vue 的模板编译—ast(抽象语法树) 详解与实现
首先AST是什么?
在计算机科学中,抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。
我们可以理解为:把 template(模板)解析成一个对象,该对象是包含这个模板所以信息的一种数据,而这种数据浏览器是不支持的,为Vue后面的处理template提供基础数据。
这里我模拟Vue去实现把template解析成ast,代码已经分享到 https://github.com/zhangKunUserGit/vue-ast,具体逻辑都用文字进行了描述,请大家下载运行。
基础
(1)了解正则表达式,熟悉match,test, exec 等等JavaScript匹配方法;
(2)了解JavaScript柯里化;
获取模板
import { compileToFunctions } from './compileToFunctions';
// Vue 对象
function Vue(options) {
// 获取模板
const selected = document.querySelector(options.el);
this.$mount(selected);
}
// mount 模板
Vue.prototype.$mount = function (el) {
const html = el.outerHTML;
compileToFunctions(html, {});
};
export default Vue;
这里我仅仅使用querySelector的方式获取模板,其他的方式没有处理。因为我们的重点是如何解析模板。
JavaScript 柯里化
import { createCompiler } from "./createCompiler";
const { compileToFunctions } = createCompiler({});
export { compileToFunctions }
import { parse } from "./parse";
function createCompileToFunctionFn(compile) {
return function compileToFunctions(template, options) {
const compiled = compile(template, options)
}
}
function createCompilerCreator(baseCompile) {
return function createCompiler() {
function compile(template, options) {
const compiled = baseCompile(template, options)
}
return {
compile,
compileToFunctions: createCompileToFunctionFn(compile)
}
}
}
// js柯里化是逐步传参,逐步缩小函数的适用范围,逐步求解的过程。
export const createCompiler = createCompilerCreator(function(template, options) {
console.log('这是要处理的template字符串 -->', template);
const ast = parse(template.trim(), options);
console.log('这是处理后的ast(抽象语法树)字符串 -->', ast);
});
这里我按照Vue源码逻辑书写的,柯里化形式的代码看了容易让人晕,但是它也有它的好处,在这里体现的淋漓尽致,通过柯里化可以逐步传参,逐步求解。现在忽略此处,直接看createCompilerCreator()里面的函数就可以了。
解析
我们知道HTML模板是有标签、文本、注释组成的,这里不考虑注释,而标签又分为单元素标签(如:img,br 等)和普通标签(如: div, table 等)。文本又分为带有绑定的文本(含有{{}} 双大括号)和普通文本(不含有{{}} 双大括号)。
所以解析HTML最少要分两个方法,一个处理标签,一个处理文本,但是无论单元素还是普通标签都有开始和闭合,只是形式不一样罢了。所以把解析HTML 可以分成start(处理开始标签)、end(处理结束标签)、char(处理文本):
export function parse(template, options) { // 暂存没有闭合的标签元素基本信息, 当找到闭合标签后清除存在于stack里面的元素 const stack = []; // 这里就是解析后的最终数据,这里主要应用了引用类型的特性,最终使root滚雪球一样,保存标签的所有信息 let root; // 当前需要处理的元素父级元素 let currentParent; parseHTML(template, { start(tag, attrs, unary) {}, end() {}, chars(text) {}, }); // 把解析后返回出去,这个就是ast(抽象语法树) return root; }
此时,我们调用了parseHTML函数,看看它干了什么:
export function parseHTML(html, options) { const stack = []; let index = 0; let last, lastTag; // 循环html字符串 while (html) { last = html; // 处理非script,style,textarea的元素 if(!lastTag || !isPlainTextElement(lastTag)) { let textEnd = html.indexOf('<'); if (textEnd === 0) { // 结束标签 const endTagMatch = html.match(endTag); if (endTagMatch) { const curIndex = index; advance(endTagMatch[0].length); parseEndTag(endTagMatch[1], curIndex, index); continue; } // 开始标签 const startTagMatch = parseStartTag(); if (startTagMatch) { handleStartTag(startTagMatch); continue; } } let text; // 判断 '<' 首次出现的位置,如果大于等于0,截取这段,赋值给text, 并删除这段字符串 // 这里有可能是空文本,如这种 ' '情况, 他将会在chars里面处理 if (textEnd >= 0) { text = html.substring(0, textEnd); advance(textEnd); } else { text = html; html = ''; } // 处理文本标签 if (text) { options.chars(text); } } else { // 处理script,style,textarea的元素, // 这里我们只处理textarea元素, 其他的两种Vue 会警告,不提倡这么写 let endTagLength = 0; const stackedTag = lastTag.toLowerCase(); // 缓存匹配textarea 的正则表达式 const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i')); // 清除匹配项,处理text const rest = html.replace(reStackedTag, function(all, text, endTag) { endTagLength = endTag.length; options.chars(text); return '' }); index += html.length - rest.length; html = rest; parseEndTag(stackedTag, index - endTagLength, index); } } }
我们第一眼看到的就是那个蓝色的while循环。它在那儿默默无闻的循环,直到html为空。在循环体中,用正则判断html字符串是开始标签、结束标签或文本标签,并分别进行处理。
开始标签
/** * 处理解析后的属性,重新分割并保存到attrs数组中 * @param match */ function handleStartTag(match) { const tagName = match.tagName; const unary = isUnaryTag(tagName) || !!match.unarySlash; const l = match.attrs.length; const attrs = new Array(l); for (let i = 0; i < l; i += 1) { const args = match.attrs[i]; attrs[i] = { name:args[1], // 属性名 value: args[3] || args[4] || args[5] || '' // 属性值 }; } // 非单元素 if (!unary) { // 因为我们的parse必定是深度优先遍历, // 所以我们可以用一个stack来保存还没闭合的标签的父子关系, // 并且标签结束时一个个pop出来就可以了 stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs, }); // 缓存这次的开始标签 lastTag = tagName; } options.start(tagName, attrs, unary, match.start, match.end); } /** * 匹配到元素的名字和属性,保存到match对象中并返回 * @returns {{tagName: *, attrs: Array, start: number}} */ function parseStartTag() { const start = html.match(startTagOpen); if (start) { // 定义解析开始标签的存储格式 const match = { tagName: start[1], // 标签名 attrs: [], // 属性 start: index, // 标签的开始位置 }; // 删除匹配到的字符串 advance(start[0].length); // 没有匹配到结束 '>' ,但匹配到了属性 let end, attr; while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) { advance(attr[0].length); // 把元素属性都取出,并添加到attrs中 match.attrs.push(attr); } if (end) { match.unarySlash = end[1]; advance(end[0].length); // start 到 end 这段长度就是这次执行,所处理的字符串长度 match.end = index; return match; } } }
具体逻辑我已经写到代码中了,其中应用了大量的正则和循环,当匹配到后就调用advance() 删除匹配的字符串更新html。
结束标签
/** * 解析关闭标签, * 查找我们之前保存到stack栈中的元素, * 如果找到了,也就代表这个标签的开始和结束都已经找到了,此时stack中保存的也就需要删除(pop)了 * 并且缓存最近的标签lastTag * @param tagName * @param start * @param end */ function parseEndTag(tagName, start, end) { const lowerCasedTag = tagName && tagName.toLowerCase(); let pos = 0; if (lowerCasedTag) { for (pos = stack.length -1; pos >= 0; pos -= 1) { if (stack[pos].lowerCasedTag === lowerCasedTag) { break; } } } if (pos >= 0) { // 关闭 pos 以后的元素标签,并更新stack数组 for (let i = stack.length - 1; i >= pos; i -= 1) { options.end(stack[i].tag, start, end); } stack.length = pos; // stack 取出数组存储的最后一个元素 lastTag = pos && stack[pos - 1].tag; } }
此时当执行parseEndTag()函数,更新stack和lastTag。
上面提到start(开始标签)
/** * 这个和end相对应,主要处理开始标签和标签的属性(内置和普通属性), * @param tag 标签名 * @param attrs 元素属性 * @param unary 该元素是否单元素, 如img */ start(tag, attrs, unary) { // 创建ast容器 let element = createASTElement(tag,attrs, currentParent); // 下面是加工、处理各种Vue支持的内置属性和普通属性 processFor(element); processIf(element); processOnce(element); processElement(element); if (!root) { root = element; } else if (!stack.length && root.if && (element.elseif || element.else)) { // 在element的ifConditions属性中加入condition addIfCondition(root, { exp: element.elseif, block: element }) } if (currentParent) { if (element.elseif || element.else) { processIfConditions(element, currentParent); } else if (element.slotScope) { // 父级元素是普通元素 currentParent.plain = false; const name = element.slotTarget || '"default"'; (currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element; } else { // 把当前元素添加到父元素的children数组中 currentParent.children.push(element); // 设置当前元素的父元素 element.parent = currentParent; } } // 非单元素,更新父级和保存该元素 if (!unary) { currentParent = element; stack.push(element); } },
上面提到end(结束标签)
/** * 闭合元素,更新stack和currentParent */ end() { // 取出stack中最后一个元素,其实这也是需要闭合元素的开始标签,如</div> 的开始标签就是<div> // 此时取出的element包含该元素的所有信息,包括他的子元素信息 const element = stack[stack.length - 1]; // 取出当前元素的最后一个子节点 const lastNode = element.children[element.children.length - 1]; // 如果最后一个子节点是空文本节点,清除当前子节点, 为什么这么做呢? // 因为我们在写HTML时,标签之间都有间距,有时候就需要这个间距才能达到我们想要的效果, // 比如:<div> <span>111</span> <span>222</span> </div> // 此时111与222之间就有一格的间距,在ast模板解析时,这个不能忽略, // 此时的div的子节点会解析成三个数组, 中间的就是一个文本,只是这个文本是个空格, // 而222的span标签后面的空格我们是不需要的,因为如果我们写了,div的兄弟节点之间会有一个空格的。 // 所以我们需要清除children数组中没有用的项 if (lastNode && lastNode.type === 3 && lastNode.text === ' ') { element.children.pop(); } // 下面才是最重要的,也是end方法真正要做的, // 就是找到了闭合标签,就把保存的开始标签的信息清除,并更新currentParent stack.length -= 1; currentParent = stack[stack.length - 1]; },
上面提到的char(文本标签)
/** * 处理文本和{{}} * @param text 文本内容 */ chars(text) { // 如果是文本,没有父节点,直接返回 if (!currentParent) { return; } const children = currentParent.children; // 判断与处理text, 如果children有值,text为空,那么text = ' '; 原因在end中 text = text.trim() ? text : children.length ? ' ' : ''; if (text) { // 解析文本,处理{{}} 这种形式的文本 const expression = parseText(text); if (text !== ' ' && expression) { children.push({ type: 2, expression, text, }); } else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') { children.push({ type: 3, text, }) } } },
这里我们重点需要说一下parseText()方法,解释都写在了代码中。
const tagRE = /\{\{((?:.|\n)+?)\}\}/g;
export function parseText(text) {
if (tagRE.test(text)) {
return;
}
const tokens = [];
let lastIndex = tagRE.lastIndex = 0;
let match, index;
// exec中不管是不是全局的匹配,只要没有子表达式,
// 其返回的都只有一个元素,如果是全局匹配,可以利用lastIndex进行下一个匹配,
// 匹配成功后lastIndex的值将会变为上次匹配的字符的最后一个位置的索引。
// 在设置g属性后,虽然匹配结果不受g的影响,
// 返回结果仍然是一个数组(第一个值是第一个匹配到的字符串,以后的为分组匹配内容),
// 但是会改变index和 lastIndex等的值,将该对象的匹配的开始位置设置到紧接这匹配子串的字符位置,
// 当第二次调用exec时,将从lastIndex所指示的字符位置 开始检索。
while ((match = tagRE.exec(text))) {
index = match.index;
// 当文本标签中既有{{}} 在其左边又有普通文本时,
// 如:<span>我是普通文本{{value}}</span>, 就会执行下面的方法,添加到tokens数组中。
if (index > lastIndex) {
tokens.push(JSON.stringify(text.slice(lastIndex, index)));
}
// 把匹配到{{}}中的tag 添加到tokens数组中
const exp = match[1].trim();
tokens.push(`_s(${exp})`);
lastIndex = index + match[0].length
}
// 当文本标签中既有{{}} 在其右边又有普通文本时,
// 如:<span>{{value}} 我是普通文本</span>, 就会执行下面的方法,添加到tokens数组中。
if (lastIndex < text.length) {
tokens.push(JSON.stringify(text.slice(lastIndex)));
}
return tokens.join('+');
}
区分parse和parseHTML
通过上面的代码我们大概了解了实现方式,但是我们可能暂时无法区分parse和parseHTML方法都做了什么。因为parse里面调用了parseHTML,我们先讲讲它。
parseHTML: 用正则匹配的方式,逐一循环HTML字符串,分类不同匹配项,保存最基本的tagName(标签名),attrs(属性),此时属性并没有区分是内置属性还是普通属性,只是简单的分隔了属性名和属性值。从函数名中可以看到加了HTML
比如:attrs 可能是这样的:
attrs = [ { name: '@click', value: 'myMethod' }, { name: ':class', value: 'my-class' }, { name: 'type', value: 'button' }, { name: 'v-if', value: 'show' } ];
parse: 从parseHTML解析的基本属性数组中重新解析,区分不同属性做不同处理,普通属性与内置属性处理方式是不一样的。并且判断该元素是在哪个位置,也就是确定该元素的父节点、兄弟节点、子节点,最终形成ast。
如何理解stack
stack翻译成汉语就是“栈”。这里我们可以理解为一个容器,存储开始标签的属性和标签名。这里Vue进行了巧妙的设计:
当是开始标签并且标签是普通标签(如:div),就push到数组最后面,
当是结束标签时,找到保存到stack中的项,然后删除找到的项,删除就是代表着标签闭合。
注意:stack 是按照字符串先后顺序存储的,所以我们在接下来解析html字符串时,遇到的闭合标签就是stack存储的最后一项。如:
<div><span></span></div>
当执行到</span>字符串前,stack存储结果:
stack = [div, span];
在执行</span>时,找到stack最后一项,就是span的开始标签(此时里面包含标签名和元素属性)。我们删除stack中的span(span标签闭合,span元素的解析结束),此时stack 就只剩下 [div], 以此类推。
总结
最后看看运行前后的效果:
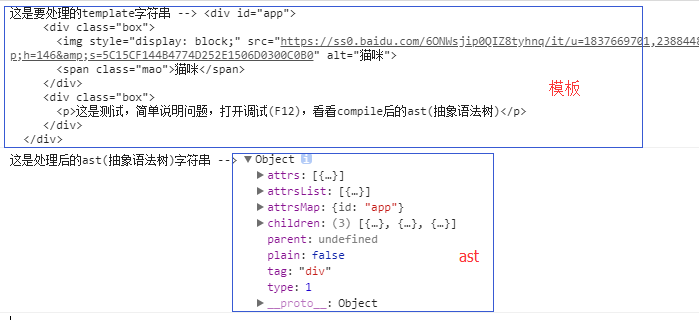
模板解析为ast,需要大量的循环与匹配,需要考虑不同字符串的情况,而这种情况正是我们静下心来好好思考的。本人才疏学浅,有问题请批评指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号