


kettle将数据加载到hadoop集群
1..将数据加载到HDFS
a)启动Hadoop,创建Job,把文件放进Hadoop
b)在桌面上打开PDI(kettle):选择“文件(file)”-“新建(new)”-“job”
c)添加启动项工作:你需要告诉PDI从哪开始的Job,所以点开设计面板的“常规”部 分,将一个“start”作业项放到右边面板
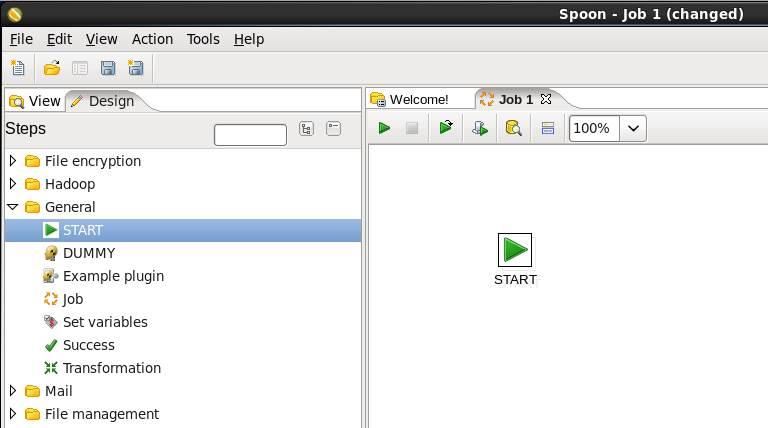
c)添加hadoop copy files Job输入:从本地磁盘复制到Hdfs,点开“Big Data”,将“hadoop copy files”的Job放到右边工作区
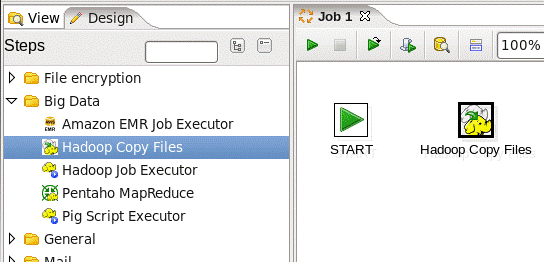
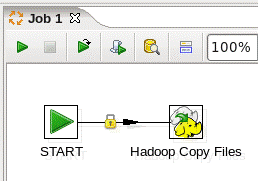
d)连接“start和hadoop copy files”
e)编辑“hadoop copy files”,双击“hadoop copy files”,输入以下信息:
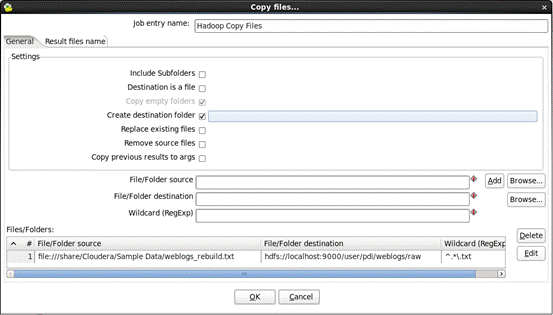
1.Wildcard (RegExp):输入 ^.*\.txt
2.单击“ADD”将需要的files列表添加进去
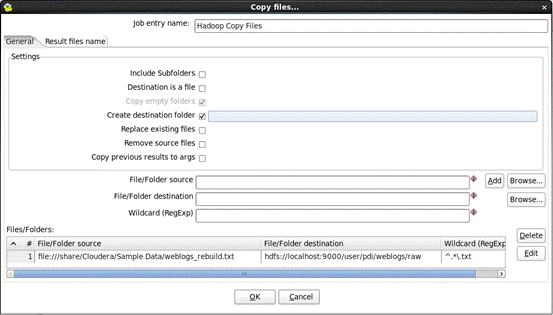
f)保存工作:选择“File”->“save as。。。”从系统菜单,转型为 “load_hdfs.kjb”保存到选择的文件夹。
G)运行job:从菜单系统选择“Action”->“Run”或者绿色运行按 钮。一个“Execute a job”窗口,执行完之后,可以使用“Execution Results”查看错误信息

H)问题:
Problem:Permission denied:user=xxxx, access=Excute, inode=”/user/pdi/weblogs/raw”:raw:hadoop:drwxr-x---
权限被拒绝:无论在连接什么使用用户名时,要更改用户必须设 置环境变量HADOOP_USER_NAME.可以通过更改opt变量 spoon.bat或者spoon.sh:
OPT=”$OPT....-DHADOOP_USER_NAME=HadoopNameToSpoof”
2.简单的chrome拓展浏览HDFS volumes
3.将数据加载到Hive
a) 建立:启动Hadoop,启动Hive server
b) 创建一个Hive表:
1.打开Hive shelll写一个“hive”在command line
2.在hive中创建表:在hive shell中输入
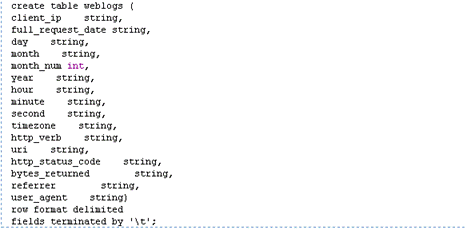
3.输入“quit”关闭hive shell
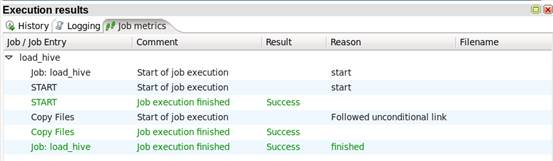
c) 创建一个job来加载Hive
1.同上
2.同上
3.同上
4.同上
d) 编辑“hadoop copy files”,双击“hadoop copy files”,输入以下信 息:
1.Wildcard(RegExp)通配符:输入’part-.*’
2.点击“add”
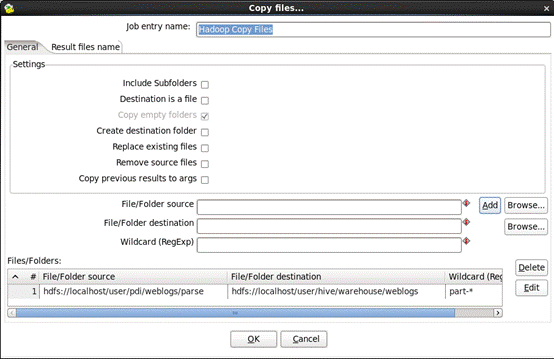
3.保存job,选择“Flie”->“save as...”
4.将数据加载到Hbase
A)启动hadoop,启动hbase
1.打开Hbase shell
2.创建表在Hbase中
3.关闭hbase shell
B)创建一个Transformation来加载数据到Hbase
1.“File”->“New”-“Transformation”
2.打开“Input”->“Text file input”
3.点击“Add”
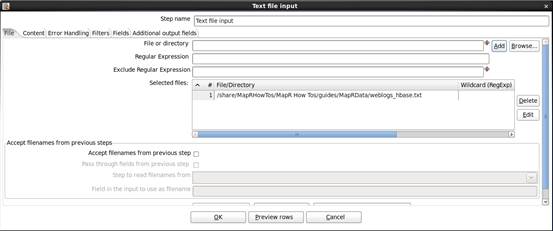
格式选择“Unix”
