

库
os:
介绍:os是python中的标准的库 它常用于路径的操作,获取系统、环境变量等。
使用的时候时候需要导入 这个库 import os
路径操作:
获取当前路径
print(os.getcwd())
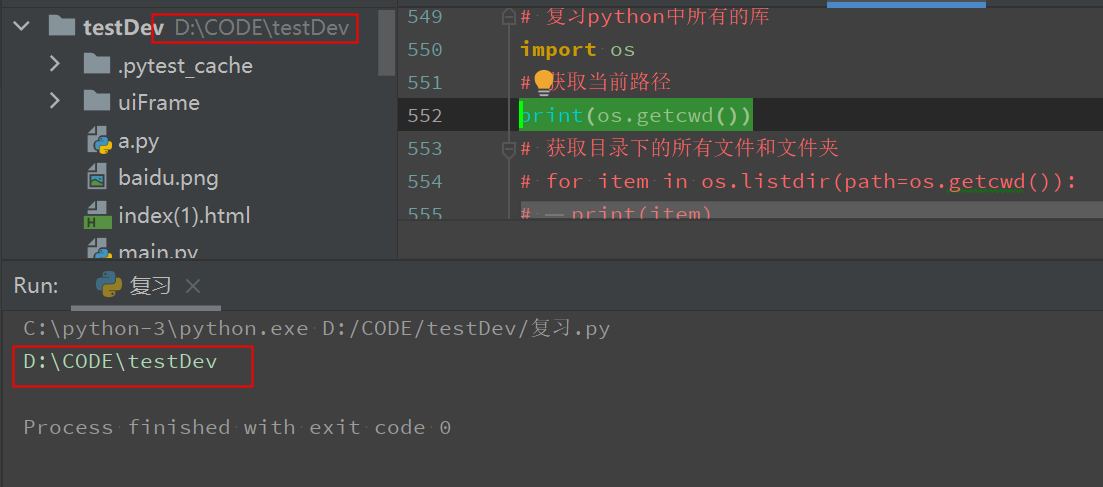
获取目录下的所有文件和文件夹
for item in os.listdir(path=os.getcwd()): print(item)
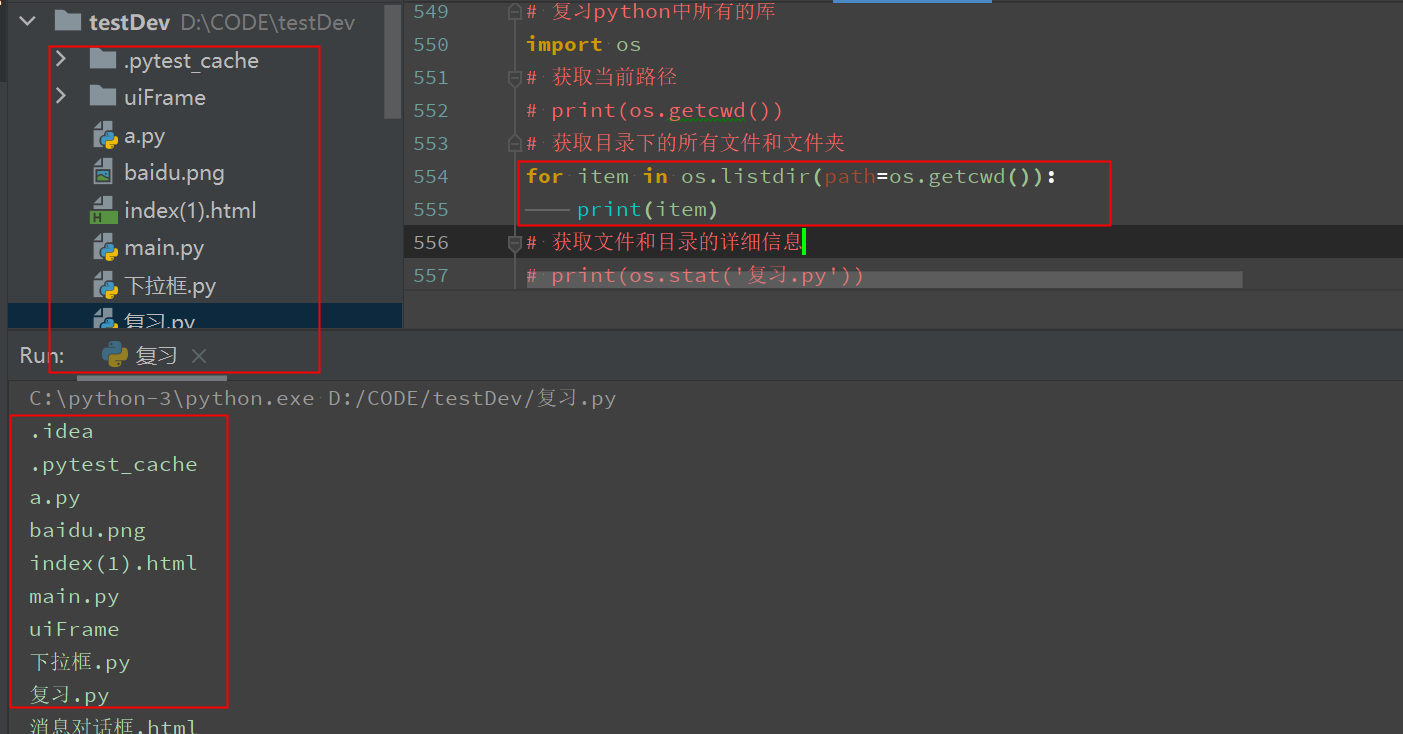
获取文件和目录的详细信息
print(os.stat('复习.py'))

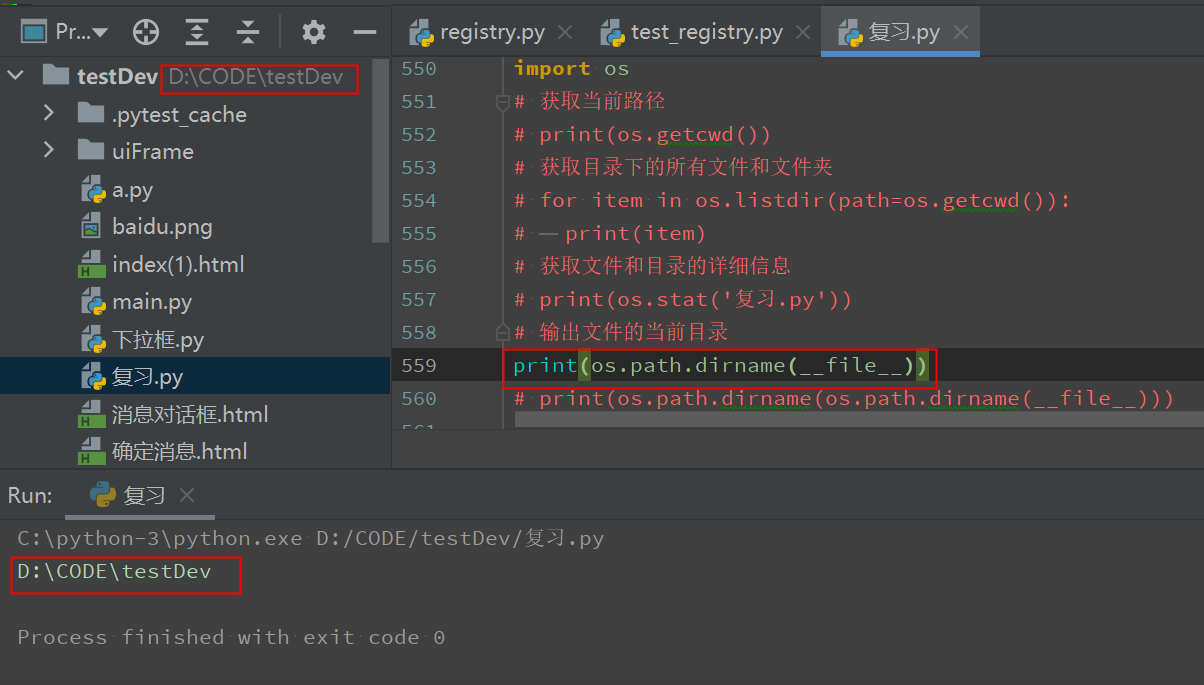
输出文件的当前目录
print(os.path.dirname(__file__))
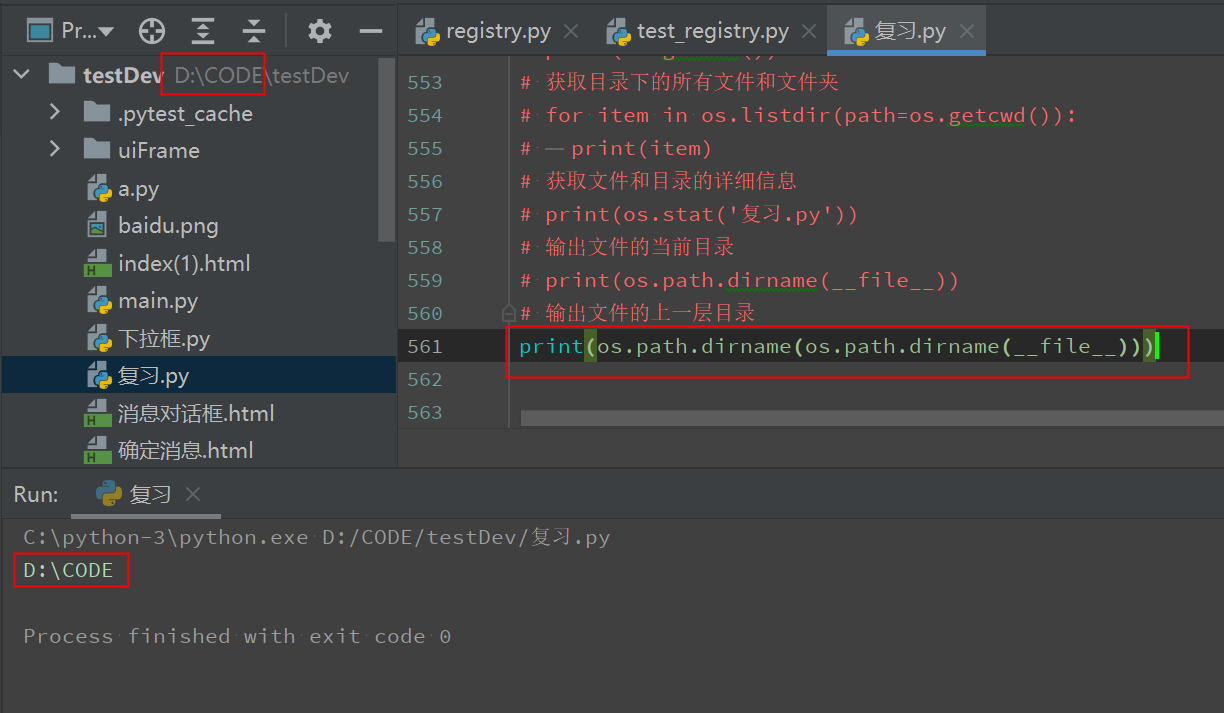
输出文件的上一层目录
print(os.path.dirname(os.path.dirname(__file__)))
路径的拼接:
场景:想要在本页面读取index文件夹里面的login.txt文件:
思路:
1、获取将要读取文件的路径(首先我们需要获取读取文件所在文件夹的目录,然后再拼接目录)
2、用 with open 读取文件(每个文件的读取都是需要关闭的,with open是自动关闭的)
base_dir=os.path.dirname(__file__) # print(base_dir) filePath=os.path.join(base_dir,'index','login.txt') # print(filePath) with open(filePath,'r',encoding='utf-8')as f: print(f.read())
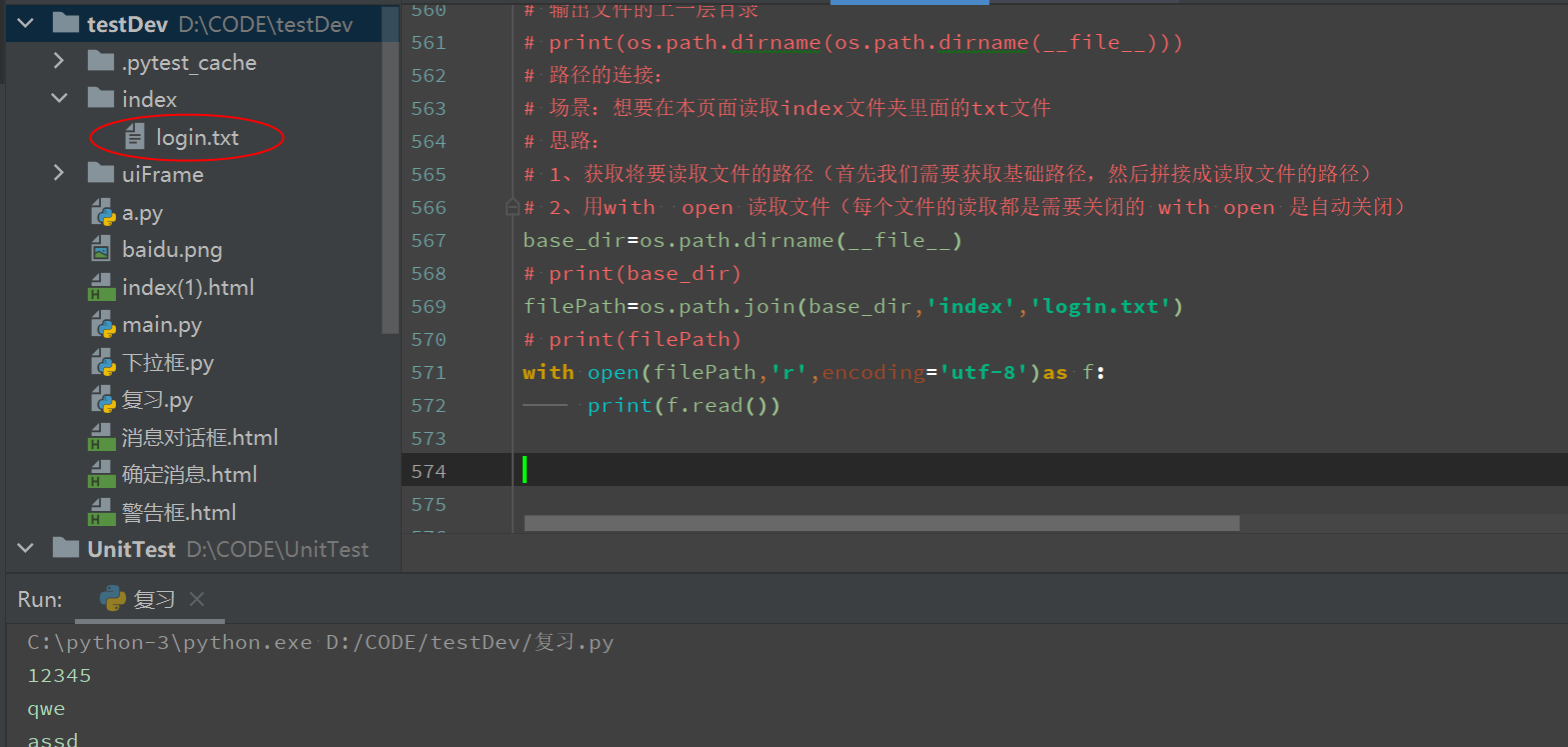
获取操作系统
# 获取操作系统 print(os.name)
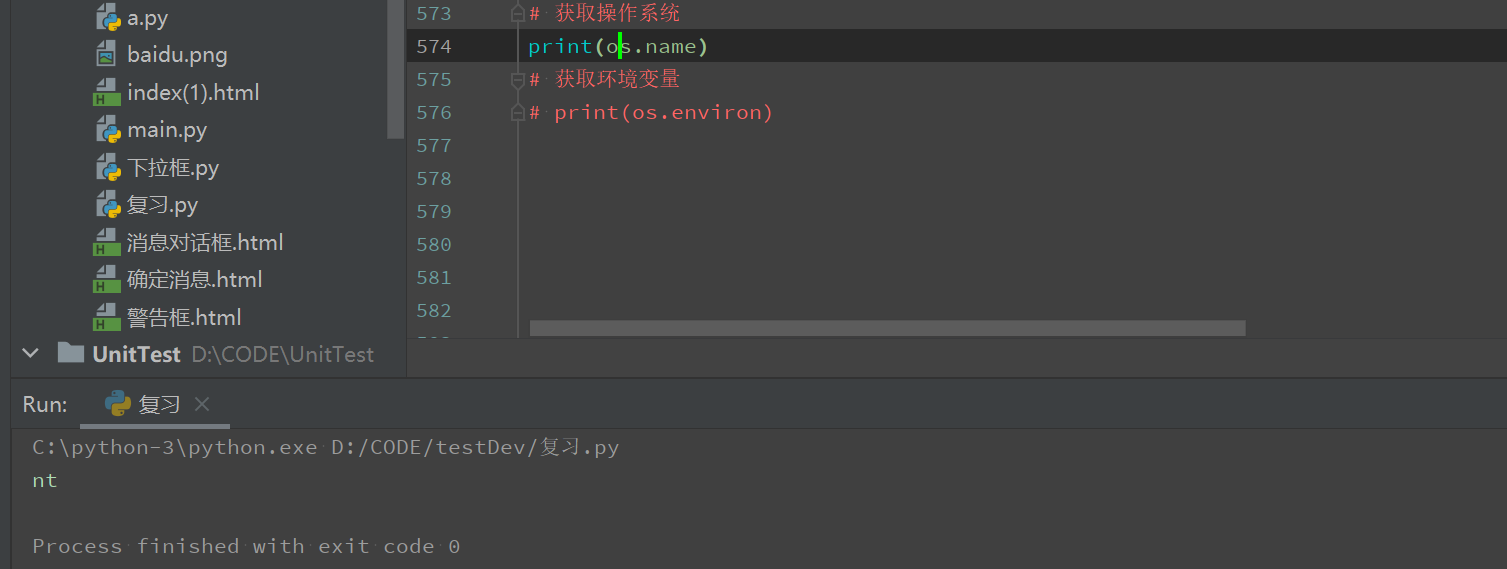
获取环境变量
# 获取环境变量 print(os.environ)
time:
介绍:提供了各种与时间相关的库,一般在使用前也是需要导入的
import time
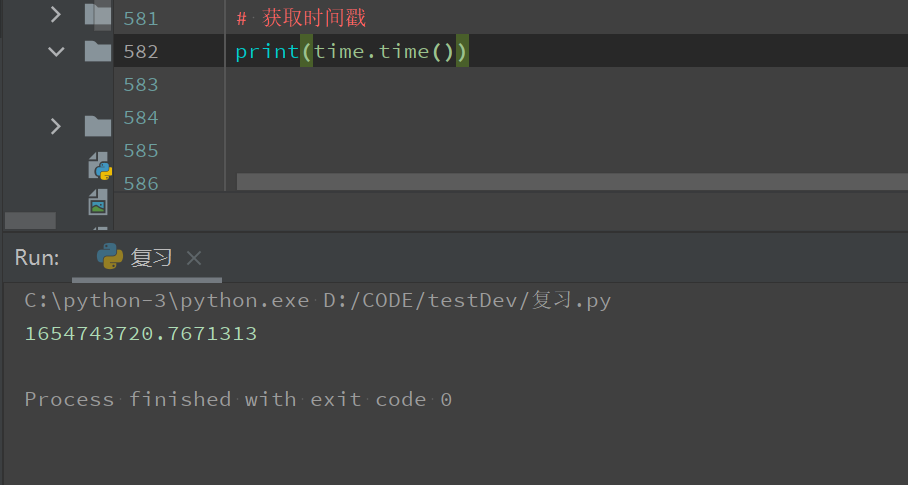
获取时间戳
print(time.time())
获取当前的时间
print(time.ctime())
休眠
--以下案例代表的是 休眠3s,再输出
# 休眠--以下案例代表的是 休眠3s,再输出 time.sleep(3) print('时间就是生命')
获取当前的系统时间
# 获取当前的系统时间 localTime=time.localtime(time.time()) print(localTime)
获取当前的时间,并且格式化的输出
# 获取当前的时间 并且格式化输出 localTime=time.localtime(time.time()) print('{0}年{1}月{2}日'.format(localTime.tm_year,localTime.tm_mon,localTime.tm_mday))
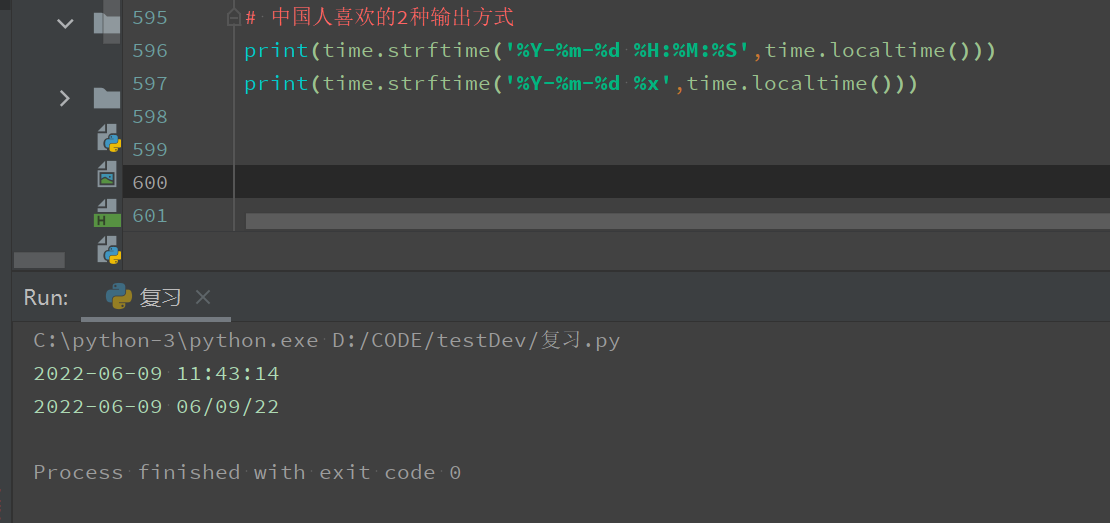
中国人喜欢的2种输出方式
# 中国人喜欢的2种输出方式 print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())) print(time.strftime('%Y-%m-%d %x',time.localtime()))
json:
序列化:就是把内存里的数据类型转换成字符串的数据类型
反序列化:就是把字符串的数据类型转化成Python对象的过程
同样:用的时候需要导入
import json
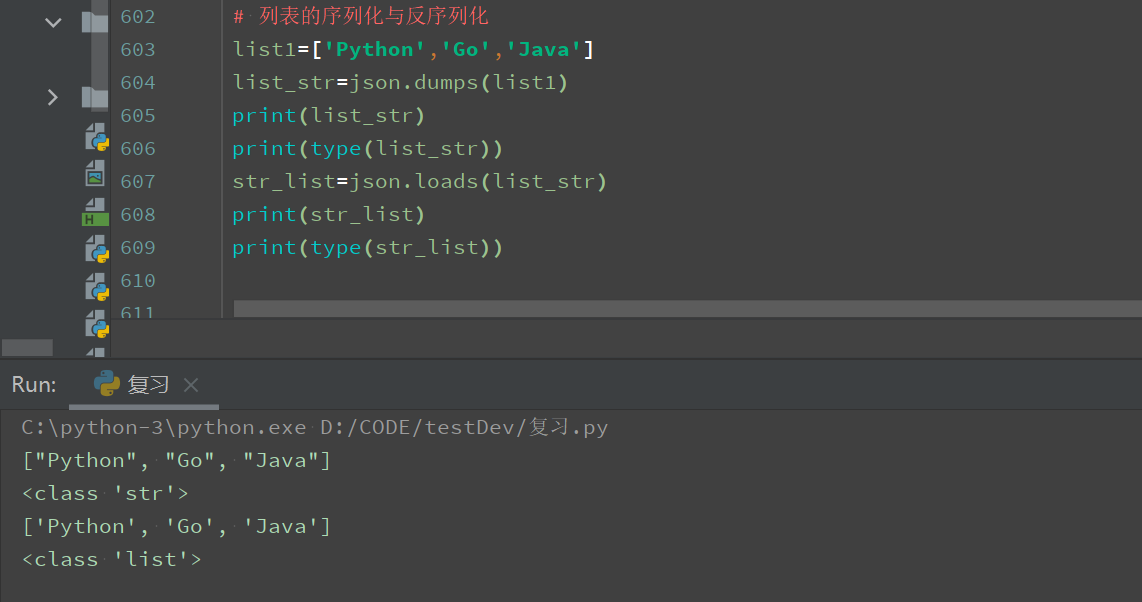
列表的序列化和反序列化
# 列表的序列化与反序列化 list1=['Python','Go','Java'] list_str=json.dumps(list1) print(list_str) print(type(list_str)) str_list=json.loads(list_str) print(str_list) print(type(str_list))
![]() 元组的序列化与反序列化
元组的序列化与反序列化
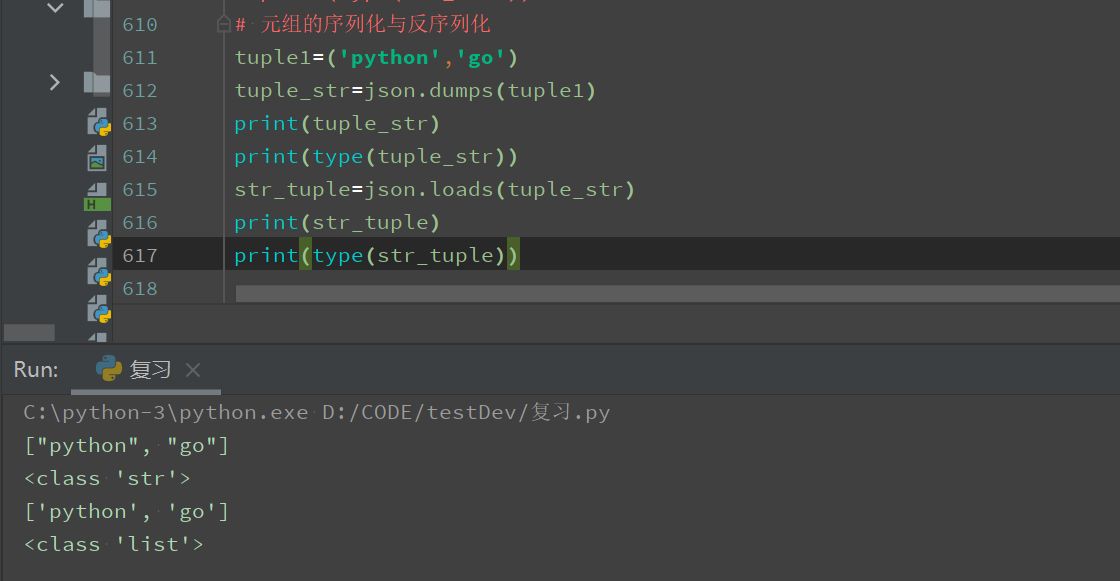
 元组的序列化与反序列化
元组的序列化与反序列化:元组的反序列化输出的是列表类型
# 元组的序列化与反序列化 tuple1=('python','go') tuple_str=json.dumps(tuple1) print(tuple_str) print(type(tuple_str)) str_tuple=json.loads(tuple_str) print(str_tuple) print(type(str_tuple))
![]() 字典的序列化与反序列化
字典的序列化与反序列化
 字典的序列化与反序列化
字典的序列化与反序列化# 字典的序列化与反序列化 dict1={'name':'xiaoming','age':19} dict_str=json.dumps(dict1) print(dict_str) print(type(dict_str)) str_dict=json.loads(dict_str) print(str_dict) print(type(str_dict))
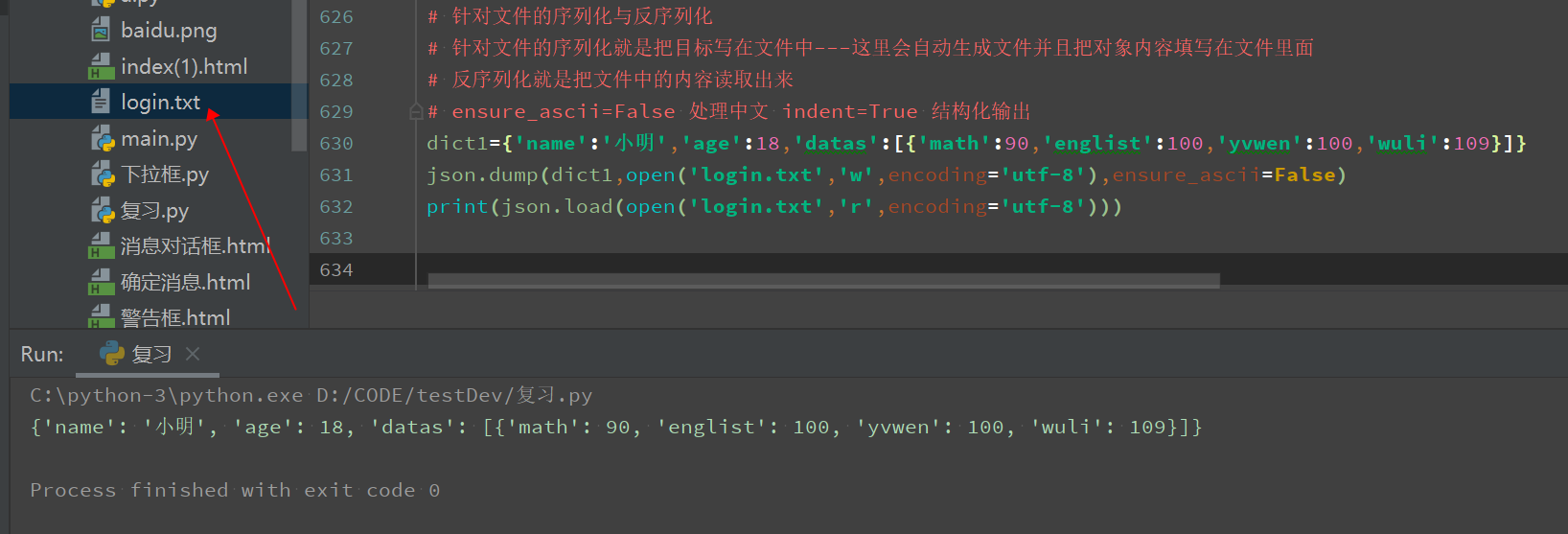
针对文件的序列化与反序列化
# 针对文件的序列化与反序列化 # 针对文件的序列化就是把目标写在文件中---这里会自动生成文件并且把对象内容填写在文件里面 # 反序列化就是把文件中的内容读取出来 # ensure_ascii=False 处理中文 indent=True 结构化输出 dict1={'name':'小明','age':18,'datas':[{'math':90,'englist':100,'yvwen':100,'wuli':109}]} json.dump(dict1,open('login.txt','w',encoding='utf-8'),ensure_ascii=False) print(json.load(open('login.txt','r',encoding='utf-8')))
![]() datetime
datetime
 datetime
datetime这个也是表示的是时间,但是和time相比,这个表现的更为直观
同样也是需要导入的
import datetime
# datetime 也是表示的是时间,但是比time更加的直观 import datetime # 获取当前的时间 print(datetime.datetime.now()) # 在当前的基础上增加几天(这个不能应用于年) print(datetime.datetime.now()+datetime.timedelta(days=10)) # 时间戳转换格式 print(datetime.datetime.fromtimestamp(time.time()))
hashlib
主要是设计md5的加密算法
这个在用的时候也是需要导入的
import hashlib
由于主要用于的是md5的加密 ,所以过程中需要转码成 所以还需要导入
from urllib import parse
urllib:主要是做网络爬虫的
思路:
1、用key对它字典形式的请求参数进行排序
2、排序完进行转码:转成key=value&key=value......格式
3、进行md5加密
import hashlib from urllib import parse def sing(): dict1={'name':'wuya','age':18,'work':'testDev','time':time.time()} # 对上面的字段进行排序 data=dict(sorted(dict1.items(),key=lambda item:item[0])) # 对排完序的字典进行转码,转换成的格式:age=18&name=wuya&time=1654760575.0412667&work=testDev data=parse.urlencode(data) # print(data) # 使用hashlib m=hashlib.md5() #指定需要加密的字符串,并及进行加密 m.update(data.encode('utf-8')) # 返回的16进制的数据 return m.hexdigest() print(sing())

sys
sys库时用来处理python运行时环境的
selenium
应用于web应用程序的自动化测试工具,它直接运行在浏览器中,可以模拟用户的行为操作,
步骤:
1、导入库
2、对库进行实例化并且指定浏览器’
3、导航到被测试网址
4、定位元素(8大方法)
5、退出这个程序
from selenium import webdriver import time as t driver=webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(30) driver.get('https://www.baidu.com/') driver.find_element_by_id('kw').send_keys('自动化测试') t.sleep(3) driver.quit()
unittest
单元测试框架
提供了创建测试用例,测试套件和批量执行测试用例的方案,有断言,最终生成测试报告
里面包含了:测试固件 测试用例 测试套件 测试执行 测试报告
from selenium import webdriver import time as t import unittest class BaiduTest(unittest.TestCase): def setUp(self) -> None: self.driver=webdriver.Chrome() self.driver.maximize_window() self.driver.get('https://www.baidu.com/') self.driver.implicitly_wait(30) def tearDown(self) -> None: self.driver.quit() def test_baidutitle(self): # 验证百度的title self.assertEqual(self.driver.title,'百度一下,你就知道') t.sleep(3) if __name__ == '__main__': unittest.main(verbosity=2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号