


序列化组件
一、序列化组件的简单使用
1、作用
把python中的对象转成json格式的字符串,一定要注意,如果前后端分离,json不能序列化对象,只能序列化列表和字典,所以这时候就用到了序列化组件
2、使用
①先在settings里注册rest_frameword

②新建一个py文件,序列化类继承Serializer,在类中写要序列化的字段
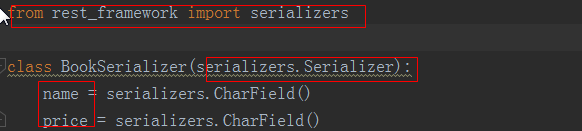
③在视图函数中使用序列化的类
from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from app01.myser import BookSerializer # 把对象转成json格式字符串 class Books(APIView): def get(self, request): response = {'code': 100, 'msg': '查询成功'} books = models.Book.objects.all() # 如果序列化多条,many=True(也就是queryset对象,就需要写) # 如果序列化一条(可以不写),instance是要序列化的对象,
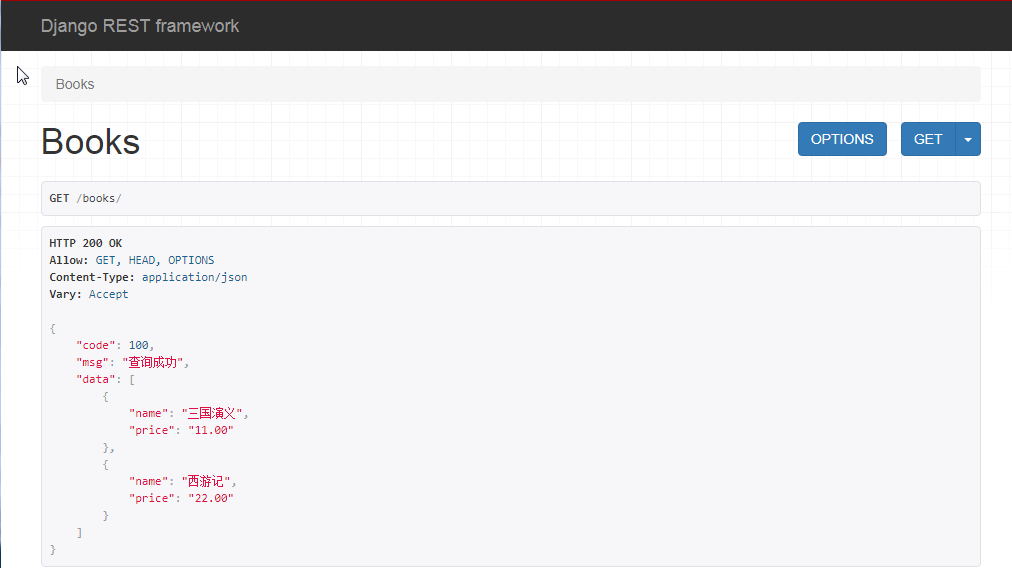
# 实例化产生一个序列化类的对象 bookser = BookSerializer(instance=books, many=True) print(bookser.data) # [OrderedDict([('name', '三国演义'), ('price', '11.00')]), OrderedDict([('name', '西游记'), ('price', '22.00')])] print(type(bookser.data)) # <class 'rest_framework.utils.serializer_helpers.ReturnList'> response['data'] = bookser.data return Response(response)
前端显示:
二、高级用法
1、source:可以指定字段(name,publish.name),可以指定方法
①source='name'


②source='publish.name'

要拿choices的中文名,必须要指定source='get_字段名_display'

③source指定方法:可以和SerializerMethodField搭配使用(get_字段名字)


2、write_only:序列化时,不显示(后端序列化到前端不显示)
read_only:反序列化时,不传(read_only=True 就是前段传给后端可以不传)

3、反序列化的使用:json格式转成对象,保存到数据库
Serializers的子类需要重写create方法(新增数据),自己写保存逻辑
在序列化类当中,如果不写create方法会调父类的create方法,直接进入父类的create方法,但是会直接抛异常,所以必须重写create方法,会把校验通过的数据传过来,然后再返回
在序列化类中:
def create(self, validated_data): res = models.Book.objects.create(**validated_data) return res
在视图函数中:继承了Serializers序列化类的对象,反序列化
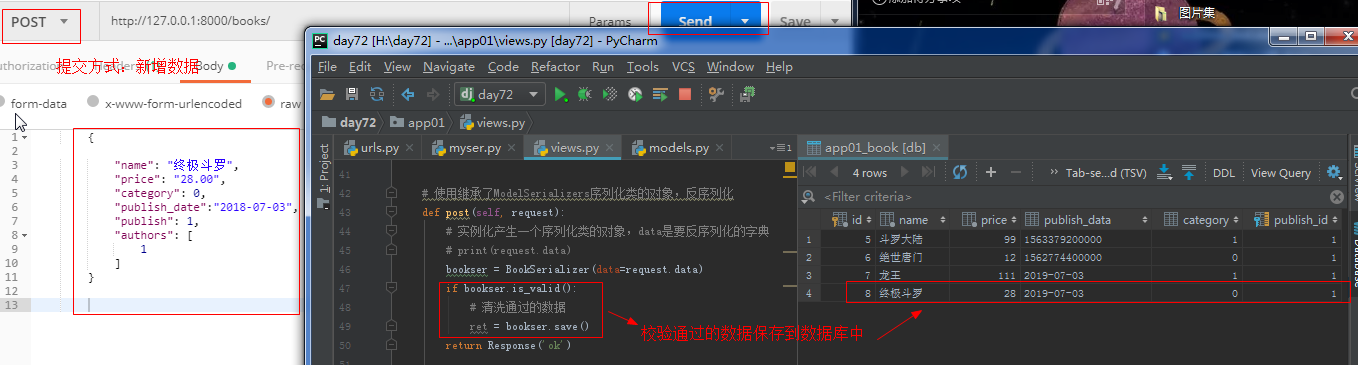
def post(self, request): # 实例化产生一个序列化类的对象,data是要反序列化的字典 bookser = BookSerializer(data=request.data) # 这里的data指的是反序列化的字典 if bookser.is_valid(): # 清洗通过的数据,校验通过之后才会调用create方法 # 注意:重写create方法的时候,一定要先校验通过了之后才能调用create方法 res = bookser.create(bookser.validated_data) return Response()
Postman新增数据:

三、序列化的两种方式
1、Serializers:没有指定表模型。以上的用法都是这种方式
模型表:


from django.db import models # Create your models here. class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=8, decimal_places=2) publish_data = models.DateField(null=True) category = models.IntegerField(choices=((0, '文学类'), (1, '情感类')), default=1, null=True) publish = models.ForeignKey(to='Publish', null=True) authors = models.ManyToManyField(to='Author') def __str__(self): return self.name class Publish(models.Model): name = models.CharField(max_length=32) city = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() def __str__(self): return self.name
在序列化类中:
from app01 import models from rest_framework import serializers class AuthorSerializer(serializers.Serializer): name = serializers.CharField() age = serializers.CharField() class BookSerializer(serializers.Serializer): # source可以指定字段(name, publish.name),可以指定方法 # 指定source='name' ,表示序列化模型表中的name字段,重名命为name5(name和source='name'指定的name不能重名) # name_book = serializers.CharField(source='name') name = serializers.CharField() price = serializers.CharField() # write_only序列化的时候,该字段不显示 # price = serializers.CharField(write_only=True) # 如果要取出版社的name,指定source='publish.name' # publish = serializers.CharField(source='publish.name') # 要拿choices的中文名,必须要指定source='get_字段名_display' book_type = serializers.CharField(source='get_category_display') # source指定方法 # 序列化出版社的详情,指定SerializerMethodField之后,可以对应一个方法,返回什么内容,publish_detail就是什么内容 # read_only,反序列化的时候,该字段不传 publish_detail = serializers.SerializerMethodField(read_only=True) # 对应的方法固定写法get_字段名 def get_publish_detail(self, obj): return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email} # 返回作者所有信息 authors = serializers.SerializerMethodField() def get_authors(self, obj): # 这里可以用列表推导式,我们还可以在视图函数中使用序列化的类, # 序列化类继承Serializer,在类中写要序列化的字段 authorser = AuthorSerializer(obj.authors.all(), many=True) return authorser.data def create(self, validated_data): res = models.Book.objects.create(**validated_data) return res
在视图函数中:
from django.shortcuts import render, HttpResponse # Create your views here. from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from app01.myser import BookSerializer # 把对象转成json格式字符串 class Books(APIView): def get(self, request): response = {'code': 100, 'msg': '查询成功'} books = models.Book.objects.all() # 如果序列化多条,many=True(也就是queryset对象,就需要写) # 如果序列化一条(可以不写),instance是要序列化的对象 bookser = BookSerializer(instance=books, many=True) # print(bookser.data) # [OrderedDict([('name', '三国演义'), ('price', '11.00')]), OrderedDict([('name', '西游记'), ('price', '22.00')])] # print(type(bookser.data)) # <class 'rest_framework.utils.serializer_helpers.ReturnList'> response['data'] = bookser.data return Response(response) def post(self, request): # 实例化产生一个序列化类的对象,data是要反序列化的字典 bookser = BookSerializer(data=request.data) if bookser.is_valid(): # 清洗通过的数据,校验通过之后才会调用create方法 # 注意:重写create方法的时候,一定要先校验通过了之后才能调用create方法 res = bookser.create(bookser.validated_data) return Response()
2、ModelSerializers:指定了表模型
使用serializer需要写很多字段,尽可能简洁的就要使用ModelSerializer


3、反序列化的使用:json格式转成对象,保存到数据库
ModelSerializers的子类,直接save
在序列化类中:
class BookSerializer(serializers.ModelSerializer): class Meta: model = models.Book # model=表模型 fields = ('__all__') # 要显示所有的字段
在视图函数中:使用继承了ModelSerializers序列化类的对象,反序列化(新增数据)
# 使用继承了ModelSerializers序列化类的对象,反序列化 def post(self, request): # 实例化产生一个序列化类的对象,data是要反序列化的字典 # print(request.data) bookser = BookSerializer(data=request.data) if bookser.is_valid(): bookser.save() return Response('ok')
前端显示:
四、反序列化的校验
1、局部校验
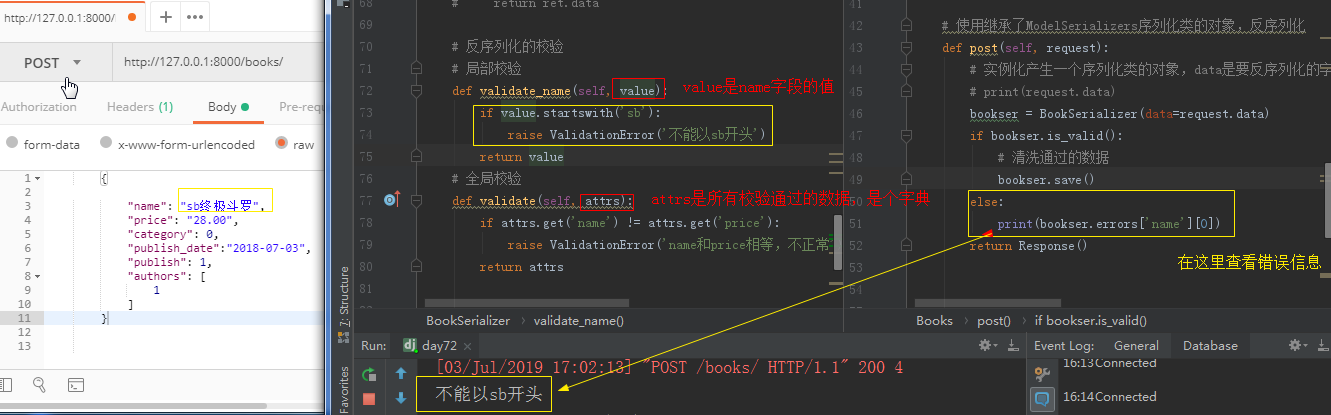
from rest_framework.exceptions import ValidationError
def validate_name(self, value): # validate_字段名(self,value): value是字段的值 if value.startswith('sb'): raise ValidationError('不能以sb开头') # 如果校验失败,抛出ValidationError(抛出的异常信息需要去bookser.errors中取) return value # 如果校验通过直接return value
2、全局校验
def validate(self, attrs): # attrs是所有校验通过的数据,是个字典 if attrs.get('name') != attrs.get('price'): raise ValidationError('name和price相等,不正常') # 如果校验失败,抛出ValidationError return attrs # 如果校验通过直接return attrs
总结:
在开发REST API接口时,我们在视图中需要做的最核心的事是:
将数据库数据序列化为前端所需要的格式,并返回;将前端发送的数据反序列化为模型类对象,并保存到数据库中。
-序列化组件 -使用drf的序列化组件 -1 新建一个序列化类继承Serializer -2 在类中写要序列化的字段 -在视图中使用序列化的类 -1 实例化序列化的类产生对象,在产生对象的时候,传入需要序列化的对象(queryset) -2 对象.data -3 return Response(对象.data) -高级用法: -source:可以指定字段(name publish.name),可以指定方法, -SerializerMethodField搭配方法使用(get_字段名字) publish_detail=serializers.SerializerMethodField(read_only=True) def get_publish_detail(self,obj): return {'name':obj.publish.name,'city':obj.publish.city} -read_only:反序列化时,不传 -write_only:序列化时,不显示 -重写create方法,实现序列化 -在序列化类中: def create(self, validated_data): res = models.Book.objects.create(**validated_data) return res -在视图函数中: def post(self, request): # 实例化产生一个序列化类的对象,data是要反序列化的字典 bookser = BookSerializer(data=request.data) if bookser.is_valid(): # 清洗通过的数据,校验通过之后才会调用create方法 # 注意:重写create方法的时候,一定要先校验通过了之后才能调用create方法 res = bookser.create(bookser.validated_data) return Response() -序列化的两种方式 -Serializers:没有指定表模型 -source:指定要序列化哪个字段,可以是字段,可以是方法 - SerializerMethodField的用法 authors=serializers.SerializerMethodField() def get_authors(self,obj): ret=AuthorSerializer(instance=obj.authors.all(),many=True) return ret.data -ModelSerializers:指定了表模型 class Meta: model=表模型 #要显示的字段 fields=('__all__') fields=('id','name') #要排除的字段 exclude=('name') #深度控制 depth=1 -重写某个字段 在Meta外部,重写某些字段,方式同Serializers -反序列化 -使用继承了Serializers序列化类的对象,反序列化 -在自己写的序列化类中重写create方法 -重写create方法,实现序列化 -在序列化类中: def create(self, validated_data): ret=models.Book.objects.create(**validated_data) return ret -在视图中: def post(self,request): bookser=BookSerializer(data=request.data) if bookser.is_valid(): ret=bookser.create(bookser.validated_data) return Response() -使用继承了ModelSerializers序列化类的对象,反序列化 -在视图中: def post(self,request): bookser=BookSerializer(data=request.data) if bookser.is_valid(): ret=bookser.save() return Response() -反序列化的校验 -validate_字段名(self,value): value是当前传过来字段的值 如果校验失败,抛出ValidationError(抛出的异常信息需要去bookser.errors中取) 如果校验通过直接return value -validate(self,attrs): attrs所有校验通过的数据,是个字典 如果校验失败,抛出ValidationError 如果校验通过直接return attrs -读一读源码 -全局和局部钩子源码部分 -在序列化的时候,传many=True和many=False,生成的对象并不是一个对象 -bookser.data -之前执行过,直接返回 -get_attribute(instance, self.source_attrs) -self.source_attrs 是source指定的通过 . 切分后的列表 -instance 当前循环到的book对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号