

redis学习笔记,供自己学习用可能缺少细节
Redis入门
概述
redis是什么?
- Redis( remote Dictionary Server ),即远程字典服务
redis能干什么?
- 内存存储,持久化,内存中是断电即失,持久化很重要(rdb,aof)
- 效率高,可以用于告诉缓存
- 发布订阅系统
- 地图信息分析
- 计时器,计数器(浏览量!)
特性
1.多样的数据类型
2.持久化
3.集群
4.事务
安装
- 解压
- make(需要安装gcc环境)
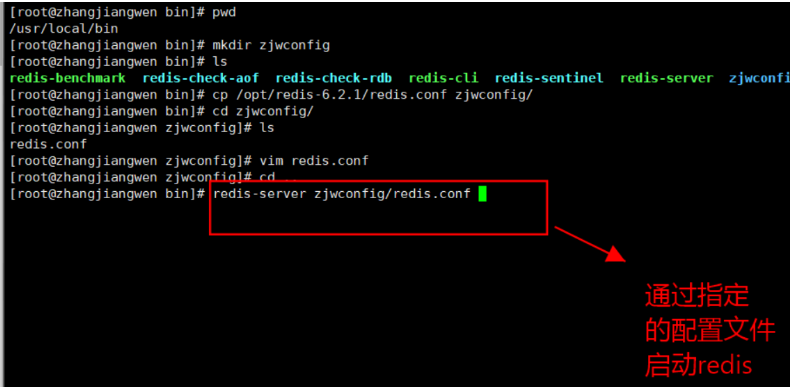
- 查看安装后的/usr/local/bin
- 安装完后将配置文件备份cp /opt/redis-6.2.1/redis.conf zjwconfig/
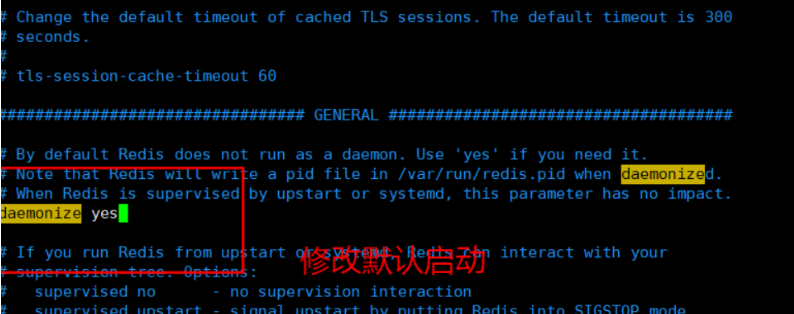
- redis默认不是后台启动,配置后台启动redis
![]()
![]()
![]()
![]()
![]()
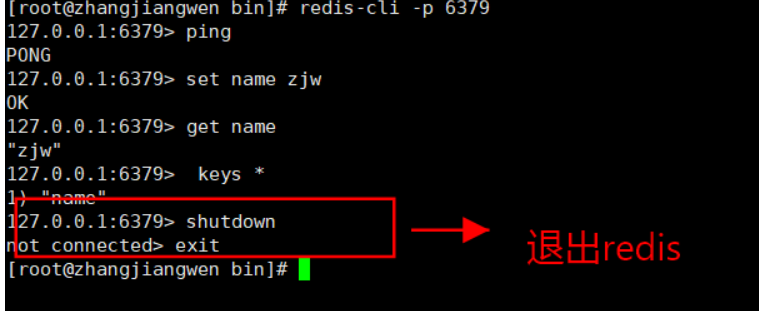
- 压力测试
# 测试100个并发连接 100000请求
redis-benchmark-h localhost -p 6379 -c 100 -n 100000
基础知识
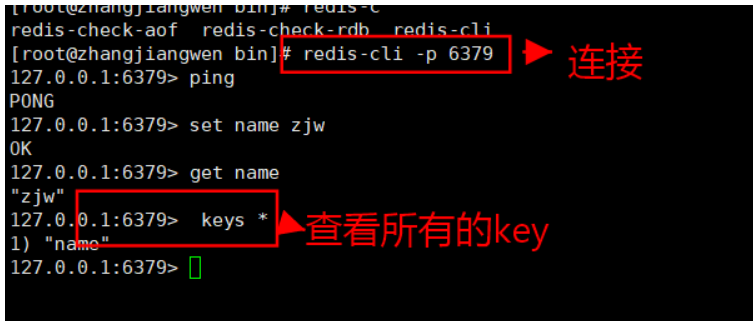
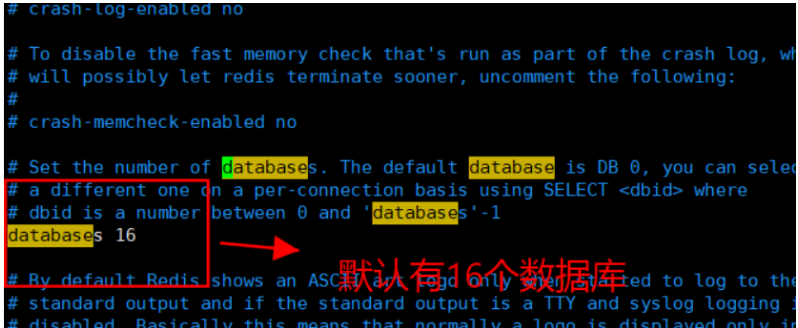
redis默认有16个数据库
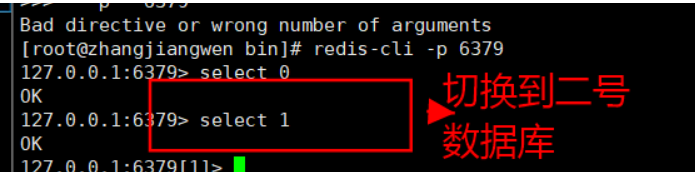
使用select选择数据库
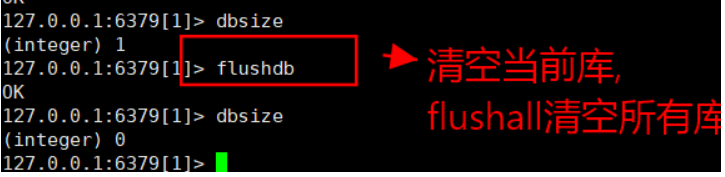
查看数据库大小

清空命令
redis是单线程的
redis是很快的,redis是基于呢村操作的,cpu不是redis的性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线程,所以就使用了单线程!
redis是c语言写的 10w+的qps
单线程怎么还这么快?
1. 误区一:高性能的服务器一定是多线程的
2. 误区二:多线程(cpu会上下文切换)一定比但现场效率高
速度 cpu>内存>硬盘
String的使用
========================================
1
127.0.0.1:6397[2]> get testkey //获取key
127.0.0.1:6397[2]> dbsize //获取当前数据库大小
0
127.0.0.1:6397[2]> set ttlkey '测试过期key' ex10 //设置key和过期时间
OK
127.0.0.1:6397[2]> set mykey "册数" ex 10
OK
127.0.0.1:6397[2]> keys * //获取当前库所有key
mykey
127.0.0.1:6397[2]> keys *
127.0.0.1:6397[2]> keys *
127.0.0.1:6397[2]> ttl mykey //获取当前key过期时间
-2
127.0.0.1:6397[2]> set token "{}" ex 1000
OK
127.0.0.1:6397[2]> typr token
ERR unknown command `typr`, with args beginning with: `token`,
127.0.0.1:6397[2]> type token // 获取key的类型
string
127.0.0.1:6397[2]> ttl token
986
127.0.0.1:6397[2]> ping
PONG
127.0.0.1:6397[2]> ping
PONG
127.0.0.1:6397[2]> append token "zjw" //在指定key后面添加字符
5
127.0.0.1:6397[2]> get token
{}zjw
127.0.0.1:6397[2]> STRLEN token //获取key的长度
5
127.0.0.1:6397[2]> EXPIRE token 10000 //设置key的过期时间
1
127.0.0.1:6397[2]> ttl token
9997
=========================
#自增自减
127.0.0.1:6397[2]> set views 0 //设置key为0记录浏览量
OK
127.0.0.1:6397[2]> get views
0
127.0.0.1:6397[2]> incr views //key自增1
1
127.0.0.1:6397[2]> incr views
2
127.0.0.1:6397[2]> incr views
3
127.0.0.1:6397[2]> decr views //key自减1
2
127.0.0.1:6397[2]> INCRBY views 10 //key自增10设置步长
12
127.0.0.1:6397[2]> INCRBY views 10
22
127.0.0.1:6397[2]> DECRBY views 2 //key自减2设置步长
20
127.0.0.1:6397[2]> DECRBY views 2
18
127.0.0.1:6397[2]> DECRBY views 2
16
127.0.0.1:6397[2]>
====================================
#获取截取后字符串
127.0.0.1:6397[2]> set key 'hellokugou'
OK
127.0.0.1:6397[2]> get key
hellokugou
127.0.0.1:6397[2]> GETRANGE ket 1 2 //获取[1,2]
# 替换
127.0.0.1:6397[2]> get key
hellokugou
127.0.0.1:6397[2]> GETRANGE key 1 2
el
127.0.0.1:6397[2]> SETRANGE key -1 xxxx
ERR offset is out of range
127.0.0.1:6397[2]> SETRANGE key 4 xxxx // 从4开始替换
10
127.0.0.1:6397[2]> get key
hellxxxxou
==================================
# setex(set with expire) #设置过期时间
# setnx(set if not exits)#不存在再设置过期时间
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置失效时长,单位秒
PX milliseconds:设置失效时长,单位毫秒
NX:key不存在时设置value,成功返回OK,失败返回(nil)
XX:key存在时设置value,成功返回OK,失败返回(nil)
案例:设置name=mracale,失效时长100s,不存在时设置
1.1.1.1:6379> set name mracale ex 100 nx
OK
1.1.1.1:6379> get name
"mracale"
1.1.1.1:6379> ttl name
(integer) 94
#mset
#mget 两者都是原子性操作要么同时成功要么同时失败
#getset 先获取再设置,不存在就返回null
list使用
1.push pop range使用
127.0.0.1:6397[2]> LPUSH list 1 #往list左边插入一个值
1
127.0.0.1:6397[2]> LPUSH list 2
2
127.0.0.1:6397[2]> LPUSH list 3
3
127.0.0.1:6397[2]> LRANGE list 0 -1 # 获取list中所有的值
3
2
1
127.0.0.1:6397[2]> RPUSH list 4 #往list的最后面插入值
4
127.0.0.1:6397[2]> LRANGE list 0 -1
3
2
1
4
127.0.0.1:6397[2]> LPOP list #将list的第一个值移除
3
127.0.0.1:6397[2]> lrange list 0 -1
2
1
4
127.0.0.1:6397[2]> RPOP list #将list的最后一个值移除
4
127.0.0.1:6397[2]> lrange list 0 -1
2
1
===============================================
2.Lindex llen lrem使用
127.0.0.1:6397[2]> LINDEX list 1 #通过下表获取list中的某一个值
1
127.0.0.1:6397[2]> LLEN list # 获取list的长度
2
127.0.0.1:6397[2]> LRANGE list 0 -1 # 查询list所有的值
3
2
2
2
1
1
2
127.0.0.1:6397[2]> LREM list 1 2 # 移除list中的值为2的一个元素
1
127.0.0.1:6397[2]> LRANGE list 0 -1
3
2
2
1
1
2
127.0.0.1:6397[2]> LREM list 2 1 # 移除list中值为1的两个元素
2
127.0.0.1:6397[2]> lrange list 0 -1
3
2
2
2
3.ltrim和rpoplpush,linsert
127.0.0.1:6397[2]> LRANGE zjwlist 0 -1
bangpi
cxz
zzc
zjw
127.0.0.1:6397[2]> LTRIM zjwlist 1 2 # 将zjwlist截取[1,2]后重新赋值
OK
127.0.0.1:6397[2]> LRANGE zjwlist 0 -1
cxz
zzc
==========================================
127.0.0.1:6397[2]> LRANGE zjwlist 0 -1
cxz
zzc
bangpi
yzq
127.0.0.1:6397[2]> RPOPLPUSH zjwlist zjw #zjwlist最后一个元素移除并插入到zjw
======================================
127.0.0.1:6397[2]> LSET zjw 0 "'yzq'" #将zjw中的第0个元素替换成'yzq'(原始值为yzq)
OK
127.0.0.1:6397[2]> LRANGE zjw 0 2
'yzq'
=======================================
127.0.0.1:6397[2]> lrange zjwlist 0 -1
yzq
cxz
zzc
bangpi
127.0.0.1:6397[2]> LINSERT zjwlist after zzc zzc1 #往zjwlist的zzc元素后面添加元素zzc1
5
127.0.0.1:6397[2]> lrange zjwlist 0 -1
yzq
cxz
zzc
zzc1
bangpi
127.0.0.1:6397[2]> LINSERT zjwlist before cxz cxz1 #往zjwlist的cxz元素前面添加元素cxz1
6
127.0.0.1:6397[2]> lrange zjwlist 0 -1
yzq
cxz1
cxz
zzc
zzc1
bangpi
小结
- 他实际上是一个链表,before node after ,left,right都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有制,空链表也代表不存在
- 在两边插入或者改动值,效率最高.操作中间元素相对来说效率低些
redis可以做消息队列(lpush rpop) 先进先出 栈(lpush lpop)先进后出
set使用
set中的值是不能重复的是无序的
1.set添加值查询值
127.0.0.1:6397[2]> sadd set hello #往set里面添加值hello
1
127.0.0.1:6397[2]> sadd set hello #往set里面添加重复的值会失败跟java中的set一样
0
127.0.0.1:6397[2]> sadd set hello
0
127.0.0.1:6397[2]> sadd set hello
0
127.0.0.1:6397[2]> sadd set hello1
1
127.0.0.1:6397[2]> SMEMBERS set #查看set中所有的值
hello
hello1
127.0.0.1:6397[2]> SISMEMBER set zjw #查看set中有没有zjw这个值,返回0表示不存在
0
127.0.0.1:6397[2]> SISMEMBER set hello #查看set中有没有hello这个值,返回1表示存在
1
=====================================
127.0.0.1:6397[2]> SCARD set #查看set的长度
2
127.0.0.1:6397[2]> SREM set hello #移除set中的hello元素
1
127.0.0.1:6397[2]> SCARD set
1
127.0.0.1:6397[2]> SMEMBERS set
hello1
2.set中的一些内置函数
127.0.0.1:6397[2]> SRANDMEMBER set #随机获取set中的一个元素
zjw3
127.0.0.1:6397[2]> SRANDMEMBER set
zjw1
127.0.0.1:6397[2]> SRANDMEMBER set
zjw2
127.0.0.1:6397[2]> SRANDMEMBER set
hello1
127.0.0.1:6397[2]> SRANDMEMBER set 3 #随机获取set中的3个元素
zjw2
zjw3
hello1
127.0.0.1:6397[2]> SRANDMEMBER set 3
zjw2
zjw3
hello1
127.0.0.1:6397[2]> SRANDMEMBER set 3
zjw1
zjw
hello1
127.0.0.1:6397[2]> SPOP set #随机移除set中的一个元素
zjw3
==============================================
127.0.0.1:6397[2]> SMOVE set set1 zjw #将set中的zjw元素移动到set1
1
127.0.0.1:6397[2]> SMEMBERS set1
zjw
127.0.0.1:6397[2]> SMEMBERS set
zjw1
zjw2
hello1
========================================
两个平台的共同关注(交集)
数字集合类
-差集 SDIFF
-交集 SINTER
-并集 SUNION
127.0.0.1:6397[2]> SMEMBERS set1
zjw
world
zjw2
127.0.0.1:6397[2]> SMEMBERS set
zjw
zjw1
zjw2
hello1
127.0.0.1:6397[2]> SDIFF set set1 #set中与set1不重复的
zjw1
hello1
127.0.0.1:6397[2]> SINTER set set1 #set中与set1相同的元素
zjw
zjw2
127.0.0.1:6397[2]> SUNION set set1 #set和set1并集
zjw
zjw1
zjw2
world
hello1
微博,a用户所有关注的人在一个set集合中,将他的粉丝也放在一个集合中,共同关注,共同爱好推荐好友都可以通过交集并集差集计算
hash使用
map集合,key-map,这时候这个值是一个map集合!本质和string没有太大区别
1.hget hset和string差不多
hgetall获取键里面的map
127.0.0.1:6397[2]> HKEYS map # 获取所有键
k1
k2
k3
127.0.0.1:6397[2]> HVALS map #获取所有值
v1
v2
v3
127.0.0.1:6397[2]>
zset使用
在set上基础上增加了一个值
127.0.0.1:6397[2]> ZRANGE zset 0 -1 #获取zset的值从小到大
zjw20
zjw30
zjw50
zjw
zjw200
127.0.0.1:6397[2]> ZREVRANGE zset 0 -1 #获取zset的值从大到小
zjw200
zjw
zjw50
zjw30
zjw20
127.0.0.1:6397[2]> ZRANGEBYSCORE zset -inf +inf withscores # 将zset的scores升序排序并显示score
zjw20
20
zjw30
30
zjw50
50
zjw
100
zjw200
200
127.0.0.1:6397[2]> ZINCRBY zset 1 zjw20 # 将zset的zjw20元素的score加上1
21
三种特殊类型
Geospatial地理位置
朋友定位,附近的人等等
1.geoadd,GEOPOS
#geoadd 添加地理位置
#规则:两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入
#参数key-值(经度,纬度,名称)
127.0.0.1:6397[2]> geoadd china:city 116.40000 39.90000 beijing 114.05000 22.52000 shenzhen 120.16000 30.24000 hangzhou 108.96000 34.26000 xian 121.47000 31.23000 shanghai
5 #初始化地理位置信息
127.0.0.1:6397[2]> GEOPOS china:city 西安 #获取西安的经纬度
108.96000176668167114
34.25999964418929977
2.geodist
两个城市间的距离
127.0.0.1:6397[2]> GEODIST china:city shanghai beijing km
1067.3788
#计算北京到上海的距离
3.georadius
127.0.0.1:6397[2]> GEORADIUS china:city 100 30 1000 km
西安
#获取经度100纬度30附近1000km的城市
127.0.0.1:6397[2]> GEORADIUS china:city 100 30 1000 km withdist
西安
967.2846
#获取经度100纬度30附近1000km的城市并返回距离
127.0.0.1:6397[2]> GEORADIUS china:city 100 30 1000 km withcoord
西安
108.96000176668167114
34.25999964418929977
#获取经度100纬度30附近1000km的城市并返回该城市的经纬度
127.0.0.1:6397[2]> GEORADIUS china:city 110 30 1000 km withdist withcoord count 2
西安
483.8340
108.96000176668167114
34.25999964418929977
shenzhen
924.6408
114.04999762773513794
22.5200000879503861
#获取经度100纬度30附近1000km的城市并返回该城市的经纬度距离,并且返回2个
127.0.0.1:6397[2]> GEORADIUSBYMEMBER china:city 西安 1000 km
西安
beijing
#找出指定元素一定距离内的元素
4.geohash返回一个或多个位置元素的geohash表示
#将二维的经纬度转换成字符串,降维打击,两个字符串越接近代表距离越近
127.0.0.1:6397[2]> GEOHASH china:city beijing shanghai
wx4fbxxfke0
wtw3sj5zbj0
geo底层是zset实现的,我们可以使用zset命令操作geo
#使用zrem命令删除指定的元素
127.0.0.1:6397[2]> zrem china:city 西安#删除西安元素
1
127.0.0.1:6397[2]>
hyperloglog
简介
redis 2.8.9版本更新了hyperloglog数据结构!
redis hyperloglog基数统计的算法
优点:占用的内存是固定的,存放2^64次方不同的元素的基数,只需要占用12kb内存
网页的UV
传统方式,set保存的用户id,然后就可以溶剂set中的元素数量作为标准判断
这个方式如果保存大量的用户id,就会比较麻烦,我们的目的是为了计数,而不是保存用户id
官方说明有0.81%的错误率!统计UV任务可以忽略不计
测试使用
127.0.0.1:6397[2]> PFADD myuv asd asda asfs sdf sdf sf sdf sf s adsdgs cdsc gfv cfv fj ngvgv fv fd dfg fdg bcvxz czxbnghm bjvcf dvdyyve bt6 grty f 2e
1
# 往myuv中添加数据
127.0.0.1:6397[2]> pfcount myuv
24
# myuv计数
127.0.0.1:6397[2]> pfadd myuv1 bv df asa dsdssssssss fffffffffffffffff gggggggggggge eeeeeeeeeeeeee wwwwwwwwwwwwww qqqqqqqqqqqq yyyyyyyyyyyy nnnnnnnnnnn xxxxxxxxxxxxx zzzzzzzzzzz fdgd rtyv cgvg c4 v5 b6b67 8m8ommn 5cw3xe23 e23e2 3x23r 2r 2r 2r23 2c3rc23 r245v c32v4 34rc 34rv3 4r 3532 4v23 4c23 4c2343v 6b6v54 wrvb6 45
1
127.0.0.1:6397[2]> PFCOUNT myuv1
38
127.0.0.1:6397[2]> PFMERGE myuv2 myuv1 myuv
OK
#合并myuv 和myuv1到myuv2
127.0.0.1:6397[2]> pfcount myuv2
62
bitmap
位存储
统计用户信息(登录,未登录等)两个状态的都可以使用bitmap
bitmap位图也是一种数据结构!都是操作二进制位来进行记录的,就只有0和1两个状态
365天的数据=365bit 1字节=8位 一年一个用户的打卡记录就46个字节左右
测试
127.0.0.1:6397[2]> setbit daka 0 0 #往bitmap中添加数据
0
127.0.0.1:6397[2]> setbit daka 1 0
0
127.0.0.1:6397[2]> setbit daka 2 1
0
127.0.0.1:6397[2]> setbit daka 3 0
0
127.0.0.1:6397[2]> setbit daka 4 1
0
127.0.0.1:6397[2]> getbit daka 4 #获取数据
1
127.0.0.1:6397[2]> BITCOUNT daka #bitmap计数
2
事务
redis事务本质:一组命令的集合!一个事物中的所有命令都会被序列化,在食物执行过程中,会按照顺序执行
redis事务特性:一次性顺序性排他性
----------队列 操作1 操作2 .... 执行--------
redis单条命令是保存原子性的,但是事务不保证原子性!
redis的事务
-
开启事务(multi)
-
命令入队(....)
-
执行事务(exec)
-
取消执行事务(discard) 最后两步一个表示执行一个表示取消执行
127.0.0.1:6397[2]> multi #开启事务
OK
127.0.0.1:63972> set k1 v1
QUEUED
127.0.0.1:63972> sadd set asd
QUEUED
127.0.0.1:63972> LPUSH list zjw
QUEUED
127.0.0.1:63972> RPUSH list zjwr
QUEUED
127.0.0.1:63972> zadd zset 23 zjw23
QUEUED
127.0.0.1:63972> LRANGE list 0 -1
QUEUED
127.0.0.1:63972> hset mymap k1 v1
QUEUED
127.0.0.1:63972> exec #执行事务
乐观锁悲观锁
- 悲观锁
无论什么时候都要加锁,导致效率低
-
乐观锁
认为什么时候都不会出问题.所以不会上锁,在更新数据的时候去判断下此期间是否有人操作被监控的数据
获取版本
更新的时候比较versionwatch命令监控 unwatch命令取消监控
springboot整合
springboot操作数据 sprin-data jpa mongodb redis
springdata和springboot齐名
springboot2.x后没有使用jedis,替换成了lettuce
- jedis使用的是直连的方式,多个线程操作不安全,要想避免不安全需要使用连接池 更像bio
- lettuce才用的是netty,示例可以再多个线程汇总共享,更像nio模式
配置文件详解
包含
# include /path/to/local.conf
# include /path/to/other.conf
#可以把多个配置文件合并
通用
daemonize yes #通过守护进程的方式运行,默认是no,我们需要自己开启为yes
pidfile /var/run/redis_6379.pid
#如果redis是以后台的方式运行,我们就需要制定一个pid文件
#日志
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" #生成的日志文件,为空的话就是一个标准的输出
databases 16 #数据库的 数量,默认是16个
always-show-logo no #启动redis的时候是否显示logo
快照
持久化,在规定时间内,执行了多少次操作则会持久化道文件.rdb.aof
redis是内存数据库,如果没有持久化,就会断电即失
# save 3600 1
# save 300 100
# save 60 10000
#如果3600秒内至少有1个key进行了修改,我们进行持久化操作
stop-writes-on-bgsave-error yes #持久化如果出错,是否还需要继续工作
rdbcompression yes #是否压缩rdb文件,需要消耗一些CPU资源
rdbchecksum yes #保存rdb文件的时候,进行错误的检查校验
dir ./ # rdb文件的保存目录
安全
requirepass SB#jiushi5 # 设置密码
限制
maxclients 10000 #连接上redis的最大客户端数
# maxmemory <bytes> #redis 配置的最大容量
# maxmemory-policy noeviction #内存到达上限后的处理策略
1、volatile-lru:只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
3、volatile-random:随机删除即将过期key
4、allkeys-random:随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 永不过期,返回错误
append only模式 aof配置
appendonly no #默认是不开启aof模式的,默认使用的rdb方式持久化
appendfilename "appendonly.aof" #持久化文件名
# appendfsync always #每次修改都会同步 消耗性能
appendfsync everysec #每秒执行一次
# appendfsync no #不执行同步操作系统会自己同步数据,速度最快!
持久化
- rdb
优点
1.适合大规模的数据恢复
2.对数据的完整性要求不高
缺点
1.需要一定的时间间隔进行操作,如果意外宕机了,最后一次修改的数据就会丢失
2.fork子进程的时候会占用一定的内存空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号