垃圾回收机制及流程控制图
垃圾回收机制
垃圾回收机制
引入
解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,但内存的容量是有限的,当变量值没有用了(垃圾)就应该将其占用的内存给回收掉。变量名是直接访问到变量值的,当一个变量名对应的变量值没有用了,就应该被当成垃圾给回收掉,,Cpython的解释器提供了自动的垃圾收回机制。
程序在运行的时候会申请大量的内存空间,防止程序崩溃,及时清理一些无用的内存空间是一件重要和繁琐的事情。
垃圾回收机制(GC):python解释器自带的一种专门回收不可用的变量值所占的内存空间。
垃圾回收机制原理分析
python的垃圾回收机制主要是运用了“引用计数(reference counting)”来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除(mark and sweep)"解决容器对象可能产生的循环引用的问题,并且通过“分代回收(generation collection)"以空间换取时间的方式来进一步提高来垃圾回收的效率。
-
引用计数
引用计数:变量值跟变量名关联的次数
name = 'kiki' 变量值'kiki'被关联了一个变量名name,被称为引用计数为1 name1 = name 变量值'kiki'被关联了两个变量名name,name1,所以变量值'kiki'的引用计数为2 del name 变量值'kiki'与name解除关联关系,此时变量值'kiki'的引用计数为1 name1 = 18 变量值'kiki'与name1解除关联关系,此时变量值'kiki'的引用计数为0,变量值18与name1 关联,变量值18的引用计数为1 del name1 变量值18与name1解除关联关系,此时变量值18的引用计数为0 """ 当数据值身上的引用计数为0的时候,就会被垃圾回收机制当垃圾回收 当数据值身上的引用计数不为0的时候,永远不会被垃圾回收机制回收""" -
标记清除
容器对象(比如:list, set, dict, class,instance)都可以包含对其它对象的引用,所以都有可能产生循环引用。而标记清除就是为了解决循环引用的问题
主要针对循环引用问题 L1 = [11, 22] # 引用计数为1 L2 = [33, 44] # 引用计数为1 L1.append(L2) # L1=[11, 22, 33, 44] 引用计数为2 L1.append(L1) # L2= [33, 44, 11, 22] 引用计数为2 del L1 # 断开变量名L1与列表的绑定关系 引用计数为1 del L2 # 断开变量名L2与列表的绑定关系 引用计数为1 注:当内存占用达到临界值的时候,程序会自动停止,然后扫描程序中所有的数据,并给只产生循环引用的数据打赏标记,然后一次性清除
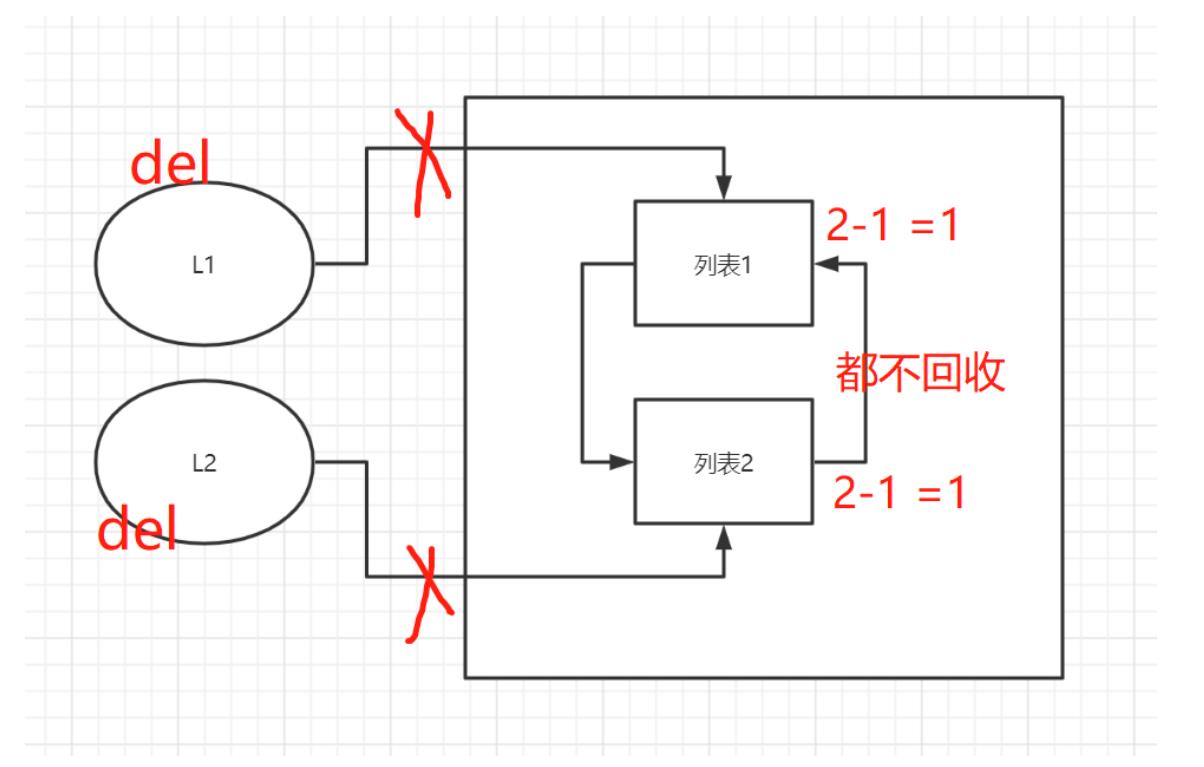
-
分代回收
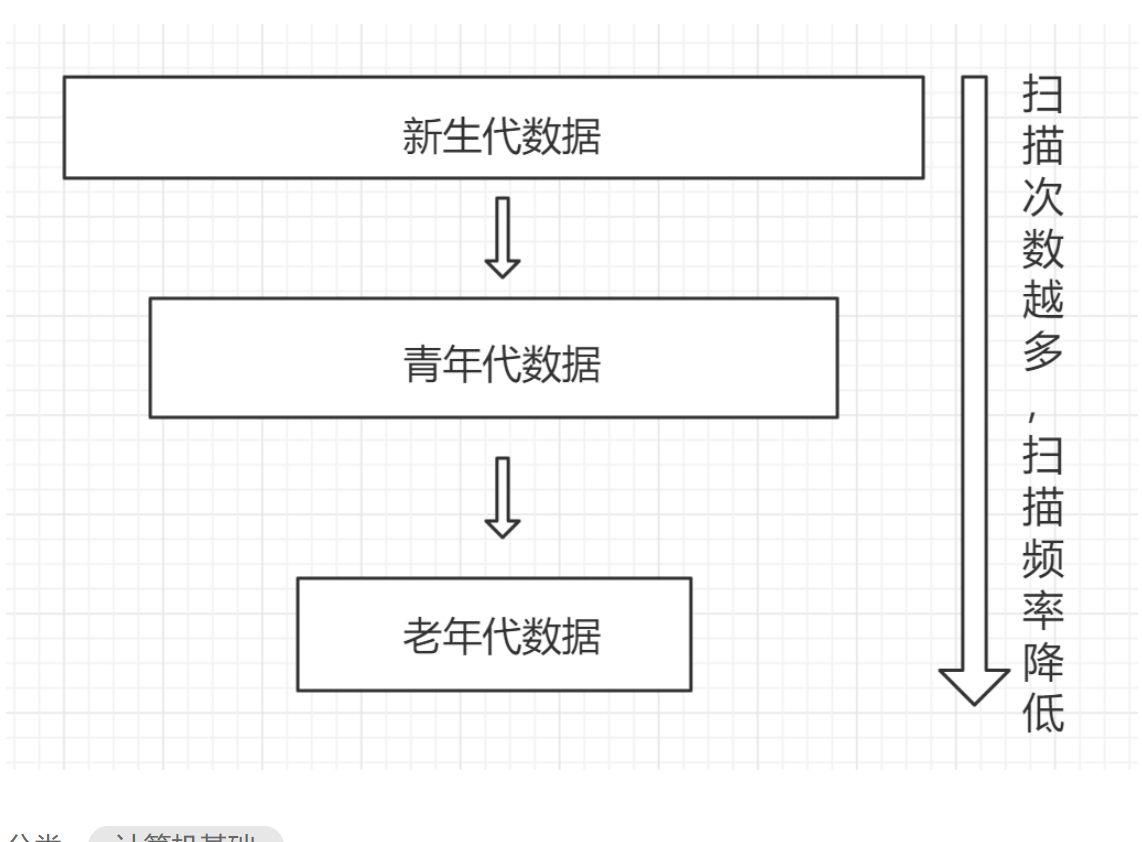
基于引用计数的回收机制,每次回收内存,都需要遍历所有对象的引用计数,过程非常繁琐,正好分代回收是”空间换时间的策略“,可以提高回收效率。
垃圾回收即使的频繁运行也会损耗各项资源
新生代 青春代 老年代
流程控制
流程控制理论
流程控制即控制流程,具体指的是控制流程的执行流程,而程序的执行流程分为三种结构:顺序结构、分支结构(if)、循环结构(while、for),在代码里,一般会三种结构混用。
流程控制必备知识
-
python 中使用代码的缩进来表示代码的从属关系
从属关系:缩进的代码(子代码)是否执行取决于上面没有缩进的
-
并不是所有的代码都可以拥有缩进的代码(子代码)
if 关键字 while for
-
如果有多行子代码属于同一个父代码,那么这些子代码需要保证相同的缩进量
-
python中针对缩进量没有具体的要求,但是推荐使用四个空格(Windows中的tab键)
-
当某一行代码需要编写子代码的时候,那么这一行代码的结尾肯定需要冒号(:)
-
相同缩进量的代码彼此之间平起平坐,按照顺序结构依次执行
流程控制结构
顺序结构
顺序结构:之前我们写的代码都是顺序结构
eg: name = 'kevin'
name1 = name
name2 = name1
# 链式赋值
print(name2) #name2= name1 = name='kevin'
分支结构
分支结构:根据条件判断的真假去执行不同分支对应的子代码
if分支结构
if 条件:
条件成立后执行的代码块
eg:
username = input('username>>>:')
if username == 'kiki':
print('Kiki同学,今天又是美好的一天')
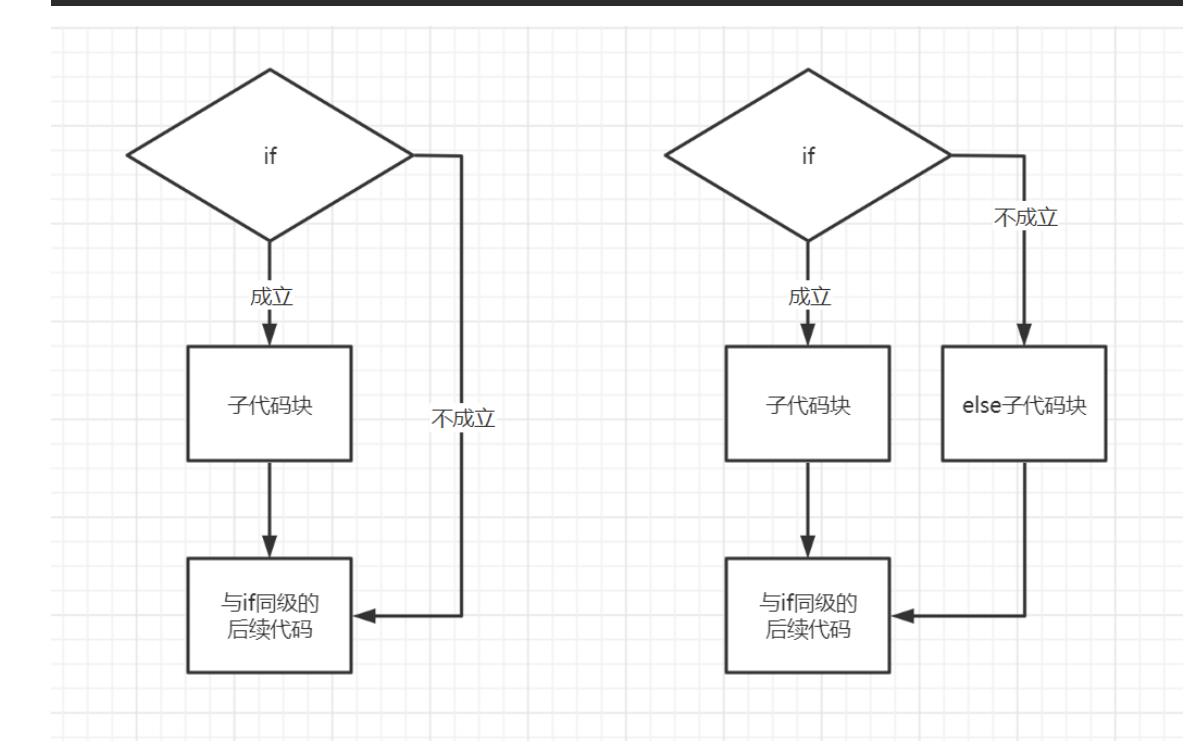
if...else...分支结构
if条件:
条件成立之后执行的子代码
else:
条件不成立执行的代码块
eg:
username = input('username>>>:')
if username == 'kiki':
print('Kiki同学,今天又是美好的一天')
else:
print('哎呀,你猜错了')
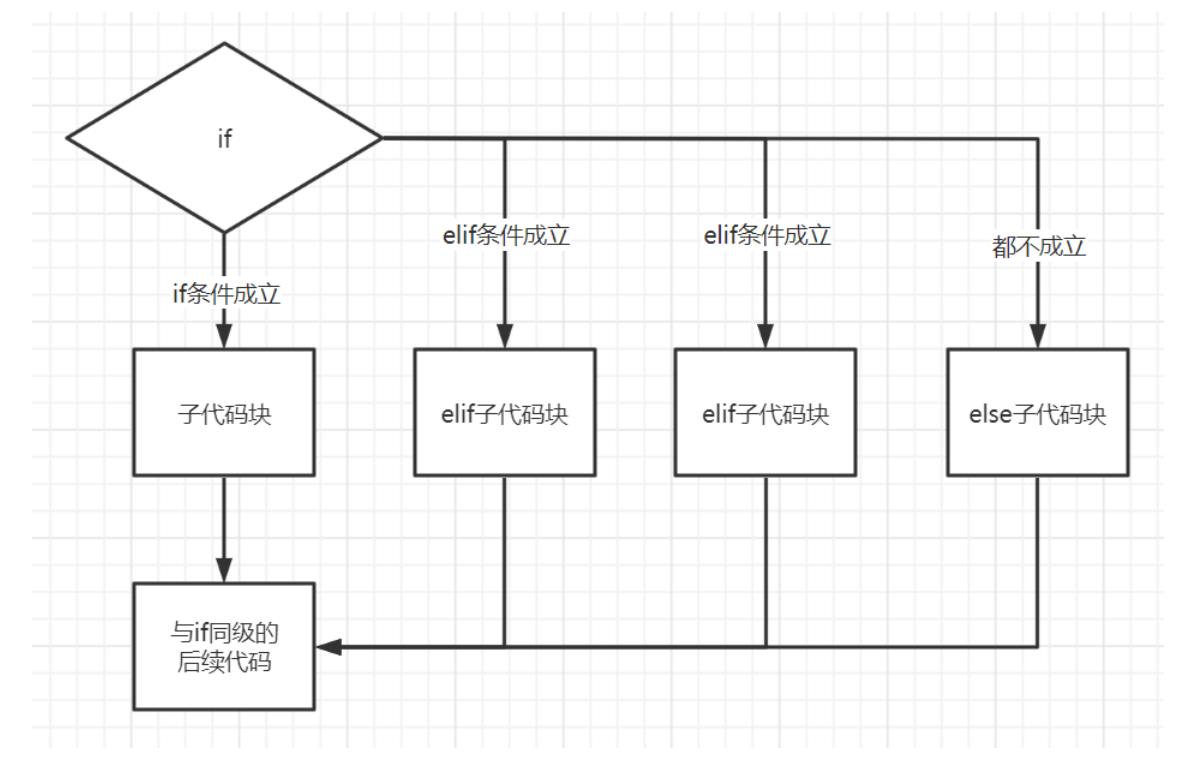
if...elif...else分支结构
if 条件1:
条件1成立之后执行的子代码
elif 条件2:
条件1不成立,条件2成立执行的子代码
elif 条件3:
条件1和条件2都不成立,条件3成立执行的子代码
.....
elif 条件n:
条件n-1之前的都不成立,执行条件n的子代码
else:
上述条件都不成立,执行的子代码
注意:中间的elif条件可以写多个,上述代码只会走有一个子代码
eg:
# if...elif...else 分支
"""期末了,老师对学生的成绩进行一评分,成绩为90-100为优秀,成绩为80-90为良好,成绩为70-80为一般,成绩为60-70为及格,60以下的为不及格,用分支结构进行以下统计"""
stu_score = input('请输入学生成绩:')
"""input输出的90是字符串
如果不进行数据类型变形,输出的结果就是
TypeError: '>' not supported between instances of 'str' and 'int'"""
stu_score =int(stu_score) # 将字符串改为整数
if stu_score >90:
print('优秀')
elif stu_score >80:
print('良好')
elif stu_score >70:
print('一般')
elif stu_score >60:
print('及格')
else:
print('不及格')
if的嵌套使用(难点)
# if 嵌套使用
age = 24
height=183
weight=135
is_handsome = True
is_success = True
name ='kiki'
if name == 'kiki':
print('发现目标')
if age >= 20 and age <=27 and height ==183 and weight == 135 and is_handsome:
print('成功找到人')
if is_success :
print('去蹦极')
else:
print('回家')
else:
print('没有成功找到人')
else:
print('目标失败')
循环结构
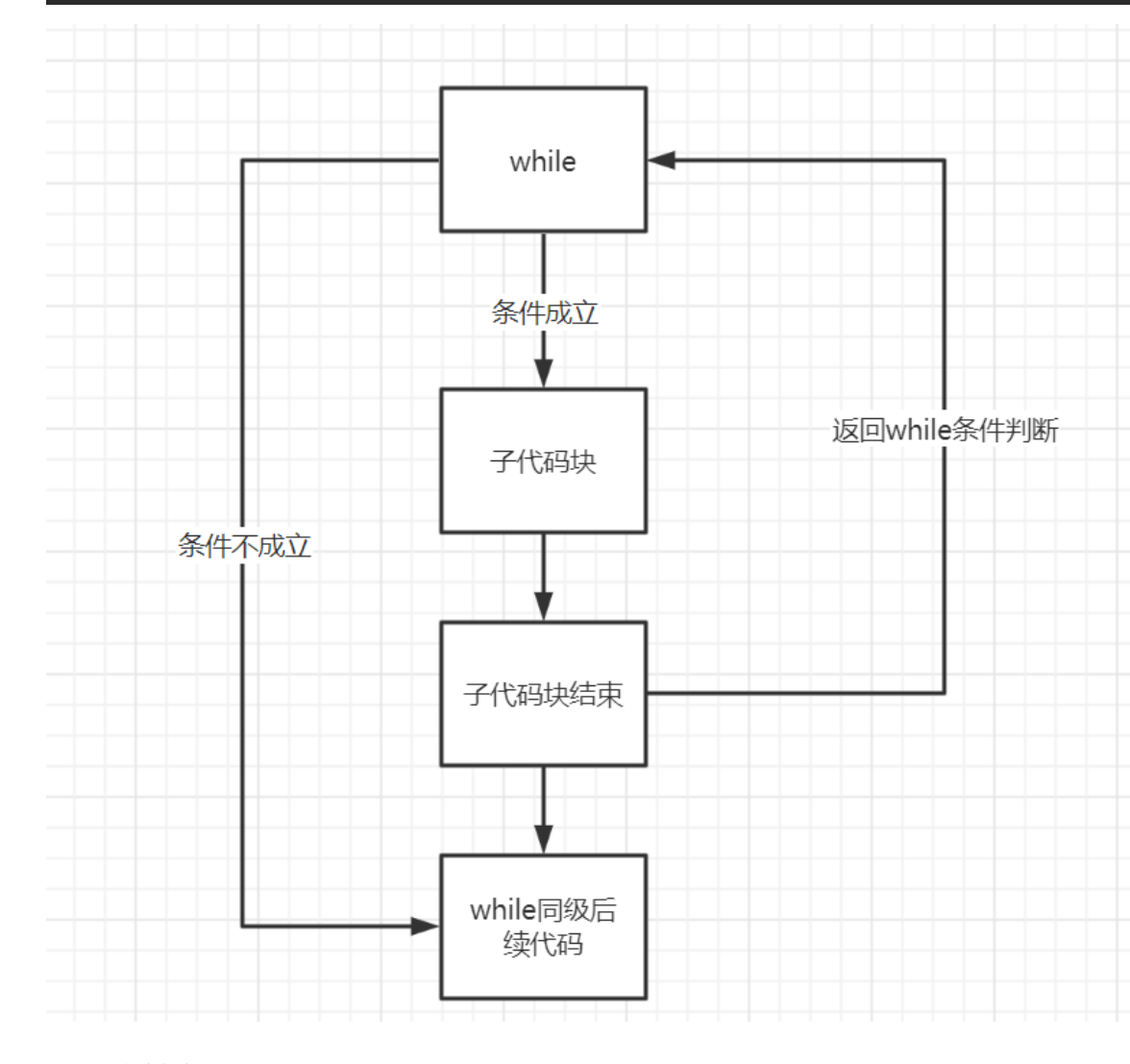
循环结构:重复执行的某段代码块
人类某些时候需要重复做某件事情,所以程序中必须有相应的机制来控制计算机具备人的这种循环做事的能力
while循环
while 条件:
代码1
代码2
代码3
.....
"""while的运行步骤:
1.如果条件为真,那么依次执行:代码1、代码2、代码3、...
2.执行完毕之后再次判断条件,如果条件为True则再次执行代码1、代码2、代码3
3.......,如果条件为False,则循环终止"""
eg;打印五个hello world
count = 1
while count < 5:
print('hello world')
count += 1 # count =count +1
print('吃水果')
# 循环打印1-10 遇到6直接结束循环
# 循环打印1-10 遇到4跳过
count = 1
while count <= 10:
# if count ==6:
# break #直接结束循环体
if count ==6:
count += 1
continue
print(count)
count += 1 # count =count +1
print('吃水果')
break # 强行结束循环体
while 循环体代码一旦执行到break会直接结束循环
continue # 直接跳到条件判断处
while 循环体代码一旦执行到continue 会结束本次循环,开始下一次循环
while 条件:
循环体代码
else:
循环体代码没有被强制结束的情况下,执行完毕就会执行else子代码
死循环、嵌套和全局观
-
死循环
真正的死循环是一旦执行,CPU功能消耗就会急速上升,直到系统采取紧急措施,尽量不要让CPU长时间不间断运算
死循环案例
eg1: while True: print('hello world') eg2: count = 10 while True: count *=2 # 计算机一直在运算,导致CPU一直急速上升 -
嵌套及全局观
1.当一个循环里有几个break时,每个break只能结束它所在的那一层循环里
2.如果想一次性结束几个while的嵌套,就应该写几个break
3.如果不想反复写break,可以使用全局标志位
eg1: while True: username = input('username>>>:') password = input('password>>>:') if username == 'kiki' and password == '123': while True: cmd = input('请输入你的指令>>>:') if cmd == 'q': break print('正在执行你的指令:%s' %cmd) break else: print('用户名或者密码错误') eg2:再加一套 while True: print('嘿嘿嘿') while True: username = input('username>>>:') password = input('password>>>:') if username == 'kiki' and password == '123': while True: cmd = input('请输入你的指令>>>:') if cmd == 'q': break print('正在执行你的指令:%s' %cmd) break else: print('用户名或者密码错误') break eg3: # 全局标志位 is_happy = True while is_happy: username = input('username>>>:') password = input('password>>>:') if username == 'kiki' and password == '123': while is_happy: cmd = input('请输入你的指令>>>:') if cmd == 'q': is_happy = False print('正在执行你的指令:%s' %cmd) else: print('用户名或者密码错误') 图如下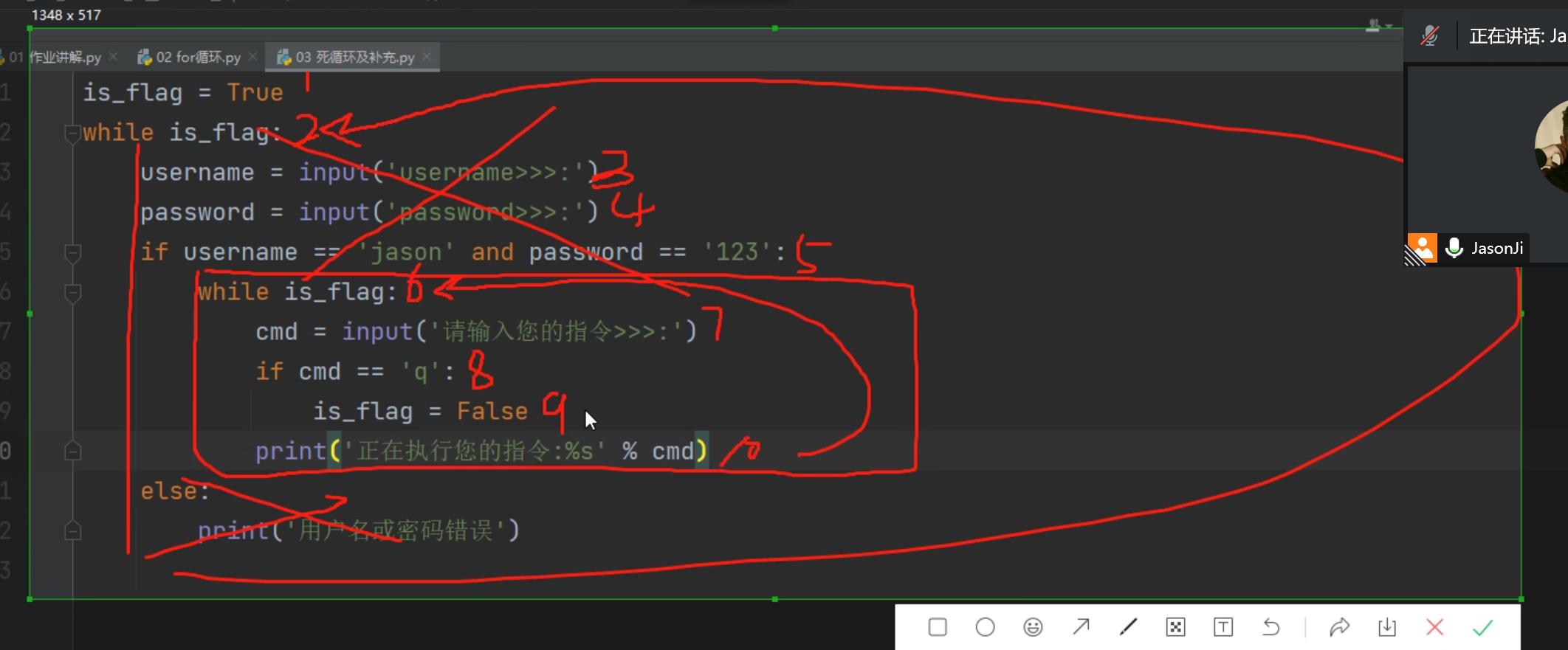
for循环
循环结构的第一种循环方式是for,for循环可以做的事情while循环都可以实现,for循环取值是遍历所有的数据值,使用起来比while更简单
for循环语法
for 变量名 in 待遍历的数据(可迭代的对象):#目前可迭代对象是字符串、列表、字典、元组、集合就可,后面会专门讲解的
for 循环体代码
eg:
for item in [11, 33, 44]: # for 从遍历列表11开始,遍历11,再遍历33,到44
print(item)
运行的结果:
11
22
33
注意点:
第一种情况是“字符串“
item = 'hello world'
for i in item:
print(i) # 打印的结果是:h e l l o w o r l d 单个单个字符,空格也算一个字符
第一种情况是“字典”
d = {'name':'kiki',
'passworld':123}
for i in d:
print(i) # 只有键参与遍历 打印结果:name password
for 循环语法结构中的变量名如何命令
1.见名知意
2.如果遍历出来的数据值没有具体的含义,可以使用常用
i j k item v
for循环体代码中如果执行到break也会直接结束整个for循环
for循环体代码中如果执行到continue也会结束当前循环直接开始下一次循环
for 变量名 in 待遍历的数据:
for循环体代码
else:
for循环体代码没有被break强制结束的情况下运行完毕之后 运行
for 循环应用案例
eg: while循环与for循环的区别
1.用while遍历
name_list = ['kiki', 'kecin', 'toy', 'jason']
#用while 遍历列表
# 循环打印出列表中每一个数据值(while 索引取值>>>:超出范围会报错)
count = 0 # count是索引
while count<4: #索引不能超过3
print(name_list[count])
count += 1
2.用for遍历
for i in name_list:
print(i)
range方法
rang 可以简单的理解为是帮我们产生一个内部含有多个数字的数据
for i in range(100): # 起始位置为0,终止位置为100,相当于【0,100)
print(i)
for j in range(10,20): # 第一个为起始位置,第二个个终止位置
print(j)
for k in range(1,20,2): # 第三个为等差值,默认不写1
print(k) # 打印出来是1-19的奇数
range在python2 和python3的区别
在python2中
range()
直接产生一个列表 内部含有多个数值
xrange()
其实就是python3里面的range
在python3中
range()
类似于一个工厂 不会占用太多的内存空间 要就生产
图如下
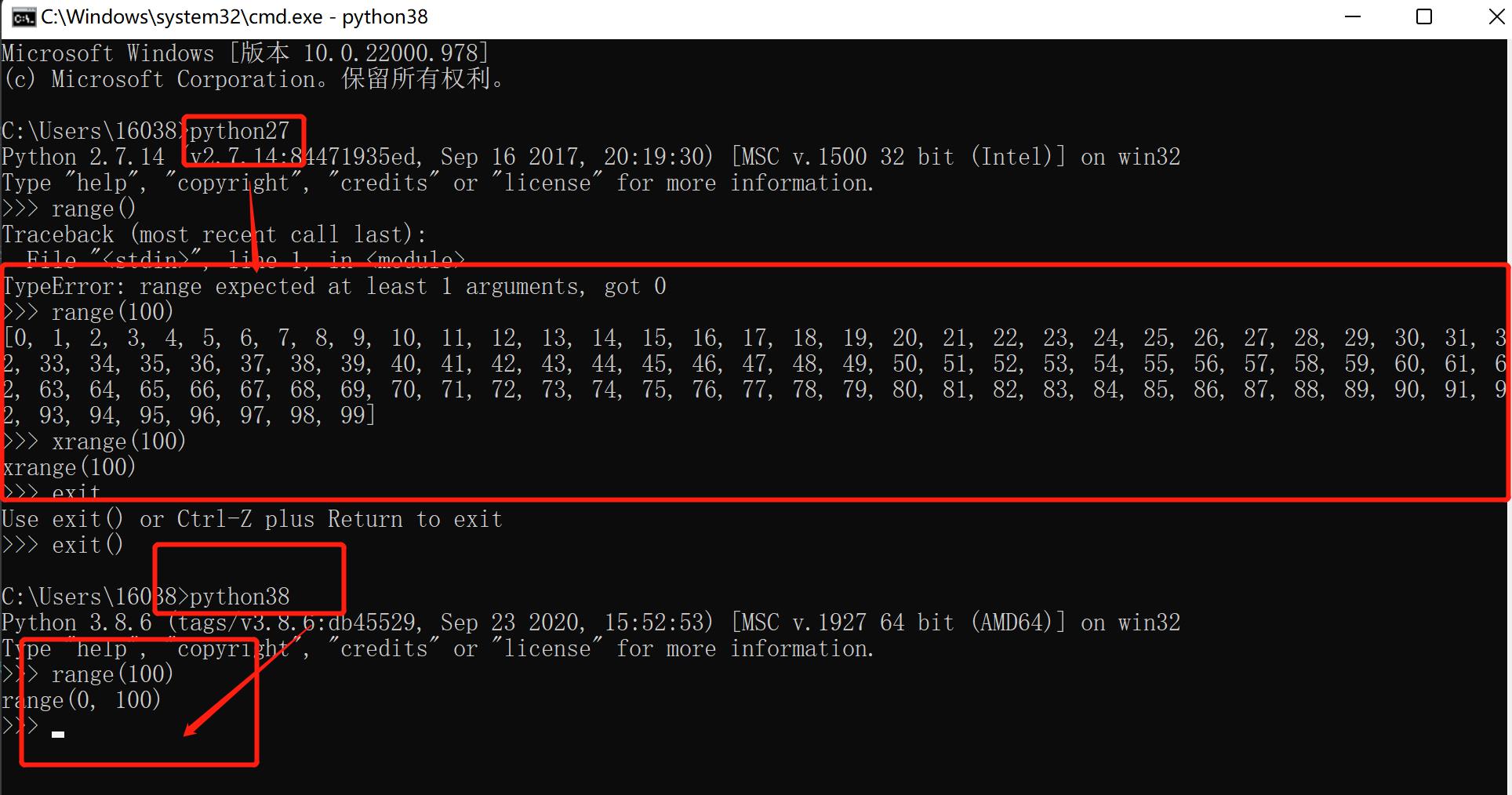
range实战案例
网络爬虫
网络爬虫
从网路上爬取数据的手段
项目需求
爬取所有页面的数据(博客园)
找寻规律
https://www.cnblogs.com/
https://www.cnblogs.com/#p2
https://www.cnblogs.com/#p3
https://www.cnblogs.com/#p4
大胆猜测:第一页是 https://www.cnblogs.com/#p1
编写代码产生博客园文章前两百页的网址
1.第一种方式
for i in range(1,201) :
print('https://www.cnblogs.com/#p%s' %i)
2.第二种方式
# 1.先定义网址的模板
base_url = 'https://www.cnblogs.com/#p%s'
for i in range(1, 201):
print(base_url % i)
# 通过代码朝上述的网址发送请求获取页面数据 通过
'''
分页的规律 不同的网址有所区别
1.在网址里面有规律
2.内部js文件动态加载(未解)
'''
作业
if分支练习题
"""
1.根据用户输入内容打印其权限
jason --> 超级管理员
tom --> 普通管理员
jack,rain --> 业务主管
其他 --> 普通用户
"""
# jason = '超级管理员'
# tom = '普通管理员'
# jack = rain = '业务主管'
# username = input('请输入用户的名字:')
# if username == 'jason':
# print(jason)
# elif username == 'tom' :
# print(tom)
# elif username =='jack' or username=='rain' :
# print(jack)
# else :
# print('普通用户')
#
"""2.编写用户登录程序
要求:有用户黑名单 如果用户名在黑名单内 则拒绝登录
eg:black_user_list = ['jason','kevin','tony']
如果用户名是黑名单以外的用户则允许登录(判断用户名和密码>>>:自定义)
eg: oscar 123'
"""
# L1 = ['jason', 'kevin', 'tony']
# L2 = {'username':'kiki',
# 'password':'123456'}
# name = input('请输入您的用户名>>>:')
# password1 = input('请输入密码>>>:')
# if name in L1 :
# print('你登陆的用户名有误,请重新输入!')
# elif name == L2['username'] and password1 == L2['password']:
# print('成功登录')
# name='kiki'
# password1 ='1234'
# count = 1
# while count < 4:
# username = input('请输入用户名>>>:')
# password = input('请输入密码>>>:')
# if username == name and password== password1 :
# print('成功登录')
# break
#
# else:
# print('请重新输入')
# count += 1
'''4.猜年龄的游戏
假设用户的真实年龄是18 编写一个猜年龄的游戏 获取用户猜测的年龄
基本要求:可以无限制猜测 每次猜错给出提示(猜大了 猜小了) 猜对则结束程序
拔高练习:每次猜测只有三次机会 一旦用完则提示用户是否继续尝试 用户通过输入n或者y来表示是否继续尝试
如果是y则继续给用户三次猜测机会 否则结束程序
'''
# 基本要求
# age = input('请输入用户的真是年龄>>>:')
# age = int(age)
# if age > 18 :
# print('猜大了')
# elif age< 18 :
# print('猜小了')
# else:
# print('猜对了')
完整的步骤
# 1.先定义用户的真实年龄
real_age = 18
# 8.定义计数器
count_num = 1
# 6.添加循环结构
while True:
# 10.判断当前尝试的次数
if count_num == 4:
choice = input('您已经尝试了三次 是否继续尝试(n/y)>>>:')
# 11.判断用户输入的选择
if choice == 'y':
# 12.重置计数器
count_num = 1
else:
print('下次再来玩哟')
break
# 2.获取用户猜测的年龄
guess_age = input('你猜一猜我的年龄 好不好呀>>>:')
# 3.由于一会儿需要比较大小 所以要将用户输入的字符串年龄转成整型的年龄
guess_age = int(guess_age) # 有小bug 暂时不考虑
# 4.判断年龄是否猜测正确
if guess_age > real_age:
print('你这小伙子 真讨厌 人家有那么大吗')
# 猜测错了 计时器加一
count_num += 1
elif guess_age < real_age:
print('哎呀 你真讨厌 人家也没那么小啦')
# 猜测错了 计时器加一
count_num += 1
else:
print('你真棒 猜对了 嘿嘿嘿')
# 7.猜对了 直接结束循环
break
循环分支练习题
1.计算1-100所有的数之和
# 1.for 来遍历
# 2.定义初始的值为0
sum=0
for i in range(1,101):
sum +=i #遍历的值赋值给sum
print(sum) #最终输出总值
# 2.判断列表中数字2出现的次数
# l1 = [11,2,3,2,2,1,2,1,2,3,2,3,2,3,4,3,2,3,2,2,2,2,3,2]
方法一:
l1 = [11, 2, 3, 2, 2, 1, 2, 1, 2, 3, 2, 3, 2, 3, 4, 3, 2, 3, 2, 2, 2, 2, 3, 2]
# 1.先定义一个记录数字2出现次数的计时器
count = 0
# 2.循环获取列表中的每一个数据值判断是不是数字2
for i in l1:
# 3.如果i绑定的数据值为2,则让计时器加1
if i ==2:
count +=1
# 4.等待for循环运行结束,打印计时器
print(count)
方法二:
print(l1.count(2))
# 3.编写代码自动生成所有页网址(注意总共多少页)
# https://movie.douban.com/top250
base_wet = 'https://movie.douban.com/top250?start=%s&filter='
for i in range(0,250,25):
print(base_wet % i)
4.编写代码打印出下列图形(ps:for循环嵌套)
'''
*****
*****
*****
*****
'''
for i in range(4): # 0 1 2 3 4次 4行
for k in range(5): # 0 1 2 3 4 5次 5列
print('*',end='')
print('') # 内存循环结束 换行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号