PyTorch复现ResNet学习笔记
PyTorch复现ResNet学习笔记
一篇简单的学习笔记,实现五类花分类,这里只介绍复现的一些细节
如果想了解更多有关网络的细节,请去看论文《Deep Residual Learning for Image Recognition》
简单说明下数据集,下载链接,这里用的数据与AlexNet的那篇是一样的所以不在说明
一、环境准备
可以去看之前的一篇博客,里面写的很详细了,并且推荐了一篇炮哥的环境搭建环境
- Anaconda3(建议使用)
- python=3.6/3.7/3.8
- pycharm (IDE)
- pytorch=1.11.0 (pip package)
- torchvision=0.12.0 (pip package)
- cudatoolkit=11.3
二、模型搭建、训练
1.整体框图
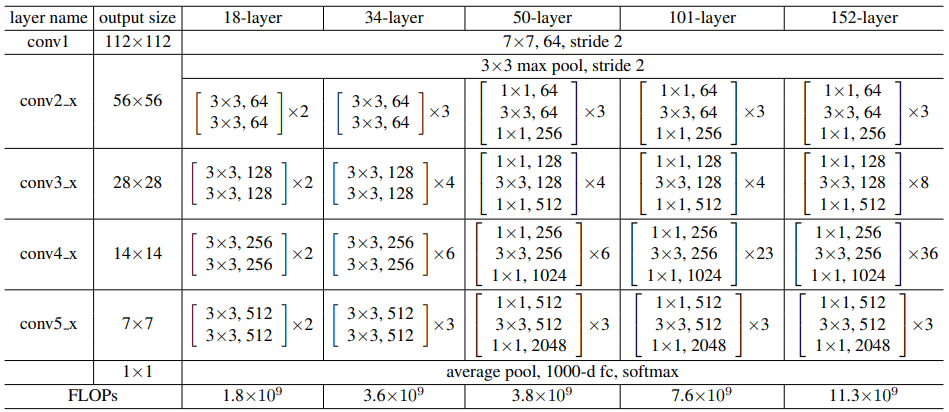
其中残差块有两种结构
两层结构用于34层以下的
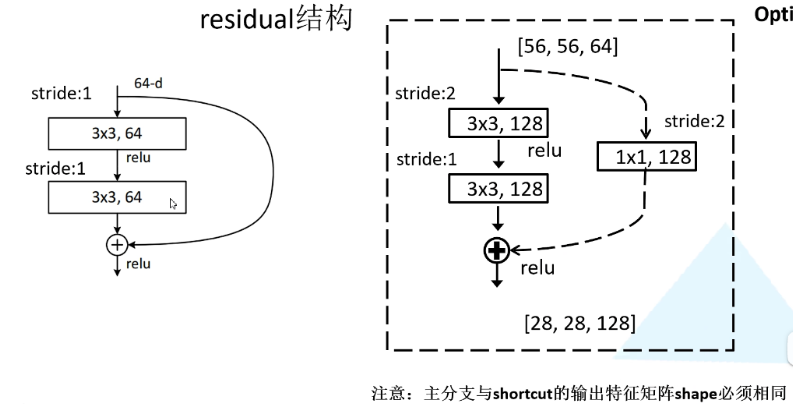
三层结构,用于50,101,152层的
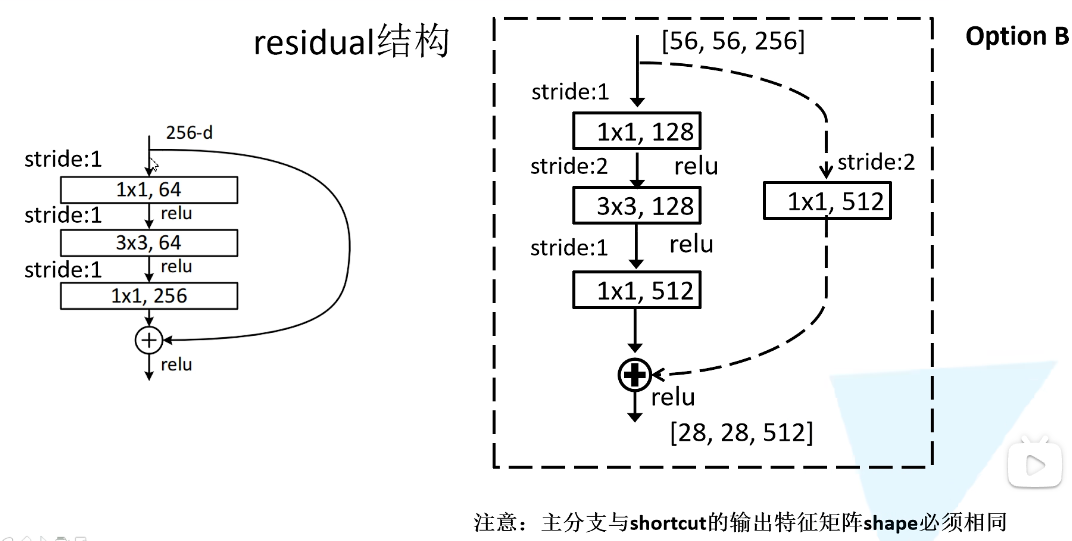
虚线和实线的残差结构,实线:输出和输入维度是一样的,虚线:输入和输出维度不一样,需要进行维度匹配
2.model.py
网络整体结构代码


1 import torch.nn as nn 2 import torch 3 4 class BasicBlock(nn.Module): 5 #对应18层和34层的残差块 6 expansion = 1 7 def __init__(self,in_channel,out_channel,stride=1,downsample=None,**kwargs): 8 super(BasicBlock,self).__init__() 9 self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel, 10 kernel_size=3,stride=stride,padding=1,bias=False) 11 self.bn1 = nn.BatchNorm2d(out_channel) 12 self.relu = nn.ReLU() 13 self.conv2 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel, 14 kernel_size=3,stride=1,padding=1,bias=False) 15 self.bn2 = nn.BatchNorm2d(out_channel) 16 self.downsample = downsample 17 18 def forward(self,x): 19 identity = x 20 if self.downsample is not None: 21 identity = self.downsample(x) 22 out = self.conv1(x) 23 out = self.bn1(out) 24 out = self.relu(out) 25 out = self.conv2(out) 26 out = self.bn2(out) 27 28 out +=identity#跨层连接 29 out = self.relu(out) 30 31 return out 32 33 class Bottleneck(nn.Module): 34 #适用于50,101,152层的 35 """ 36 注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。 37 但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2, 38 这么做的好处是能够在top1上提升大概0.5%的准确率。 39 可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch 40 """ 41 expansion = 4 42 def __int__(self,in_channel,out_channel,stride=1,downsample=None): 43 super(Bottleneck,self).__init__() 44 45 self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel, 46 kernel_size=1,stride=1,bias=False) 47 self.bn1 = nn.BatchNorm2d(out_channel) 48 self.conv2 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel, 49 kernel_size=3,stride=stride,bias=False,padding=1) 50 self.bn2 = nn.BatchNorm2d(out_channel) 51 self.conv3 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel*self.expansion, 52 kernel_size=1,stride=1,bias=False)#扩展维度 53 self.bn3 = nn.BatchNorm2d(out_channel*self.expansion) 54 self.relu = nn.ReLU(inplace=True)#inplace = True ,会改变输入数据的值,节省反复申请与释放内存的空间与时间,只是将原来的地址传递,效率更好 55 self.downsample = downsample 56 57 def forward(self,x): 58 identity = x #跨层连接的x 59 if self.downsample is not None: 60 identity = self.downsample(x) 61 62 out = self.conv1(x) 63 out = self.bn1(out) 64 out = self.relu(out) 65 66 out = self.conv2(out) 67 out = self.bn2(out) 68 out = self.relu(out) 69 70 out = self.conv3(out) 71 out = self.bn3(out) 72 73 out += identity 74 out = self.relu(out) 75 76 return out 77 78 class ResNet(nn.Module): 79 def __init__(self,block,blocks_num,num_classes=1000,include_top=True): 80 super(ResNet, self).__init__() 81 self.include_top = include_top 82 self.in_channel = 64 83 84 85 self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, 86 padding=3, bias=False) 87 self.bn1 = nn.BatchNorm2d(self.in_channel) 88 self.relu = nn.ReLU(inplace=True) 89 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) 90 self.layer1 = self._make_layer(block, 64, blocks_num[0]) 91 self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) 92 self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) 93 self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) 94 if self.include_top: 95 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1) 96 self.fc = nn.Linear(512 * block.expansion, num_classes) 97 98 for m in self.modules(): 99 '初始化权重' 100 if isinstance(m,nn.Conv2d): 101 '随机矩阵显式创建权重' 102 nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu') 103 104 105 def _make_layer(self,block,channel,block_num,stride=1): 106 downsample = None 107 if stride != 1 or self.in_channel != channel * block.expansion:#表示层数是大于50的 108 ''' 109 表示虚线的残差结构,需要进行维度扩展,一般是每一层的第一个残差结构 110 第一层(conv2_x)的虚线残差结构只需要扩展维度 111 而后面层的虚线残差结构还需要下采样将图像大小缩小一般 112 ''' 113 downsample = nn.Sequential( 114 nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False), 115 nn.BatchNorm2d(channel * block.expansion)) 116 117 layers = [] 118 '放入第一块残差结构' 119 layers.append(block(self.in_channel, 120 channel, 121 downsample=downsample, 122 stride=stride)) 123 self.in_channel = channel * block.expansion 124 125 '放入剩余的残差块' 126 for _ in range(1, block_num): 127 #实线残差结构,不需要维度扩展 128 layers.append(block(self.in_channel, 129 channel)) 130 131 return nn.Sequential(*layers) 132 133 134 def forward(self, x): 135 x = self.conv1(x) 136 x = self.bn1(x) 137 x = self.relu(x) 138 x = self.maxpool(x) 139 140 x = self.layer1(x) 141 x = self.layer2(x) 142 x = self.layer3(x) 143 x = self.layer4(x) 144 145 if self.include_top: 146 x = self.avgpool(x) 147 x = torch.flatten(x, 1) 148 x = self.fc(x) 149 150 return x 151 152 def resnet34(num_classes=1000,include_top=True): 153 '用于18,34层' 154 return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top) 155 156 157 def resnet101(num_classes=1000,include_top=True): 158 '用于50,101,152层,只需要将括号的数字改了即可' 159 return ResNet(BasicBlock,[3,4,23,3],num_classes=num_classes,include_top=include_top) 160 161 if __name__=="__main__": 162 #没有固定的输入大小,因为有自适应池化层,但这里统一用输入为224*224 163 x = torch.rand([1, 3, 224, 224]) 164 model = resnet34(num_classes=5) 165 y = model(x) 166 print(y) 167 168 #统计模型参数 169 sum = 0 170 for name, param in model.named_parameters(): 171 num = 1 172 for size in param.shape: 173 num *= size 174 sum += num 175 #print("{:30s} : {}".format(name, param.shape)) 176 print("total param num {}".format(sum))#total param num 21,287,237
写完后保存,运行可以检查是否报错
如果需要打印模型参数,将代码注释去掉即可,得到resnet34层的网络参数为21,287,237,相比vgg16来说还是少了很多
3.数据划分
这里与AlexNet用的一样
分好后的数据集

运行下面代码将数据按一定比例,划分为训练集和验证集
1 import os 2 from shutil import copy 3 import random 4 5 6 def mkfile(file): 7 if not os.path.exists(file): 8 os.makedirs(file) 9 10 11 # 获取data文件夹下所有文件夹名(即需要分类的类名) 12 file_path = 'flower_photos' 13 flower_class = [cla for cla in os.listdir(file_path)] 14 15 # 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录 16 mkfile('data/train') 17 for cla in flower_class: 18 mkfile('data/train/' + cla) 19 20 # 创建 验证集val 文件夹,并由类名在其目录下创建子目录 21 mkfile('data/val') 22 for cla in flower_class: 23 mkfile('data/val/' + cla) 24 25 # 划分比例,训练集 : 验证集 = 9 : 1 26 split_rate = 0.1 27 28 # 遍历所有类别的全部图像并按比例分成训练集和验证集 29 for cla in flower_class: 30 cla_path = file_path + '/' + cla + '/' # 某一类别的子目录 31 images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称 32 num = len(images) 33 eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称 34 for index, image in enumerate(images): 35 # eval_index 中保存验证集val的图像名称 36 if image in eval_index: 37 image_path = cla_path + image 38 new_path = 'data/val/' + cla 39 copy(image_path, new_path) # 将选中的图像复制到新路径 40 41 # 其余的图像保存在训练集train中 42 else: 43 image_path = cla_path + image 44 new_path = 'data/train/' + cla 45 copy(image_path, new_path) 46 print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar 47 print() 48 49 print("processing done!")
4.train.py
这里训练我们同样使用迁移学习,来减少训练时间,
1 import os 2 import sys 3 import json 4 import wandb 5 import torch 6 import torch.nn as nn 7 import torch.optim as optim 8 from torch.optim import lr_scheduler 9 from torch.utils.data import DataLoader 10 from torchvision import transforms,datasets 11 from tqdm import tqdm 12 import matplotlib.pyplot as plt 13 from matplotlib.ticker import MaxNLocator 14 15 from model import resnet34 16 17 def main(): 18 # 如果显卡可用,则用显卡进行训练 19 device = 'cuda' if torch.cuda.is_available() else 'cpu' 20 print("using {} device".format(device)) 21 print(torch.cuda.get_device_name(0)) 22 23 data_transform = { 24 "train":transforms.Compose([ 25 transforms.RandomResizedCrop(224), 26 transforms.RandomHorizontalFlip(), 27 transforms.ToTensor(), 28 transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) 29 ]), 30 "val":transforms.Compose([ 31 transforms.Resize(256), 32 transforms.CenterCrop(224), 33 transforms.ToTensor(), 34 transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) 35 ]) 36 } 37 38 #数据集路径 39 ROOT_TRAIN = 'data/train' 40 ROOT_TEST = 'data/val' 41 42 batch_size = 16 43 #加载数据集并处理 44 train_dataset = datasets.ImageFolder(ROOT_TRAIN,transform=data_transform["train"]) 45 val_dataset = datasets.ImageFolder(ROOT_TEST,transform=data_transform["val"]) 46 # 划成一批批乱序数据集 47 train_dataloader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True) 48 val_dataloader = DataLoader(val_dataset,batch_size=batch_size,shuffle=True) 49 #计算数据数量 50 train_num = len(train_dataset) 51 val_num = len(val_dataset) 52 print("using {} images for training,{} images for validation.".format(train_num,val_num)) 53 54 #将{'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}键值对值反转,并保存 55 flower_list = train_dataset.class_to_idx 56 cla_dict = dict((val,key) for key,val in flower_list.items()) 57 #将键值对写入json文件 58 json_str = json.dumps(cla_dict,indent=4) 59 with open('class_indices.json','w')as json_file: 60 json_file.write(json_str)#保存json文件(好处,方便转换为其它类型数据)用于预测用 61 62 nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers 63 print('Using {} dataloader workers every process'.format(nw)) 64 65 model = resnet34() 66 #加载预训练权重 67 model_weight_path = "save_model/best_model.pth" 68 assert os.path.exists(model_weight_path),"file {} does not exist.".format(model_weight_path) 69 model.load_state_dict(torch.load(model_weight_path,map_location='cpu')) 70 71 #change fc layer structure 72 # in_channel = model.fc.in_features 73 # model.fc = nn.Linear(in_channel,5) 74 model.to(device) 75 76 #损失函数 77 loss_function = nn.CrossEntropyLoss() 78 #优化器 79 optimizer = optim.Adam(model.parameters(),lr=0.001) 80 # 学习率每隔10epoch变为原来的0.1 81 lr_s = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.5) 82 83 #定义训练函数 84 def train(dataloader,model,loss_fn,optimizer): 85 model.train() 86 loss,acc,n = 0.0,0.0,0 87 train_bar = tqdm(dataloader,file=sys.stdout) 88 for batch,(x,y) in enumerate(train_bar): 89 #前向传播 90 x,y = x.to(device),y.to(device) 91 output = model(x) 92 cur_loss = loss_fn(output,y) 93 _,pred = torch.max(output,axis=-1) 94 cur_acc = torch.sum(y==pred)/output.shape[0] 95 #反向传播 96 optimizer.zero_grad()#梯度清零 97 cur_loss.backward() 98 optimizer.step() 99 loss += cur_loss.item() 100 acc += cur_acc.item() 101 n += 1 102 train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(i+1,epoch,cur_loss) 103 train_loss = loss / n 104 train_acc = acc / n 105 106 print(f"train_loss:{train_loss}") 107 print(f"train_acc:{train_acc}") 108 return train_loss,train_acc 109 110 #定义验证函数 111 def val(dataloader,model,loss_fn): 112 model.eval() 113 loss,acc,n = 0.0,0.0,0 114 val_bar = tqdm(dataloader,file=sys.stdout) 115 for batch,(x,y) in enumerate(val_bar): 116 #前向传播 117 x,y = x.to(device),y.to(device) 118 output = model(x) 119 cur_loss = loss_fn(output,y) 120 _,pred = torch.max(output,axis=-1) 121 cur_acc = torch.sum(y==pred)/output.shape[0] 122 loss += cur_loss.item() 123 acc += cur_acc.item() 124 n += 1 125 val_bar.desc = "val epoch[{}/{}] loss:{:.3f}".format(i+1,epoch,cur_loss) 126 val_loss = loss / n 127 val_acc = acc / n 128 129 print(f"val_loss:{val_loss}") 130 print(f"val_acc:{val_acc}") 131 return val_loss,val_acc 132 133 # 解决中文显示问题 134 plt.rcParams['font.sans-serif'] = ['SimHei'] 135 plt.rcParams['axes.unicode_minus'] = False 136 137 # 画图函数 138 def matplot_loss(train_loss, val_loss): 139 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠 140 plt.plot(train_loss, label='train_loss') # 画图 141 plt.plot(val_loss, label='val_loss') 142 plt.legend(loc='best') # 图例 143 plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True)) 144 plt.ylabel('loss', fontsize=12) 145 plt.xlabel('epoch', fontsize=12) 146 plt.title("训练集和验证集loss对比图") 147 folder = 'result' 148 if not os.path.exists(folder): 149 os.mkdir('result') 150 plt.savefig('result/loss.jpg') 151 152 def matplot_acc(train_acc, val_acc): 153 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠 154 plt.plot(train_acc, label='train_acc') # 画图 155 plt.plot(val_acc, label='val_acc') 156 plt.legend(loc='best') # 图例 157 plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True)) 158 plt.ylabel('acc', fontsize=12) 159 plt.xlabel('epoch', fontsize=12) 160 plt.title("训练集和验证集acc对比图") 161 plt.savefig('result/acc.jpg') 162 163 #开始训练 164 train_loss_list = [] 165 val_loss_list = [] 166 train_acc_list = [] 167 val_acc_list = [] 168 169 epoch = 5 170 max_acc = 0 171 172 wandb.init(project='ResNet',name='resnet34.1') 173 174 for i in range(epoch): 175 lr_s.step() 176 train_loss,train_acc=train(train_dataloader,model,loss_function,optimizer) 177 wandb.log({'train_loss': train_loss, 'train_acc': train_acc}) 178 val_loss,val_acc=val(val_dataloader,model,loss_function) 179 wandb.log({'val_loss': val_loss, 'val_acc': val_acc}) 180 181 train_loss_list.append(train_loss) 182 val_loss_list.append(val_loss) 183 train_acc_list.append(train_acc) 184 val_acc_list.append(val_acc) 185 #保存最好的模型权重 186 if val_acc > max_acc: 187 folder = 'save_model' 188 if not os.path.exists(folder): 189 os.mkdir('save_model') 190 max_acc = val_acc 191 print('save best model') 192 torch.save(model.state_dict(), "save_model/best_model.pth") 193 # 保存最后一轮 194 # if i == epoch - 1: 195 # torch.save(model.state_dict(), 'save_model/last_model.pth') 196 197 print("Finished Training") 198 #画图 199 # matplot_loss(train_loss_list,val_loss_list) 200 # matplot_acc(train_acc_list,val_acc_list) 201 202 if __name__=='__main__': 203 main()
训练结束后可以得到训练集和验证集的loss,acc对比图

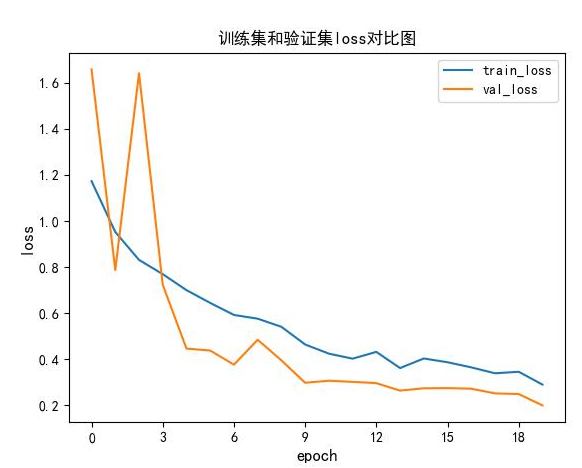
简单的评估下:同样在resnet34的训练中可以看出,迁移学习的强大
总结
相比VGG-16,resnet可以训练层数更深的网络,并且少的多的参数
自己敲一下代码,会学到很多不懂的东西
最后,多看,多学,多试,总有一天你会称为大佬!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号