

dpo笔记 和代码
参考:
https://blog.csdn.net/chacha_/article/details/134527000
这个讲的很好.

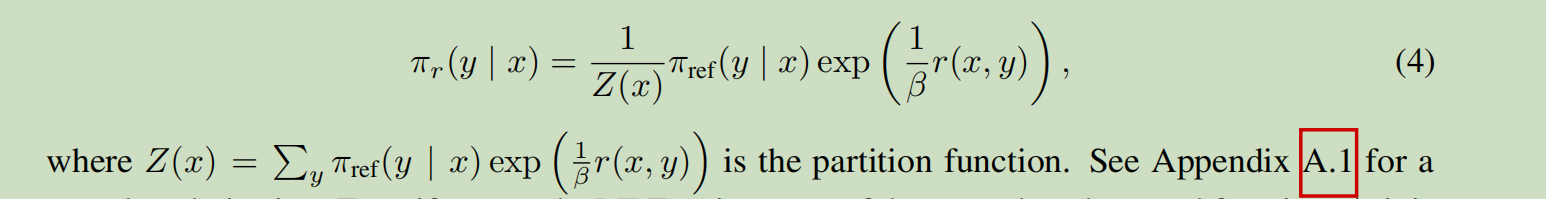
\(\pi_r\)是我们要的解,我们(4)两边取log得到.
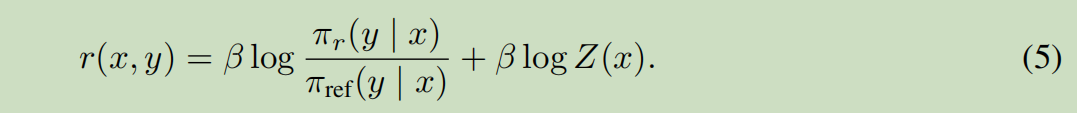
y1,y2是两个生成的句子,x是prompt.p是y1比y2好的优化函数.r是reward函数.

机器学习里面一个变量右上角写\(*\),就表示他的估计.也就是真实的计算.不写\(*\) 表示理论值.
带入上面公式. \(\sigma\)是 1+exp(x)再一起取倒数.
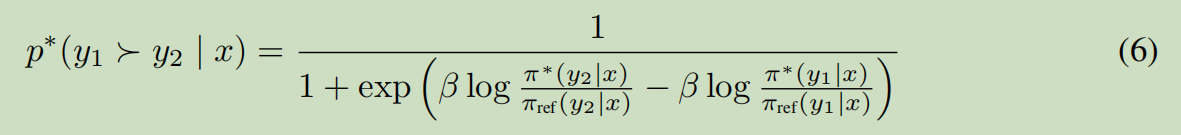
优化的是策略\(\pi\), 而不是reward.
跟ppo类似推理我们有:
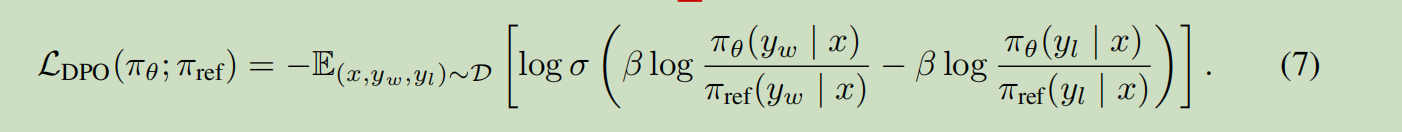
整体流程:

上面说实际使用. \(\pi_ref\)是通过最大化\(y_w\)来生成的,然后优化\(\pi\)即可.
代码和具体实现:
https://zhuanlan.zhihu.com/p/642569664
#======整个代码没毛病,很严谨.
# dpo代码: 一个可以轻松跑起来的代码. 隐含层=1, 所以好跑.
import torch
import torch.nn.functional as F
from transformers import LlamaForCausalLM, LlamaConfig
from copy import deepcopy
torch.manual_seed(0)
if __name__ == "__main__":
# 超参数
beta = 0.1
# 加载模型
policy_model = LlamaForCausalLM(config=LlamaConfig(vocab_size=1000, num_hidden_layers=1, hidden_size=128))
reference_model = deepcopy(policy_model)
# data
prompt_ids = [1, 2, 3, 4, 5, 6]
good_response_ids = [7, 8, 9, 10]
# 对loss稍加修改可以应对一个good和多个bad的情况
bad_response_ids_list = [[1, 2, 3, 0], [4, 5, 6, 0]]
# 转换成模型输入
input_ids = torch.LongTensor(
[prompt_ids + good_response_ids, *[prompt_ids + bad_response_ids for bad_response_ids in bad_response_ids_list]]
)
# labels 提前做个shift #因为第一个token不是生成出来的,所以label要少一个.-100表示这个token不计算loss
labels = torch.LongTensor(
[
[-100] * len(prompt_ids) + good_response_ids,
*[[-100] * len(prompt_ids) + bad_response_ids for bad_response_ids in bad_response_ids_list]
]
)[:, 1:]
loss_mask = (labels != -100)
labels[labels == -100] = 0
# 计算 policy model的log prob
logits = policy_model(input_ids)["logits"][:, :-1, :] #policy_model(input_ids)["logits"] 输出的是 2*....11*在字典上的概率分布图. 这里面*表示预测值.这是统计上经常使用的方法.也记作~, 也就是\hat. 也就是2的估计值. 所以我们logits= 2*.....10*在字典分布.
per_token_logps = torch.gather(logits.log_softmax(-1), dim=2, index=labels.unsqueeze(2)).squeeze(2) #收集labels的概率.也就是每一步的概率. #这个就是把字典分布中的概率取出来. per_token_logps=2*....10* 的概率值.
all_logps = (per_token_logps * loss_mask).sum(-1)
# 暂时写死第一个是good response的概率
policy_good_logps, policy_bad_logps = all_logps[:1], all_logps[1:] # 这个就是我们的pi模型,也就是我们当前要学习的模型对于good和bad的打分.
#============最后我废话一下, 这里面这里面因为label只有1到10.所以只能拿2*到10*来跟2到10来算loss.所以35行需要:-1一下.
# 计算 reference model的log prob 跟上面完全类似.只是不求导了.
with torch.no_grad(): # reference_model是旧模型,旧模型不要算梯度,所以这里面nograd了.
logits = reference_model(input_ids)["logits"][:, :-1, :]
per_token_logps = torch.gather(logits.log_softmax(-1), dim=2, index=labels.unsqueeze(2)).squeeze(2)
all_logps = (per_token_logps * loss_mask).sum(-1)
# 暂时写死第一个是good response的概率
reference_good_logps, reference_bad_logps = all_logps[:1], all_logps[1:]
# 计算loss,会自动进行广播
logits = (policy_good_logps - reference_good_logps) - (policy_bad_logps - reference_bad_logps)
loss = -F.logsigmoid(beta * logits).mean()
print(loss)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号