

C尖笔记
2025.11.14
你提出的判断题“一维数组定义的一般形式如下,其中的类型名指定数组变量的类型。”的正确答案是 F(错误)。
下面对此进行解释。
核心概念辨析
在一维数组的定义形式 类型名 数组名[数组长度]; 中,关键在于理解 “类型名”指的是什么。
- 正确的理解:
类型名指定的是数组中每个元素的数据类型,而不是整个“数组变量”的类型。例如,在定义int a[10];时,int表明数组a的每一个元素(a[0],a[1], ...,a[9])都是基本int类型。 - 数组变量的类型:数组本身作为一种复合数据类型,其完整的类型是由“元素类型”和“数组长度”共同决定的。以上面的
int a[10];为例,数组变量a的完整类型是“包含10个整型元素的数组类型”,这通常写作int [10]。
为了更清晰地展示这个区别,请看下表:
| 定义语句 | 类型名 的含义(元素类型) |
数组变量的实际类型 |
|---|---|---|
float scores[30]; |
float |
float [30] |
char name[20]; |
char |
char [20] |
为什么这是易错点
这个判断题是一个经典的概念陷阱。它利用了“类型名”这个词汇可能带来的模糊理解。初学者很容易认为“定义变量,前面的词当然指定变量类型”,从而判断为正确(T)。但实际上,数组是一种特殊的数据结构,它包含多个相同类型的元素,因此在定义时需要首先明确其基础构建块(即元素)的类型。
希望这个解释能帮助你更好地理解数组的定义!如果对数组的其他概念还有疑问,可以随时提出。
2025.11.12
'\08'是错误的字符常量,但是实际上编译器会把它解析成一个\0和一个8,报错也是报multi-character constant不是invalid digit 8 in octal constant。
验证实例:
#include <stdio.h>
int main() {
char str[] = "\08";
printf("Length: %zu\n", sizeof(str)); // 输出:3(包含结尾的\0)
printf("First char: %d\n", str[0]); // 输出:0(\0的ASCII)
printf("Second char: %c\n", str[1]); // 输出:8
return 0;
}
2025.11.11
C语言数组初始化-去复习。
注意数组的sizeof,如果在作用域直接调用,就可以。
传入参数:[Warning] 'sizeof' on array function parameter 'cnt' will return size of 'int *' [-Wsizeof-array-argument](原因是传参数的时候数组会退化成指针)
2025.11.7
老师给的饱和运算的std,max溢出了也无所谓,只要保证最高位是1即可。
涉及到取出每一位数,有0的时候,要么特判,要么用do-while。
C语言貌似不能用
const int N=100;
int a[N];
注意题目没说数据范围,默认都可能……
以下能正确定义数组并正确赋初值的语句是()。
A.
int N=5, b[N][N];
B.
int a[1][2]={{1}, {3}};
C.
int c[2][ ]={{1, 2}, {3, 4}};
D.
int d[3][2]={{1, 2}, {34}};
不是的,只有第一维的大小可以省略,而且必须提供足够的初始化信息让编译器能推断出第一维的大小。
规则如下:
-
一维数组:可以省略长度,编译器根据初始化的元素个数确定。
int a[] = {1, 2, 3}; // 等价于 int a[3] = {1, 2, 3}; -
二维数组:可以省略第一维(行数),但不能省略第二维(列数)。
int b[][3] = {{1,2,3}, {4,5,6}}; // 行数自动推断为 2 int c[][4] = {1, 2, 3, 4, 5, 6}; // 行数 = 6/4 向上取整 = 2 行 -
多维数组:只有第一维可以省略,后面所有维的大小必须明确指定。
int d[][2][3] = { {{{1,2,3}, {4,5,6}}}, {{{7,8,9}, {10,11,12}}} };
原因:
C 语言的数组在内存中是按行优先存储的,为了计算每个元素的地址,必须知道除第一维外其它维的大小(即一行有多少元素、一个二维面有多少元素等)。如果省略后面的维度,编译器无法计算地址偏移。
假设int类型变量占用4个字节,定义数组int a[] = {4, 6, 8, 10};,则表达式sizeof(a)的值为 16
注意没规定a的大小。
分数 2
作者 颜晖
单位 浙大城市学院
写出以下程序段的运行结果。请注意,直接填数字,前后不要加空格等任何其他字符。
int i, max_sum, n, this_sum;
int a[ ] = {-1, 3, -2, 4, -6, 1, 6, -1};
scanf("%d", &n);
max_sum = this_sum = 0;
for( i = 0; i < n; i++ ) {
this_sum += a[i];
if( this_sum > max_sum ) max_sum = this_sum;
else if( this_sum < 0 ) this_sum = 0;
}
printf("%d\n", max_sum);
输入8,输出
7
输入5,输出
5
n=8是7,不是8;
一维数组定义时,程序在栈中只分配了数组元素的存储空间,没有分配数组名的存储空间。
何意味
int a[10] = {}; // 所有10个元素都被初始化为0
以下代码段对二维数组进行初始化。
int a[3][2];
a = { {1, 2}, {3, 4}, {5, 6} };
要在定义的时候初始化,所以是错!!!
定义二维数组int a[][3] = { 1, 2, 3, 4, 5, 6 };,则sizeof(a[0])的值为sizeof(int) * 3。
true
2025.11.6

服了,得端正学习态度了……
课后作业6函数题1:又是边界问题,n=1要特判
两个字节是16位!!!
%5.2f要补空格!
sizeof里面的变量操作不会被执行
... ? ... : ... 是右结合的,比如a < b ? a : b > c ? b : c等价于a < b ? a : (b > c ? b : c),然后它如果a<b,就直接返回a了,不会去算(b>c?b:c)。
逗号运算符会返回最右边的值,条件优先级大于赋值大于逗号。
... ?... :... 会提升变量类型,两个结果会隐式类型转换。
以下程序段统计整型变量x的二进制表示中1的个数。
int x, count = 0;
scanf("%d", &x);
for (; x; x &= x - 1)
count++;
定义变量double n; 表达式sizeof(n > 0 ? 1 : -1.f)的值为sizeof(double)。
a?b:c的size只和b和c有关,与a和表达式的值无关。sizeof也不会具体计算表达式的值。b,c类型不同,会进行简单的算术类型提升。
错题:
以下代码实现输入一行字符,将大写字母转换为相应的小写字母后输出,其他字符原样输出。
while (ch = getchar() != '\n') {
if (ch >= 'A' && ch <= 'Z')
ch = ch - 'A' + 'a';
putchar(ch);
}
没加括号,ch变成布尔值了……
真得好好复习表达式求值了啊!!!

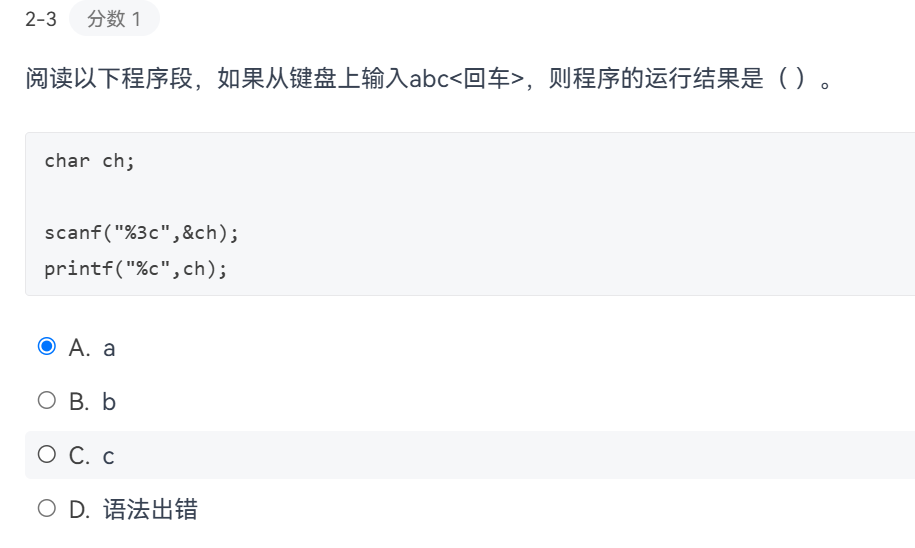
2025.11.2
写课后作业6 7-3被坑了,最后是空格的时候,最后一个单词已经输出过了……,最好的方法是在最后补上一个空格
以后要注意讨论开头和结尾有无空白字符
空格要和换行一起考虑,题目就是没说清楚……
绝对的恶心毒瘤好题。
史题。
还有一个坑,就是pta的样例貌似其实会有换行,但是并不会显示出来
- putchar如果成功输出了字符,会返回这个字符。否则返回EOF。
- 如果for的循环体语句中没有使用continue语句,则以下for语句和while语句等价。
for (表达式1; 表达式2; 表达式3)
for的循环体语句
表达式1;
while (表达式2) {
for的循环体语句;
表达式3;
}
用了continue另当别论!
- 类型转换,大转小直接截断低位;小转大:无符号整数直接高位复制0,有符号复制符号位(最高位),这样的结果就是数字的值不变,变成了更大字节下的原值的补码。
浮点数的截断也是类似的。
- 注意
while循环有时候没有自加。
若变量已正确定义,以下while循环结束时,i的值为11。
i = 1;
while (i <= 10){
printf("%d\n", i);
}
这个是错的。
- 设变量已正确定义,选项( )与以下程序段不等价。
switch(op){
case '+': printf("%d", value1 + value2);
default: printf("Error");
case '-': printf("%d", value1 - value2);
}
A.
if(op == '+'){
printf("%d", value1 + value2);
printf("Error");
}else if(op != '-'){
printf("Error");
}
printf("%d", value1 - value2);
这俩等价……
-
- 当 switch在循环内部时在循环内部的 switch语句中使用 continue会跳过当前循环迭代的剩余部分,直接开始下一次循环迭代。
- 当 switch不在循环中时,如果 switch语句不在任何循环内部,使用 continue会导致编译错误,因为 continue只能在循环结构中使用。
break在switch里面只是跳出switch,但是continue是跳到循环下一步。
for(i = 11; i <= 20; i++){
for(i = 1; i <= 10; i++){
printf( "%4d", i );
}
printf("\n");
}
看起来好像里面的i会覆盖掉外面的定义变成局部变量,不会死循环,对吧?
实际上,它是一个i,没有重新定义,所以会死循环。
-
实参是后面先计算
-
\(1 + 3 + ... + 2m-1 = m ^ 2\)
-
程序内存和机器内存不一样
常量Constan区和代码Code区都只读,不能写入,不然会报段错误。
栈是从地址高的地方开始分配。
~x+1表示-x,但是x=0时
注意负数的反码是符号位不变,其它位取反,但是C的~运算是不管符号位的,是直接所有位取反。但是~5+1,因为5本身是正数,所以~之后刚好是-5的反码,所以得出来就是-5的补码。
-
注意统计0的位数相关问题都要特判或者dowhile。
-
负数取出每一位之后本身就是负数,如果要统计位数需要取绝对值或者相反数,但是如果是反转数字符号不变反而不用特殊处理。
详见课后作业5函数题第四题。
-
可以把样例复制到代码框观察空格
-
函数是一个完成特定工作的独立程序模块,包括库函数和自定义函数两种。
-
void income(double number), expend(double number);中expend函数申明省略了函数类型,其函数类型是默认的int。
根据测试,expend函数也是void类型,这道题答案是F。
- 以下循环代码将导致死循环。
int i;
for (i = 1; i; i++)
;
好像并不会。
-
double不光精度更高,取值范围也更大。 -
浮点数整数部分的0可以省略,比如0.1可以写成.1。
没有后缀是double,有f、F后缀是float,有l、L后缀是long double。(long double精度一般80位,但是字节不一定是多少,只是规定比double大)
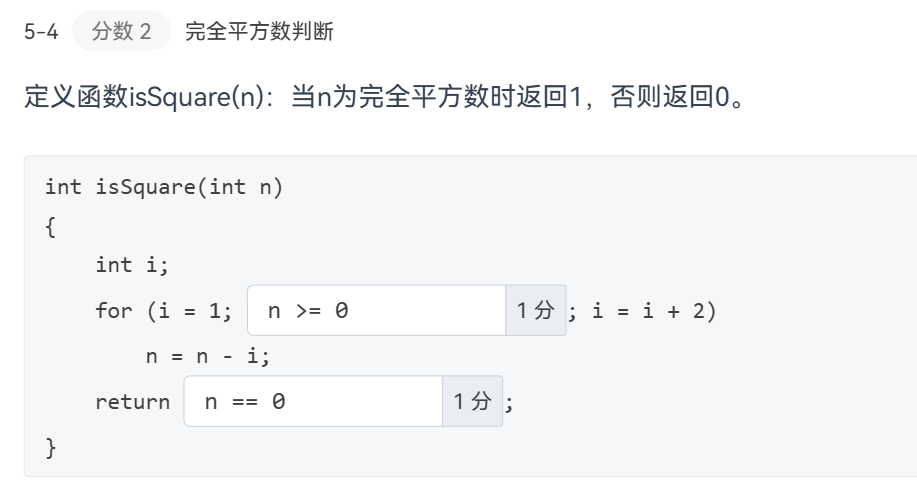
n>=0错了,因为n==0还会继续减,应该是n>0。无论何时都要检查等号!
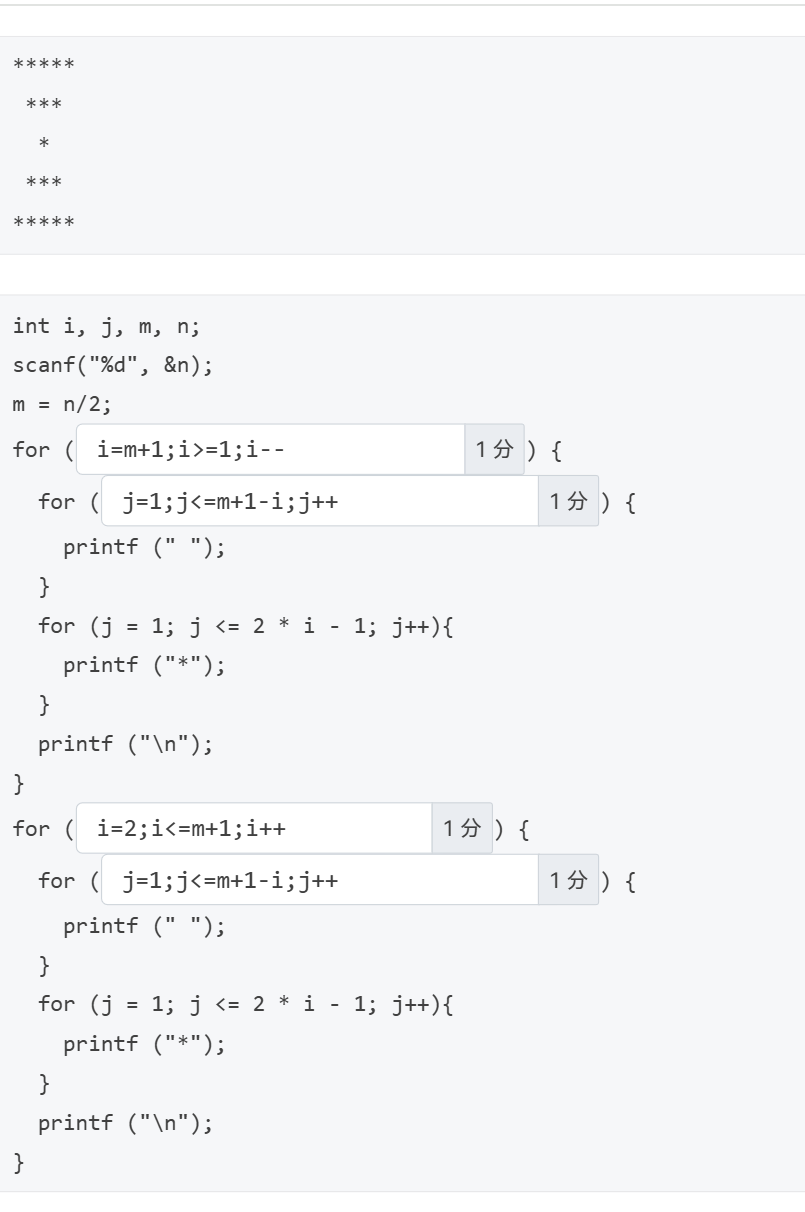
这种打印题一定要仔细看,推式子!比如下半部分本来写for (j=2;j<=i;j++)打空格,就只对了一行,下一行就错了!
- goto语句可以到
do-while循环体,但是while和for不行,因为do-while是先执行一次再判断条件是否成立。
到底这个是while和do-while主要区别,还是至少执行一次循环体,去看看答案。(课后作业5,2-2)
-
2 3 5 7 ,9不是质数!
注意16进制,如果是小写x,输出小写字母的十六进制数,大写X输出大写字母。
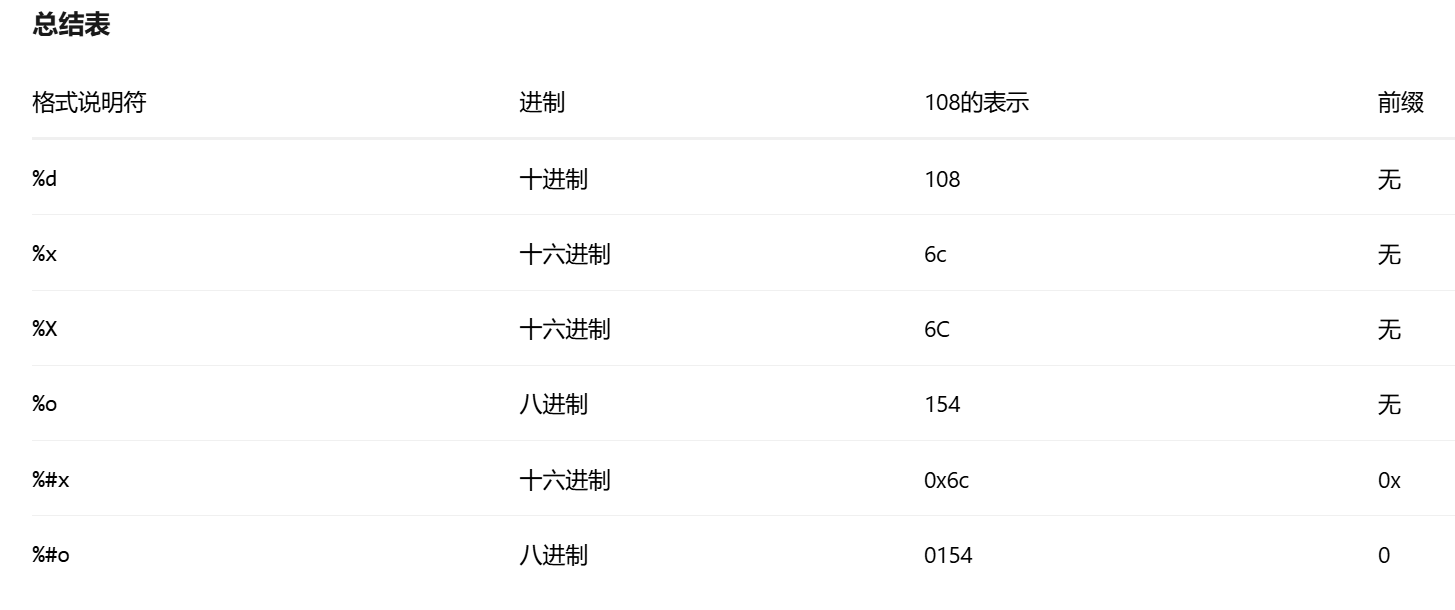
-
8进制数不能出现大于等于8的数字!!!
081会编译错误。 -
循环不光可以
break退出,还可以return和goto或者表达式不满足条件自然退出。
以下关于函数叙述中,错误的是( )。
A.函数未被调用时,系统将不为形参分配内存单元
B.实参与形参的个数必须相等,且实参与形参的类型必须对应一致
C.当形参是变量时,实参可以是变量、常量或表达式
D.如函数调用时,实参与形参都为变量,则这两个变量不可能占用同一内存空间
正确答案是 B. 实参与形参的个数必须相等,且实参与形参的类型必须对应一致
详细解析:
-
A. 正确
函数未被调用时,形参只是声明,系统不会为其分配内存单元。只有当函数被调用时,才会为形参分配临时的内存空间(栈空间)。 -
B. 错误 ?
这是错误的叙述,原因如下:- 可变参数函数(如
printf)的实参个数可以不等于形参个数// printf的形参只有1个(format字符串) // 但实参可以有多个(如%d对应的值) printf("%d %f", 10, 3.14); - 类型兼容性:实参类型可以自动转换为形参类型(如int传递给double)
void func(double x) { /*...*/ } func(10); // int自动转为double
- 可变参数函数(如
-
C. 正确
当形参是变量时:- 实参可以是变量:
func(a); - 实参可以是常量:
func(10); - 实参可以是表达式:
func(a + b * 2);
- 实参可以是变量:
-
D. 正确
在传值调用(非指针)时:- 形参是实参的副本,占用独立的内存空间
- 即使同名,也是两个不同的变量
void change(int x) { // x是形参 x = 20; // 修改不影响实参 } int main() { int a = 10; // 实参a change(a); // a和x占用不同内存 printf("%d", a); // 输出10(未改变) }
关键总结:
- B选项的错误在于忽略了C语言的两个重要特性:
- 可变参数函数(实参个数可多于形参)
- 隐式类型转换(实参类型可自动转换为形参类型)
因此B是唯一错误的叙述。其他选项均正确描述了C语言的函数参数机制
- 在C语言中,像
a = 10中的常量10的存储位置取决于它的使用场景和上下文。以下是详细的解释:
常量 10 的存储位置
-
立即数(Embedded in Instructions):
- 在大多数情况下,像
10这样的小整数常量会直接嵌入到机器指令中 - 编译器会生成类似
MOV [a], 10的指令,其中10是作为指令的一部分存在 - 这种情况下,常量不占用独立的内存空间,而是存储在代码段(text segment)
- 在大多数情况下,像
-
只读数据段(.rodata):
- 如果常量被用于全局初始化(如全局变量初始化)或作为字符串常量
- 会被存储在只读数据段(read-only data segment)
- 例如:
const int global_const = 10; // 存储在.rodata
-
静态存储区(static storage):
- 当常量用于初始化静态变量时:
static int x = 10; // 10作为初始化值,但x本身在.data段 - 这里的
10是初始化值,会被编译器处理:- 可能作为立即数嵌入指令
- 或存储在.rodata中(如果编译器需要单独存储)
- 当常量用于初始化静态变量时:
-
栈空间(stack):
- 对于局部变量初始化:
void func() { int a = 10; // 10作为立即数嵌入指令,a在栈上 } - 常量
10不占用栈空间,而是作为指令的一部分
- 对于局部变量初始化:
关键总结
| 使用场景 | 存储位置 | 是否占用内存 |
|---|---|---|
局部变量初始化(如 int a = 10;) |
代码段(作为指令的一部分) | ❌ 不单独占用 |
全局变量初始化(如 int x = 10;) |
.rodata 或 代码段 | ✅ 可能占用 |
静态变量初始化(如 static int y = 10;) |
.rodata 或 代码段 | ✅ 可能占用 |
常量表达式(如 case 10:) |
代码段 | ❌ 不单独占用 |
字符串常量(如 "hello") |
.rodata | ✅ 占用 |
特殊说明
-
小整数优化:
- 编译器通常对小整数(如
10)进行优化,直接嵌入指令而不分配内存 - 这比访问内存更高效
- 编译器通常对小整数(如
-
与
static区的区别:static区(.data/.bss)存储的是变量(如全局变量、静态变量)- 常量本身通常不存储在 static 区,除非它是:
- 字符串常量(在.rodata)
- 或用于初始化静态/全局变量(值可能被复制到.data)
-
验证示例:
#include <stdio.h> const int c = 10; // 在.rodata int main() { static int s = 10; // 初始化值可能在.rodata,s在.data int a = 10; // 10是立即数(在代码段) printf("%p %p", &c, &s); // 有地址 // printf("%p", &10); // 错误!字面值常量没有地址 }
因此,在
a = 10这样的语句中,常量10通常不存储在 static 区,而是作为指令的一部分直接嵌入代码段。只有在特定场景(如全局常量定义)才会存储在只读数据段(.rodata)。
- 以下正确的说法是()。
A.实参与其对应的形参共同占用一个存储单元
B.实参与其对应的形参各占用独立的存储单元
C.只有当实参与其对应的形参同名时才占用一个共同的存储单元
D.形参是虚拟的,不占用内存单元
答案B
- 感觉问DS单个问题还好,问题一多DS就变成sb了。。。搞得我课后作业4错这么多……
AI在复杂程序还是容易错……,以后还是先给题让它自己做,不要让它验证,要像选择题一样,他给个答案,我再去对
- 在浮点数表示中(如IEEE 754标准),“溢出”通常指的是“上溢”,而这种情况确实主要是由阶码溢出引起的。 但“溢出”也可以指“下溢”,这则不是阶码溢出。
让我们详细分析一下:
-
上溢:
- 原因: 当计算结果的绝对值太大,以至于超过了浮点数格式所能表示的最大有限数值时,就会发生上溢。
- 阶码的作用: 浮点数的阶码决定了数值的指数部分。阶码有一个最大值(对于单精度float是127)。
- 阶码溢出: 如果计算结果的指数部分需要比最大阶码值还大的阶码来表示,那么阶码本身就无法容纳这个值。这就是阶码溢出。
- 结果: 发生上溢时,计算结果会被表示为正无穷大或负无穷大(取决于符号位)。阶码的所有位会被设置为1(表示特殊值),尾数部分被设置为0。
- 结论: 上溢本质上就是阶码溢出。 阶码无法表示所需的过大指数。
-
下溢:
- 原因: 当计算结果的绝对值太小,小于浮点数格式所能表示的最小规格化正数时,就会发生下溢。
- 阶码的作用: 阶码有一个最小值(对于单精度float是-126)。
- 阶码“溢出”? 下溢发生时,计算结果需要的指数比最小阶码值还小(更负)。这看起来像是阶码“向下溢出”。
- 实际处理: 然而,IEEE 754标准通过引入非规格化数来处理这种情况。当阶码达到最小值后,如果结果继续变小,计算机会开始使用非规格化数表示(阶码固定为最小值,尾数不再隐含前导1,而是允许前导0)。这允许表示比最小规格化数更接近0的值,但精度会逐渐损失。
- 真正的下溢: 当计算结果小到连非规格化数都无法表示时(即尾数下溢),结果会被刷新为0(带符号)。
- 结论: 下溢通常不是由阶码“溢出”引起的,而是阶码已经达到最小极限后,尾数无法再表示更小的值。 阶码本身并没有“溢出”其位域(它被固定在最小值),是数值的绝对值太小了。
-
尾数溢出:
- 在浮点数加减运算中,对齐阶码后尾数相加/减时,可能会发生尾数进位溢出(例如,1.0 + 1.0 = 10.0)。
- 处理: 这种情况通过右规格化来处理:尾数右移一位(相当于除以2),阶码加1(相当于指数加1)。
- 结果: 只要阶码加1后没有超过最大值,这个操作就能修正尾数溢出,结果仍然是有效的规格化数。
- 与溢出的关系: 如果尾数溢出后,执行右规格化导致阶码超过了最大值,那么最终的结果溢出仍然是阶码溢出(上溢)导致的。
总结:
- 上溢: 是阶码溢出的直接结果。数值太大,阶码无法表示所需的指数。
- 下溢: 不是阶码溢出。数值太小,阶码已达到最小极限,尾数也无法表示该值(即使在非规格化形式下),最终结果变为0。
- 尾数溢出: 是中间计算步骤,可以通过右规格化修正,除非修正导致阶码溢出(上溢)。
因此,当你听到“float溢出”时,如果指的是数值变得过大(例如 1e38 * 10),那么答案就是是的,这主要是阶码溢出(上溢)。如果指的是数值变得过小(例如 1e-38 / 10),那么它属于下溢,不是阶码溢出。
-
char当成有符号的,unsigned char当成无符号的。 -
float精度是,double精度是……位
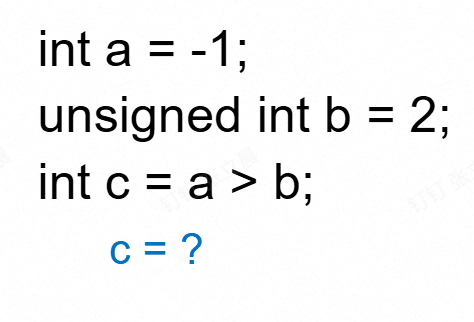
血泪史

 浙公网安备 33010602011771号
浙公网安备 33010602011771号