__dict__中查找
1、类中定义的变量是类的数据属性,是共享给所有对象用的,指向相同的内存地址
2、类中定义的函数是类的函数属性,类可以使用,但必须遵循函数的参数规则,有几个参数需要传几个参数
但其实类中定义的函数主要是给对象使用的,而且是绑定给对象的,虽然所有对象指向的都是相同的功能,但是绑定到不同的对象就是不同的绑定方法,内存地址各不相同(每产生一个对象就会新的绑定关系)
绑定到对象的方法特殊之处在于,绑定给谁就应该由谁来调用,谁来调用,就会将’谁’本身当做第一个参数自动传入(方法__init__也是一样的道理)
- 不继承情况下名字的查找顺序
class C1:
name ='kiki'
def func(self):
print('from func')
obj = C1()
print(C1.name) # kiki 类肯定找的自己的
obj.name = '我改了值' # 由于对象原本没有name属性 该语法会在对象名称空间中创建一个新的'键值对'
print(obj.name) # 我改了值
print(C1.name) # kiki
"""
对象查找名字的顺序
1.先从自己的名称空间中查找(产生的对象)
2.自己没有再去产生该对象的类中查找
3.如果类中也没有 那么直接报错
对象自身 >>> 产生对象的类
"""
-
单继承情况下名字的查找顺序
第一种情况下,单个父类和子类
# 单继承
class F1:
name = 'jason'
class S1(F1):
name = 'kevin'
pass
obj = S1()
# 1.对象名称空间中有name
obj.name = 'oscar' # 对象.name会修改name的值
print(obj.name) # oscar
# 2.对象名称空间没有name
print(obj.name) # kevin
# 对象名称空间和子类都没有name
print(obj.name) # jason
'''
对象自身 >>> 产生对象的类 >>> 父类
'''
第二种情况下,父类里循环套着子类
class F3:
name = 'jerry'
pass
class F2(F3):
# name = 'tony'
pass
class F1(F2):
# name = 'jason'
pass
class S1(F1):
# name = 'kevin'
pass
obj1 = S1()
# 1.对象名称空间中有name
# obj1.name = '嘿嘿嘿'
# print(obj1.name) # 嘿嘿嘿
# 2.对象名称空间没有name 去S1类中找
# print(obj1.name) # kevin
# 3.对象名称空间和子类S1都没有name,去F1类中找
# print(obj1.name) # jason
# 4.对象名称空间和子类S1、F1都没有name,去F2类中找
# print(obj1.name) # tony
# 4.对象名称空间和子类S1、F1、F2都没有name,去F3类中找
print(obj1.name) # jerry
练习题:
class A1:
def func1(self):
print('from A1 func1')
def func2(self):
print('from A1 func2')
self.func1()
class B1(A1):
def func1(self):
print('from B1 func1')
obj = B1()
obj.func2()
结果是:
from A1 func2
from B1 func1
解题过程
"""
1.首先B1()是在B1类中产生了一个对象obj,
2.obj.func2(),在obj的对象名称空间寻找,没有找到func2,
3.去产生obj对象的类中找,也没有func2
4.去B1的父类A1中寻找,找到func2,并打印了from A1 func2
5.self.func1() 其实就是obj.func1,又是从obj对象的名称空间找,没有func1
6.去产生obj对象的类中找,有func1并打印'from B1 func1
"""
注意点:
- 强调:对象点名字 永远从对象自身开始一步步查找,以后在看到self.名字的时候 一定要搞清楚self指代的是哪个对象
- 多继承情况下名字的查找顺序
菱形继承
广度优先(最后才会找闭环的定点)
非菱形继承
深度优先(从左往右每条道走完为止)
ps:mro()方法可以直接获取名字的查找顺序
查找的顺序:
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
代码实现:
非菱形继承 深度优先(从左往右每条道走完为止)
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
class F1:
name = 'jason'
pass
class F2:
name = 'oscar'
pass
class F3:
name = 'jerry'
pass
class S1(F1, F2, F3):
name = '嘿嘿嘿'
pass
obj = S1()
obj.name = '想干饭'
# 1.对象名称空间中有name
print(obj.name) # 想干饭
# 2.对象名称空间没有name 去S1类中找
print(obj.name) # 嘿嘿嘿
# 3.对象名称空间和子类S1都没有name,去F1类中找
print(obj.name) # jason
# 4.对象名称空间和子类S1,父类F1都没有name,去F2类中找
print(obj.name) # oscar
# 5.对象名称空间和子类S1,父类F1、F2都没有name,去F3类中找
print(obj.name) # jerry
菱形继承 广度优先(最后才会找闭环的定点)
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
class G:
name = 'from G'
pass
class A:
name = 'from A'
pass
class B:
name = 'from B'
pass
class C:
name = 'from C'
pass
class D(A):
name = 'from D'
pass
class E(B):
name = 'from E'
pass
class F(C):
name = 'from F'
pass
class S1(D, E, F):
pass
obj = S1()
print(obj.name)
print(S1.mro())
"""查找的顺序逐层往下找如下
[<class '__main__.S1'>,
<class '__main__.D'>, <class '__main__.A'>,
<class '__main__.E'>, <class '__main__.B'>,
<class '__main__.F'>, <class '__main__.C'>,
<class 'object'>]
"""
object 不参与菱形闭环
经典类和新式类
经典类:不继承object或者其子类的类 广度优先
新式类:继承object或者其子类的类 深度优先
python2中有经典类和新式类
python3中只有新式类(所有类默认都继承object)
"""
class Student(object):pass
ps:以后我们在定义类的时候 如果没有其他明确的父类 也可能习惯写object,为了兼容
基于继承的派生方法(重要)
子类基于父类某个方法做了扩展
1.子类通过调用父类的方法,通过 super().init(name, age, gender)
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(Person):
def __init__(self, name, age, gender,sid):
super().__init__(name, age, gender) # 子类调用父类的方法
self.sid = sid
class Teacher(Person):
def __init__(self, name, age, hobby,level):
super().__init__(name, age, hobby)
self.level = level
# 1.子类调用父类的方法
# stu1 = Student('jason', 18, 'male')
# print(stu1.__dict__) # {'name': 'jason', 'age': 18, 'gender': 'male'}
# tea1 = Teacher('tony', 28, 'female')
# print(tea1.__dict__) # {'name': 'tony', 'age': 28, 'gender': 'female'}
# 2.子类调用父类的方法 子类在自己类中添加数据
stu1 = Student('jason', 18, 'male', 532626)
print(stu1.__dict__) # {'name': 'jason', 'age': 18, 'gender': 'male', 'sid': 532626}
tea1 = Teacher('tony', 28, 'female', 96)
print(tea1.__dict__) # {'name': 'tony', 'age': 28, 'gender': 'female', 'level': 96}
2.通过对象添加数据
class MyList(list):
def append(self, values):
if values == 'jason':
print('jason不能尾部追加')
return
super().append(values)
obj = MyList()
print(obj, type(obj)) # [] <class '__main__.MyList'>
obj.append(111)
obj.append(222)
obj.append(333)
obj.append('jason') # jason不能尾部追加
# print(obj) # [111, 222, 333]
派生方法实战演练
1.序列化报错
import json
import datetime
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'jason'
}
res = json.dumps(d)
print(res)
"""
序列化报错
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type date is not JSON serializable
"""
"""
能被序列化的数据是有限的>>>:里里外外都必须是下列左边的类型
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
"""
2.为了避免报错,有两种转换方式
2.1 方式一:手动转换类型
d = {
't1':str(datetime.date.today()),
't2':str(datetime.datetime.today()),
}
res = json.dumps(d)
print(res) # {"t1": "2022-11-07", "t2": "2022-11-07 14:54:36.718329"}
2 方式二:派生方法
"""
查看dumps源码,注意cls参数,默认传JsonEncoder
查看该类的源码,发现default方法是报错的发起者
编写类继承JsonEncoder并重写default方法,之后调用dumps手动传cls=我们自己写的类
"""
d = {
't1':str(datetime.date.today()),
't2':str(datetime.datetime.today()),
}
class MyJsonEncoder(json.JSONEncoder):
def default(self, o):
"""
:param o: 接收无法被序列化的数据
:return: 返回可以被序列化的数据
"""
if isinstance(o, datetime.datetime): # 判断是否是datetime类型 如果是则处理成可以被序列化的类型
return o.strftime('%Y-%m-%d %X')
elif isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
return super().default(o) # 最后还是调用原来的方法 防止有一些额外操作没有做
res = json.dumps(d,cls=MyJsonEncoder)
print(res) # {"t1": "2022-11-07", "t2": "2022-11-07 15:05:29.148726"}
面向对象之封装
封装:就是将数据和功能‘封装’起来
隐藏:将数据和功能隐藏起来不让用户直接调用,而是开发一些接口间接调用从而可以在接口内添加额外的操作
伪装:将类里面的方法在调用时伪装成类里面的数据不用加括号(obj.func)
原来的类:
class C:
def func(self):pass
obj = C()
obj.func()
""" 经过伪装,我们可以直接伪装为对象点函数名"""
obj.func
代码实现:
1.类中隐藏的属性
class Myclass:
school_name = '熊猫交流大会'
__= '成和花'
_name = '成和叶'
"""类在定义阶段,名字前面有两个下划线,那么该名字会被隐藏起来,无法访问"""
__age = 2
"""在python中其实没有真正意义上的隐藏 仅仅是换了个名字而已 _类名__名字"""
def __choice_name(self):
print('花花在吃竹笋')
# 1.正常调用类中正常的变量名
print(Myclass.school_name) # 熊猫交流大会
obj = Myclass()
print(obj.school_name) # 熊猫交流大会
print(obj.__) # 成和花
print(obj._name) # 成和叶
# 2.访问隐藏的变量名 ,无法访问,会报错
# print(obj.__age) # AttributeError: 'Myclass' object has no attribute '__age'
# 3.如果在函数调用添加类中的变量名和数据值,之后调用是直接访问添加的变量名和数据值
Myclass.__age = '3' # 无法隐藏
print(obj.__age) # 3
obj.__addr= '浦东新区'
print(obj.__addr) # 浦东新区
# 4.查看类下的源码,获取函数定义阶段的隐藏的变量名(__age)
print(Myclass.__dict__) # {'school_name': '熊猫交流大会', '__': '成和花',...........'__age': '3'}
print(Myclass._Myclass__age) # 2
2.对象可以直接使用类中隐藏的属性,前提是要在类体代码中的对象,是可以直接使用隐藏的名字
"""
以后我们在编写面向对象代码类的定义时 也会看到很多单下划线开头的名字,表达的意思通常也是不要直接访问 而是查找一下下面可能定义的接口
"""
class Person:
def __init__(self,name,age,hobby):
self.__name = name # 对象也可以拥有隐藏的属性
self.__age = age
self.__hobby = hobby
def get_info(self):
# 类体代码中,是可以直接使用隐藏的名字
print(f"""
姓名:{self.__name}
年龄:{self.__age}
爱好:{self.__hobby}
""")
obj = Person('kimi',20,'read')
obj.get_info()
"""
姓名:kimi
年龄:20
爱好:read
"""
3.自定义隐藏的属性接口
class Person:
def __init__(self,name,age,hobby):
self.__name = name # 对象也可以拥有隐藏的属性
self.__age = age
self.__hobby = hobby
def get_info(self):
# 类体代码中,是可以直接使用隐藏的名字
print(f"""
姓名:{self.__name}
年龄:{self.__age}
爱好:{self.__hobby}
""")
def set_name(self,new_name):
if len(new_name) == 0:
raise ValueError('自定义内容没有内容!!!')
elif new_name.isdigit():
raise ValueError('自定义内容不能是数字')
self.__name = new_name
obj =Person('kiki',18,'song')
# obj.set_name('kevin')
# obj.get_info()
"""
姓名:kevin
年龄:18
爱好:song
"""
# obj.set_name('')
# obj.get_info() # raise ValueError('自定义内容没有内容!!!')
obj.set_name(123)
obj.get_info() # TypeError: object of type 'int' has no len()
伪装
1.利用装饰器伪装成数据(property)
BMI指数:衡量一个人的体重与身高对健康影响的一个指标
体质指数(BMI)=体重(kg)÷身高^2(m)
EX:70kg÷(1.75×1.75)=22.86
class Person(object):
def __init__(self, name, height, weight):
self.name = name
self.height = height
self.weight = weight
@property
def BMI(self):
return self.weight/(self.height**2)
obj = Person('kimi',1.65,50)
# obj.BMI() # BMI应该作为人的基本数据而不是方法 TypeError: 'float' object is not callable
print(obj.BMI) # 18.36547291092746
点进源码可知
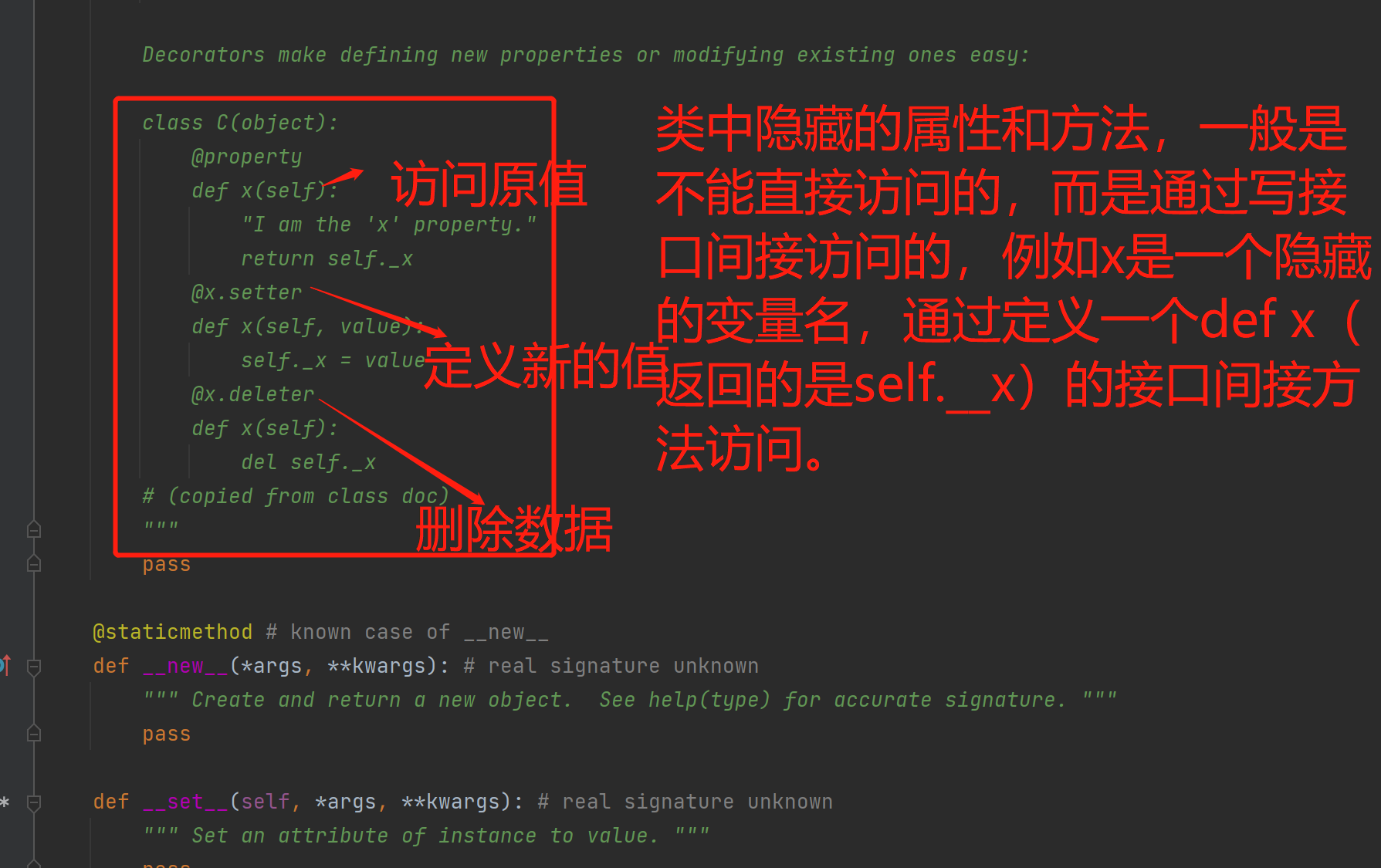
2.property拓展知识
class Foo:
def __init__(self,value):
self.__NAME =value # 将属性隐藏起来
@property
def name(self):
return self.__NAME
@name.setter
def name(self,value):
if not isinstance(value,str): # 在设定值之前进行类型检查
raise TypeError('%s must be str' %value)
self.__NAME =value # 通过类型检查后,将值value存放到真实的位置self.__NAME
@name.deleter
def name(self):
raise PermissionError('can not delete')
# 1.调用=对象
f=Foo('kimi')
# 2.对象调用name
print(f.name) # kimi
# 3.赋值给name
f.name = 'kimi123'
print(f.name) # kimi123
f.name = 'kimi'
print(f.name) # kimi 触发name.setter装饰器对应的函数
f.name = 123 # 触发了name.setter对应的函数name(f,123),抛出异常TypeError: 123 must be str
# 4.删除name
del f.name # 触发name.deleter对应的函数name(f),抛出异常PermissionError
面向对象之多态
1.第一种情况
多态:一种事物的多种形态
eg:气体 液体 固体
class Water:
def Be_called(self):
"""统称叫法——————水"""
pass
class Solid_state(Water):
def solid(self):
print('我是固态')
class Gaseous_state(Water):
def gaseous(self):
print('我是气态')
class Liquid_state(Water):
def liquid(self):
print('我是液体')
2.多态的形式(由上述改变)
class Water:
def Be_called(self):
"""统称叫法——————水"""
pass
class Solid_state(Water):
def Be_called(self):
print('我是固态')
class Gaseous_state(Water):
def Be_called(self):
print('我是气态')
class Liquid_state(Water):
def Be_called(self):
print('我是液体')
3.面向对象多态
面向对象多态是一种事物可以有多种形态但是针对相同的功能应该定义相同的方法,这样无论我们拿到是哪个具体的事物,都可以通过相同的方法调用功能
# s1 = 'hello world'
# l1 = [11, 22, 33, 44]
# d = {'name': 'jason', 'pwd': 123}
# print(s1.__len__())
# print(l1.__len__())
# print(d.__len__())
"""
鸭子类型:只要你看上去像鸭子 走路像鸭子 说话像鸭子 那么你就是鸭子
"""
3.1 linux系统中的多态
# linux系统
"""
文件 能够读取数据也能够保存数据
内存 能够读取数据也能够保存数据
硬盘 能够读取数据也能够保存数据
......
一切皆文件
"""
eg:
class File:
def read(self): pass
def write(self): pass
class Memory:
def read(self): pass
def write(self): pass
class Disk:
def read(self): pass
def write(self): pass
3.2 python中的多态
python永远提倡自由简介大方 不约束程序员行为 但是多态提供了约束的方法
为什么引入abc模块,主要是在面向对象里的多态有体现的,为了强制规定子类编写父类中相同的方法(不是为了派生)。
import abc
# 指定metaclass属性将类设置为抽象类,抽象类本身只是用来约束子类的,不能被实例化
class Water(metaclass=abc.ABCMeta):
@abc.abstractmethod # 该装饰器限制子类必须定义有一个名为Be_called的方法
def Be_called(self): # 抽象方法中无需实现具体的功能
pass
class liquid(Water): # 但凡继承Water的子类都必须遵循Water规定的标准
def Be_called(self):
pass
obj =liquid() # 若子类中没有一个名为be_called的方法则会抛出异常TypeError,无法实例化
面向对象之反射
利用字符串操作字符串的方法
1.hasattr() 重点
判断对象是否含有某个字符串对应的属性名或方法名
2.getattr() 重点
根据字符串获取对象对应的属性名(值)或方法名(函数体代码)
3.setattr()
根据字符串给对象设置或者修改数据
4.delattr()
根据字符串删除对象里面的名字
推导过程
class C1:
school_name = '大熊猫幼儿园'
def choice_site(self):
print('大熊猫正在选场景')
obj = C1
""" 判断某个名字对象是否可以使用(存在)"""
# 推导思路
#try:
# obj.xxx
#except AttributeError:
# print('你没有这个名字')
""" 判断用户随意指定的名字对象是否可以使用(存在)"""
#target_name = input('请输入对象可能使用的名字>>>>:').strip()
#try:
# obj.target_name
#except AttributeError:
# print('你没有这个名字')
# 反射:利用字符串操作对象的数据和方法
print(hasattr(obj,'school_name')) # True
print(getattr(obj,'school_name')) # 大熊猫幼儿园
print(getattr(obj,'choice_site')) #<function C1.choice_site at 0x000001EFDDE58790>
"""
字符串的名字和变量名区别
1.字符串:'school_name'
2.变量名:shcool_name
用户input输入的是'字符串',而类中数据和函数绑定的是变量名和函数名,而两者是不能互相交互的,这个时候就需要利用字符串操作对象的数据和方法,从而与用户交互
"""
eg:
class C1:
school_name = '大熊猫幼儿园'
def choice_site(self):
print('大熊猫正在选场景')
obj = C1
while True:
target_name = input('请输入您想要出场的熊猫名字>>>>:').strip()
if hasattr(obj,target_name):
print('恭喜你 系统中有该名字')
# 获取该名字对应的数据(值 函数)
data_or_func = getattr(obj,target_name)
if callable(data_or_func):
print('您本次使用的是系统中的某个方法')
data_or_func()
else:
print('您本次使用的是系统中的某个数据')
print(data_or_func)
else:
print('很抱歉,系统中没有这个名字')
反射实战案例
1.什么时候应该考虑使用反射,只要需求中出现了关键字
对象......字符串......
2.实战案例
1.模拟cmd终端
class WinCmd:
def tasklist(self):
print("""
1.学习编程
2.学习python
3.学习英语
""")
def ipconfig(self):
print("""
地址:127.0.0.1
地址:上海浦东新区
""")
def get(self,target_file):
print('获取指定文件',target_file)
def put(self,target_file):
print('上传指定文件',target_file)
def server_run(self):
print('欢迎进入简易版本cmd终端')
while True:
target_cmd = input('请输入您的指令>>>>:')
res = target_cmd.split(' ')
if len(res)==1:
if hasattr(self,res[0]):
getattr(self,res[0])()
else:
print(f'{res[0]}不是内部或者外部命令')
elif len(res)==2:
if hasattr(self,res[0]):
getattr(self,res[0])(res[1])
else:
print(f'{res[0]}不是内部或者外部命令')
obj = WinCmd()
obj.server_run()
2.一切皆对象
# 利用反射保留某个py文件中所有的大写变量名及对应的数据值
import settings
print(dir(settings)) # dir列举对象可以使用的名字
"""['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
"""
useful_dict = {}
for name in dir(settings):
if name.isupper():
useful_dict[name] = getattr(settings,name)
print(useful_dict) # {}
while True:
target_name = input('请输入某个名字>>>>:').strip()
if hasattr(settings,target_name):
print(getattr(settings,target_name))
else:
print('该模块文件中没有该名字')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号