模块
模块
索引取值与迭代取值的差异
l1 = [11,22,33,44,55,66,77,88,99]
1.索引取值
可以任意位置 任意次数取值
eg:l1[2] = 33 l1[1] =22 l1[2] = 33
不支持无序类型(如字典)的数据取值
2.迭代取值
只能从前往后依次取值无法后退
eg: 11,22,33....99
支持所有类型的数据取值(有序无序类型都可)
注意:两者的使用要根据实际应用场景来选择
模块
模块简介
在python中,一个py文件就是一个模块,文件名为xxx.py模块名则是xxx,导入模块就可以使用已经写好的功能。程序中的模块可以被重复使用,既保证了代码的重用性,又增强了程序的结构和可维护性。
1.模块的本质
内部具有一定功能的py文件
2.python模块的历史
初期被其他编程语言的程序员称为‘调包侠’,后期不得不使用python>>>:真相定律
3.python模块的表现形式
3.1 Py文件(py文件也可以称为是模块文件)
3.2 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
3.3 已被编译为共享库或DLL的C或C++扩展(了解)
3.4 使用c编写并链接到python解释器的内置模块(了解)
模块的分类
1.自定义模块
我们自己写的模块文件
2.内置模块
python解释器提供的模块 time
3.第三方模块
别人写的模块文件(python背后真正的大佬)
导入模块的两种句式
强调:
1.搞清楚谁是执行文件,谁是被导入文件
2.以后开发项目的时候py文件的名称一般是纯英文
不会出现含有中文甚至空格
01 模块简介.py 不会出现
test.py 出现
3.导入模块文件不需要填写后缀名
1.import句式
以import aa 为例研究底层原理
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中产生一个模块的名字
4.在执行文件中使用该模块名点的方式使用模块名称空间中所有的名字
"""
在文件01 模块的两种导入模式.py文件中引用aa.py中的功能,需要使用import aa,在首次导入模块中执行文件(01 模块的两种导入模式.py)发生的事有:
1.执行源文件代码
2.产生一个新的名称空间用于存放源文件执行过程中产生的名字
3,在执行文件所在的名称中间得到一个模块名aa,该名字指向新创建的模块名称空间,若要引用模块名称空间中的名字,需要加上模块名aa,如下:
import aa # 导入模块aa
name = 'kiki'
print(aa.name) # 打印引用模块aa中全局变量name的值
aa.func1() # 调用模块aa中func1函数
aa.func2() # 调用模块aa中func2的函数,等于再次调用模块aa中的func1函数
aa.change() # 调用模块aa中change的函数,模块aa的全局变量name='kimi'修改为name='rose'
print(aa.name)
print(name)>>>>:执行文件中的全局变量name
"注意:若想要执行当前文件中的名称空间中存在的name,执行aa.get()操作的都是源文件中的全局变量name"
导入模块后发生的顺序如图

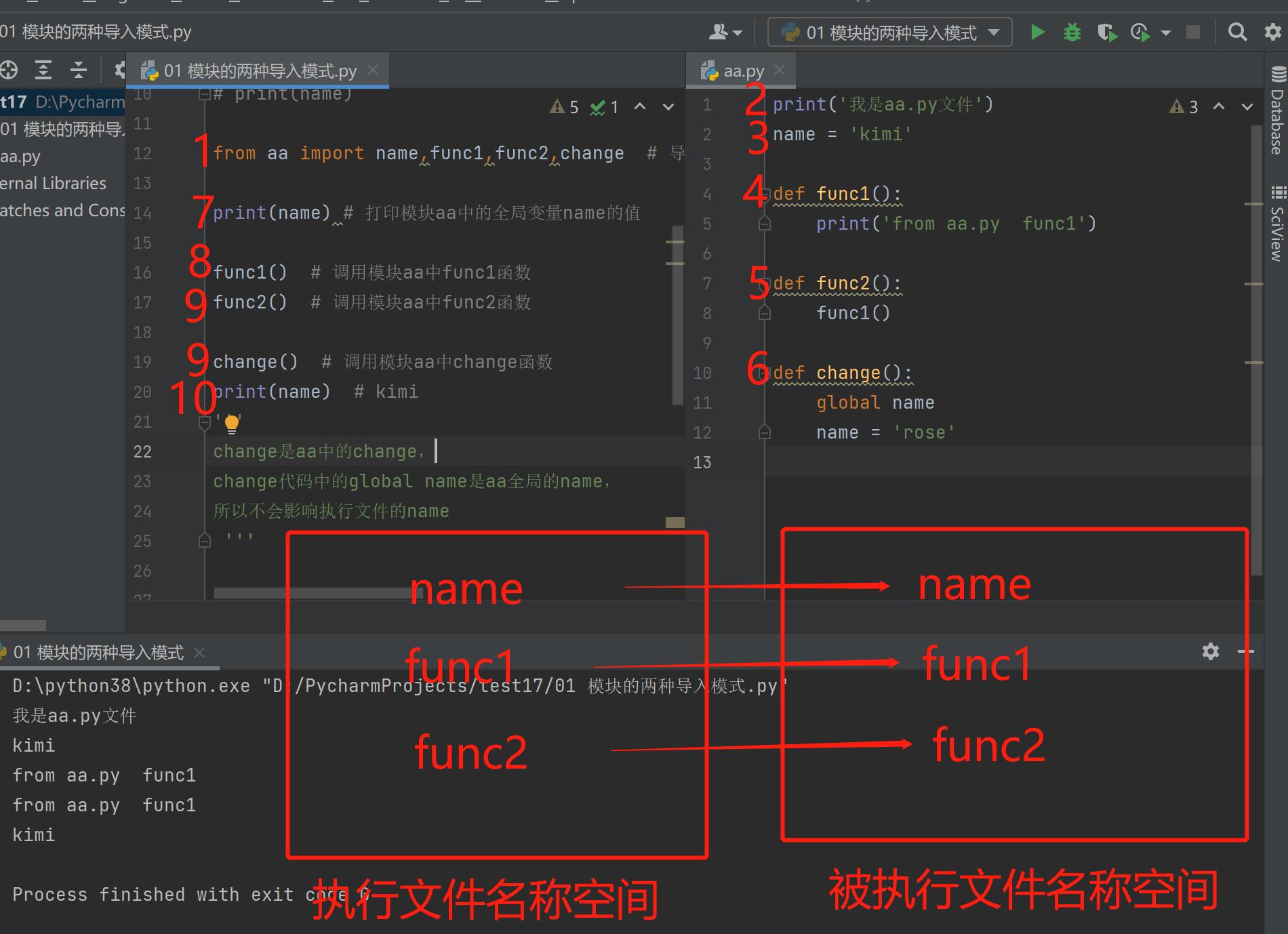
2.from...import...句式
以from...import...name,func1为例研究底层原理
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码将产生对应的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中产生对应的名字绑定模块名称空间中对应的名字
4.在执行文件中直接使用名字就可以访问名称空间中对应的名字
"""
代码实现:
from aa import name,func1,func2,change # 导入模块aa中的全局变量name,函数func1,func2,change
print(name) # 打印模块aa中的全局变量name的值
func1() # 调用模块aa中func1函数
func2() # 调用模块aa中func2函数
change() # 调用模块aa中change函数
print(name) # kimi
'''
change是aa中的change,
change代码中的global name是aa全局的name,
所以不会影响执行文件的name
'''
导入模块后发生的顺序如图
导入模块的句式补充
1.import与from...import....两者优缺点
import句式
由于使用模块名称空间的名字都需要模块点的方式才可以用
所以不会轻易的被执行文件中的名字换掉
但是每次使用模块名称空间中的名字都必须使用模块点才可以
from...import...句式
指名道姓的导入模块名称空间中需要使用的名字,不需要模块点
但是容易跟执行文件的名字冲突(执行文件有name,导入模块也有name)
2.重复导入模块
解释器只会导入一次,后续重复的导入语句并不会执行
eg: import aa # 导入模块aa
import aa
import aa
'只执行导入一次'
3.起别名
import zhongguorenming as zg
from zhongguorenming import zhosngdeineidiedideh as f1
from zhongguorenming import name as n,func1 as f
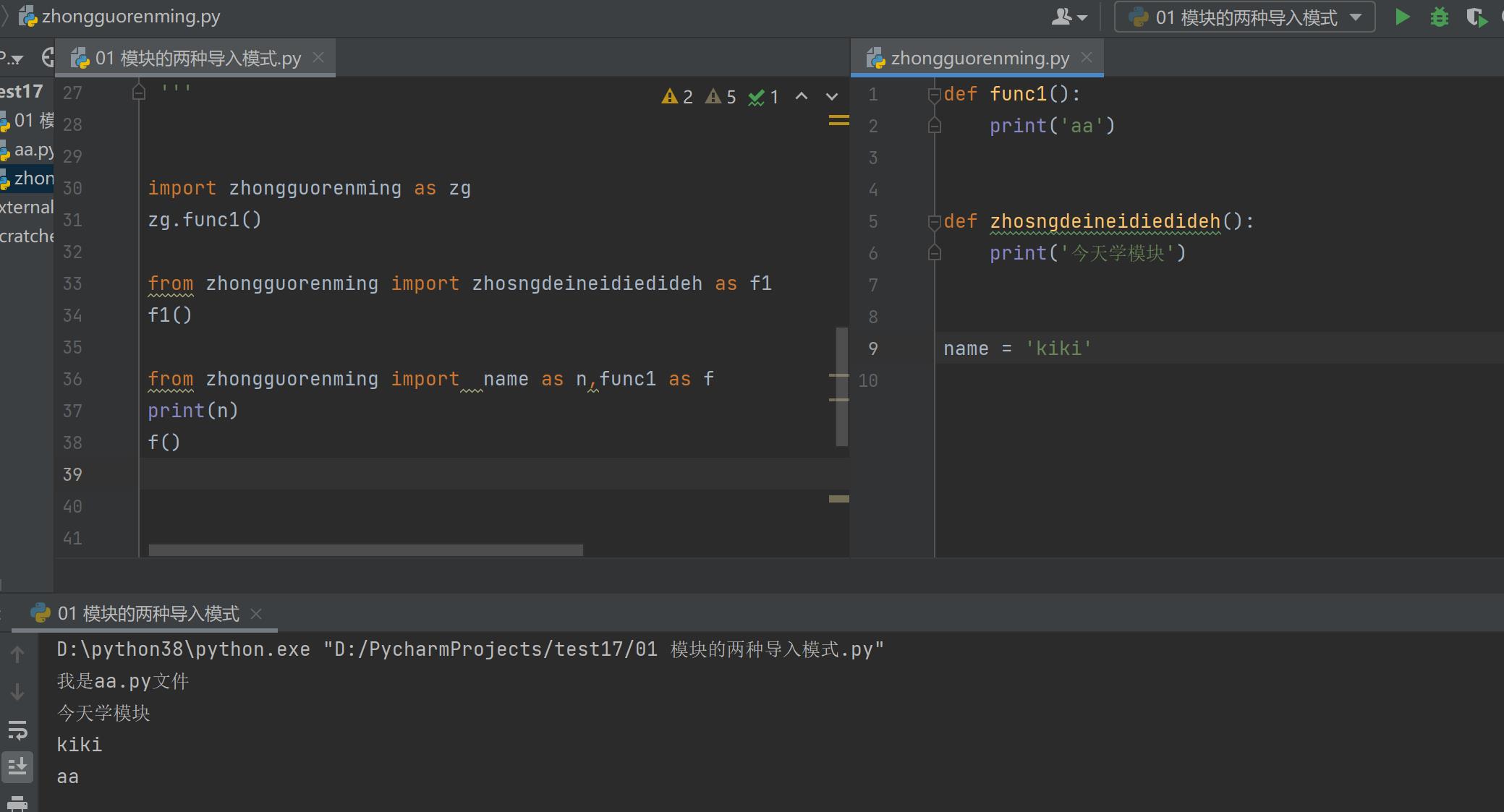
4.涉及到多个模块导入
如果模块相似度不高,推荐使用
import aa
import zhongguorenming
如果模块相似度高,推荐使用
import aa, zhongguorenming
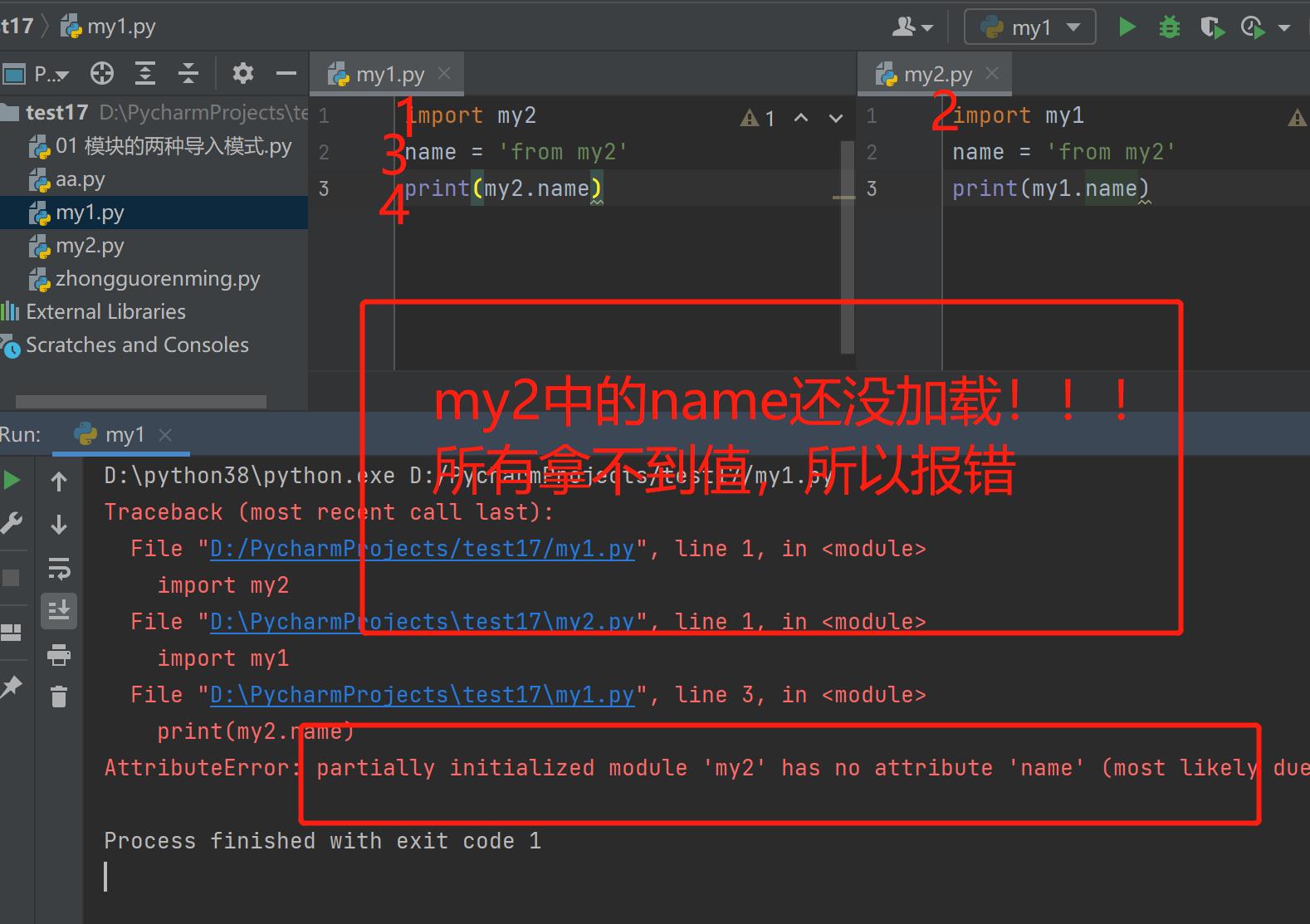
循环导入问题及解决策略
1.循环导入
两个文件之间彼此导入彼此并且相互使用各自名称空间中的名字 极容易报错
2.如何解决循环导入问题
1.确保名字在使用之前就已经准备完毕
name = 'from my2' # 把name的值放在是使用之前的位置
import my1
print(my1.name)
2.我们以后在编写代码的过程中尽可能避免出现循环导入
循环导入错误如图
判断文件类型(name)
所有的py文件都可以直接打印__name__对应的值
当py文件是执行文件的时候__name__对应的值是__main__
eg: print(__name__) # __main__
当py文件是被导入文件的时候__name__对应的值是模块名
eg:import my2 # 执行文件my1 结果是my2
if __name__=='__main__': # 快捷键(敲main回车就会出来)
print('哈哈哈,我是执行文件 我可以运行这里的子代码')
上述脚本可以用来区分所在py文件内python代码的执行
使用场景
1.模块开发阶段
2.项目启动文件
"""
执行文件里面:
from a import * # *默认是将模块名称空间中所有的名字导入
被导入文件里面:
__all__ = ['名字1','名字2'] 针对*可以限制拿到的名字
不能拿模块中没有的名字
"""
模块的查找顺序
1.内存
import aaa
import time
time.sleep(5)
print(aaa.name)
aaa.func()
'先从内存中中,即使加载后再删除了aaa文件,本次加载还能加载出来name,但是第二次运行之后就会报错,因为此时的aaa文件已经被删除了'
2.内置
import time
print(time) # <module 'time' (built-in)>
print(time.name) # module 'time' has no attribute 'name' 内置time没有name的
'以后在自定义模块的时候尽量不要与内置模块名冲突'
3.执行文件所在的sys.path(系统环境)
一定要以执行文件为准!!!
我们可以将模块所在的路径也添加到执行文件的sys.path中即可
# import ddd
# print(ddd.name) # 报错 当ddd不属于当前执行文件的同级文件时需要添加绝对路径进去
import sys
print(sys.path) # 列表 一般只看第一个路径
sys.path.append(r'D:\PycharmProjects\test17\myname')
import ddd
print(ddd.name) # kiki
绝对导入和相对导入
""" 再次强调:
一定要分清谁是执行文件!!!
模块的导入全部以执行文件为准
"""
绝对导入
from myname import ddd
print(ddd.name) # kiki
from aaaa.bbbb.cccc.dddd import name # 可以精确到变量名
print(name) # 我是dddd文件
from aaaa.bbbb.cccc import dddd # 也可以精确到其模块名
print(dddd.name) # 我是dddd文件
ps:套路就是按照项目根目录一层层往下查找
相对导入
. 在路径中表示当前目录
.. 在路径中表示上一层目录
..\.. 在路径中表示上上一层目录
不再依据执行文件所在的sys.path而是以模块自身路径为准
from.import b
相对导入只能基于模块文件中,不能在执行文件中使用
""" 相对导入使用频率较低,一般用绝对导入即可,结构更加清晰 """
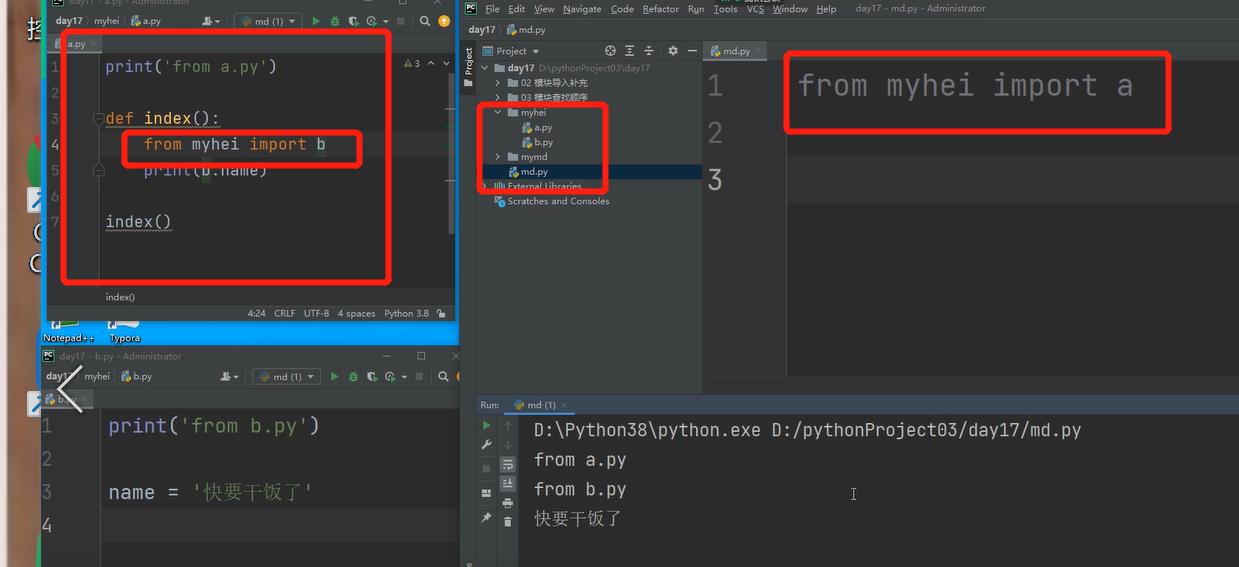
当a 、b和 执行文件是不同路径下时,from myhei import a我们只能拿到a 名字,执行到import b会报错,报错是没有b的名字。这时候想要引入b文件时,我们需要在a文件导入(from myhei import b)b文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号