

学习comfyui , 加上自己的理解
-
vae模块:
vae 解码模块:
把latent -->image
输出可以连接为保存或者预览. -
VAE 节点配置与使用
模型来源
默认加载:通过 Load Checkpoint 节点加载大模型时,自动绑定其内置的 VAE。
独立加载:使用 VAE Loader 节点单独加载优化版 VAE 文件(如 vae-ft-mse-840000-ema-pruned.ckpt)以提升细节解码效果。
文生图流程:Load Checkpoint → CLIP 文本编码 → KSampler → VAE Decode → 输出。
局部重绘流程:Load Image → VAE Encode → 添加遮罩 → KSampler → VAE Decode。
clip 模块:
把文字变成 latent 向量.
一些相关学习资料
https://zhuanlan.zhihu.com/p/21381187964
这个up的系列教程可以看.比较全面.
安装包:
https://zhuanlan.zhihu.com/p/795557240
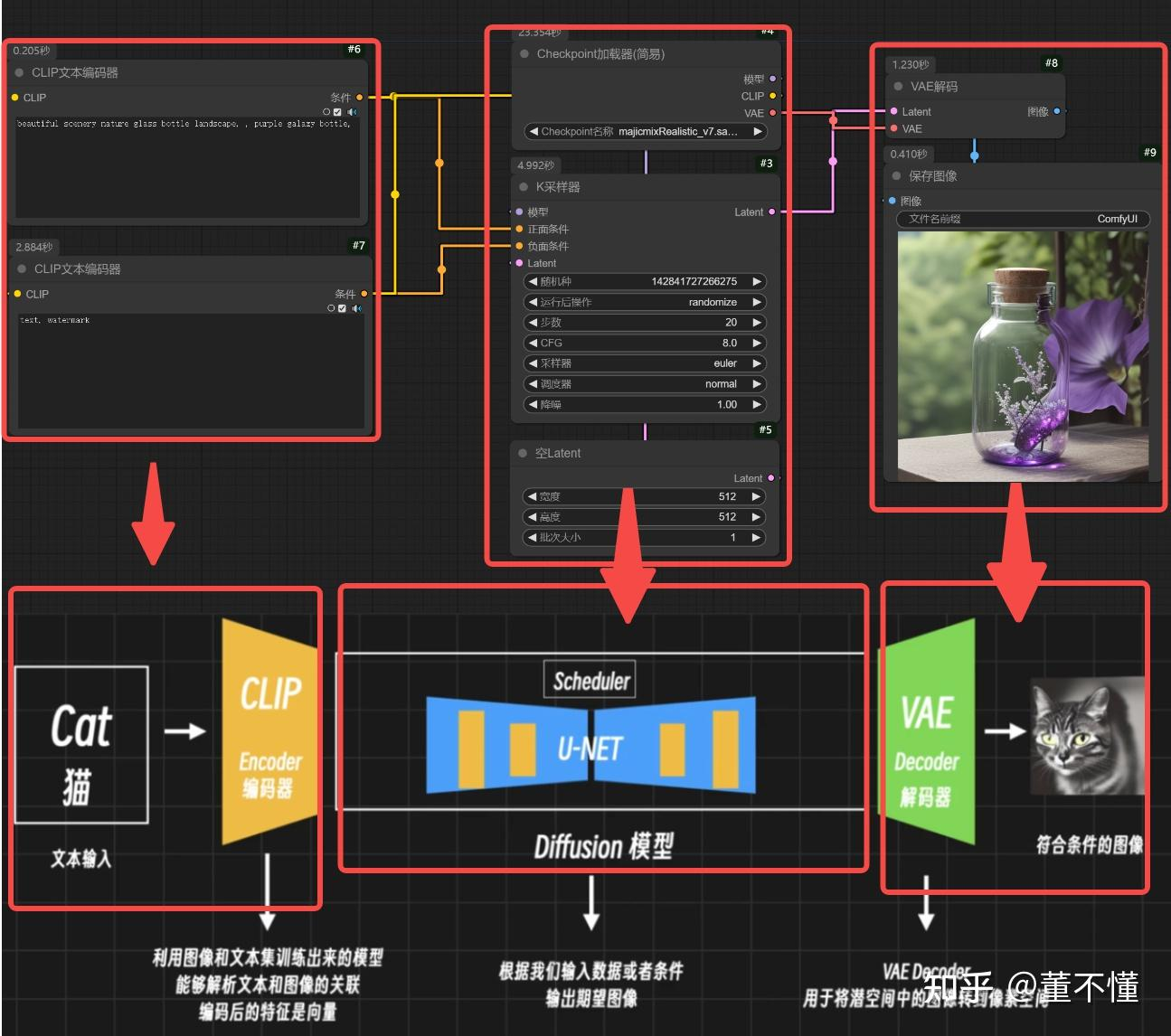
对应到实际的comfyui界面的几块.
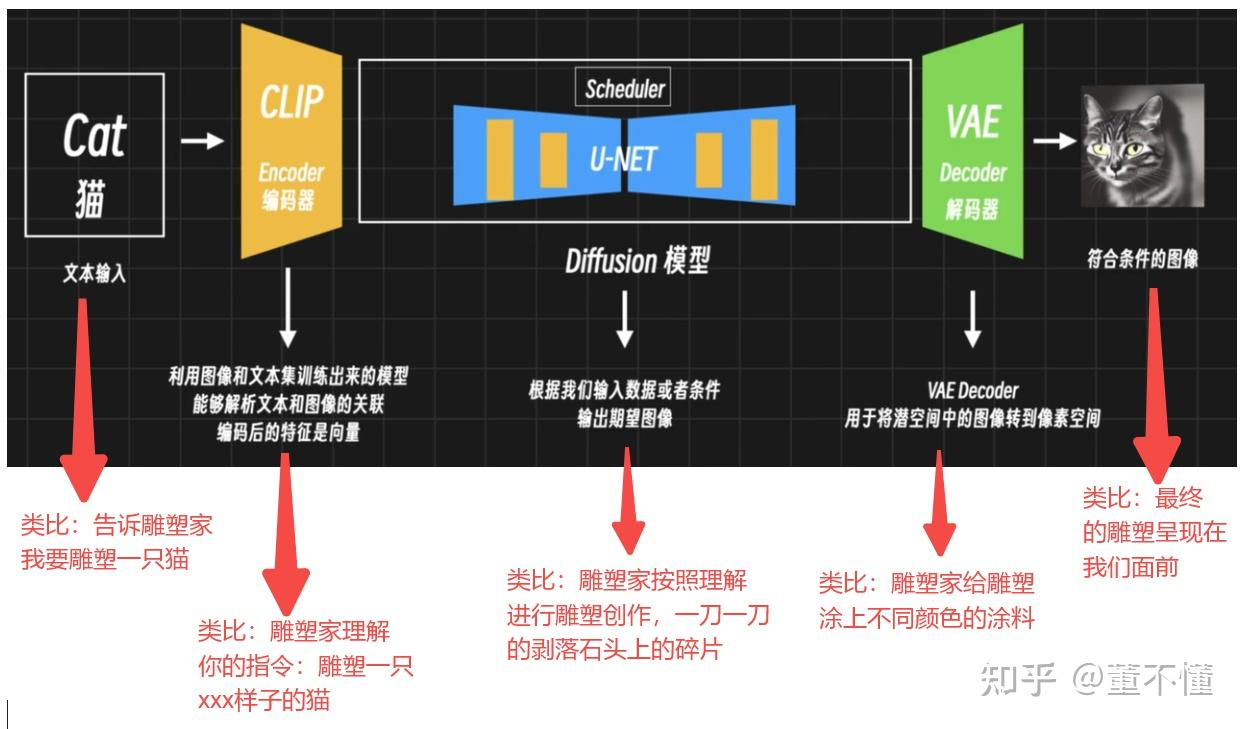
stable_diffusion原理.
最开始是ddpm一个论文, 用diffusion算法来替代之前的big gan算法.是一个自监督的生成. 输入图片, 输出图片.
stable_diffusion创新是.
他从latent 到latent.
从上图能看出来, 他在unet这个是对应之前的diffusion.
他的前面加一个clip 从图片到laten
后面加一个vae decoder, 从latent到图片.所以stable_diffusion从一个学习5125123 到 5125123 的模型到了一个学latent的模型.
我们点开hf网站上sd1.5模型里面的text_encoder里面就是clip4模型, 打开config能看见
{
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"projection_dim": 768,
"torch_dtype": "float32",
"transformers_version": "4.22.0.dev0",
"vocab_size": 49408
}
这里面写的hidden_size就是模型最后的输出维度. 看到只有768.
这样模型从diffusion模型学一个5125123到一个只学768的向量.所以stablediffusion可以快速收敛, 学习难度下降. 打到了商用级别.
这点跟nlp很像, nlp的头尾也是一个text_encoder, decoder. 对文本进行编解码.编解码可以对信息进行压缩.维度下去了难度也就下去了.
学习节点:
首先出场的就是这个Checkpoint加载器(简易),它就是我们常说的大模型,一般大模型内嵌CLIP和VAE。
有3个输出:
模型:控制图像画风,一般和K采样器连接,在K采样器里控制图像的风格特征。
CLIP:用于提供文本编码,一般和CLIP文本编码器连接,这里有2个CLIP文本编码器,一个用于控制正向提示词(即我要什么),一个用于控制反向提示词(即我不要什么)。
VAE:用于提供像素空间和潜空间转换,和VAE编码器和VAE解码器相连,VAE编码器用于将像素空间转换到潜空间,VAE解码器用于将潜空间转换到像素空间。
你会发现CLIP编码器有一个输出:条件,这个条件需要作用于K采样器,分别和正面条件和负面条件相连。 表示模型在采样生成的时候,正负条件用他们来限制.
此外,K采样器的输入Latent和输出Latent,输入Latent可以理解为控制图像画布的尺寸,输出Latent是在K采样器里处理好的图像潜在空间,我们需要用VAE解码器将Latent转为像素,进而得到我们绘制的图像。
你可以把K采样器看做整个工作流的核心,即你可以首先调出K采样器,然后完善K采样器的输入和输出以及参数部分,不同的参数会影响出图质量和出图样式。
参数:降噪
一般文生图场景,降噪这个参数都设置为1。
在图生图场景:它决定了在采样步骤之前向图像添加多少噪声。降噪强度的取值范围为0到1,其中0表示输入图像中不添加噪声,那么原图的变化就很小,而1表示输入图像完全被噪声替换,这样采样之后得到的图像和原图完全不一样,一般0.65

 浙公网安备 33010602011771号
浙公网安备 33010602011771号