

Set集合
一、Set集合简介
Set集合简单来说相当于一个桶,程序可以依次的把多个对象丢进桶中(Set集合)
Set继承于Collection接口,是一个不允许出现重复元素,并且无序的集合,主要有hashSet和TreeSet两大实现类。
二、hashSet
hashSet是Set接口的典型实现,大多数使用Set集合就是使用这个实现类。
hashSet是基于hashmap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75的hashmap。
放入hashSet中的集合元素实际上是由hashmap中的key来保存的,value存储了一个静态的Object对象。
特点:
1、不能保证元素的排列顺序,也就是无序
2、hashSet不是同步的,也就是非线程安全的,为了防止对外不同步,应该在创建的时候使用Collections.synchronizedSet方法来包装Set
代码示意:
1 package collection; 2 3 import java.util.HashSet; 4 import java.util.Set; 5 6 public class Demo7 { 7 public static void main(String[] args) throws InterruptedException { 8 TestHashSet run2 = new TestHashSet(); 9 Thread thread1 = new Thread(run2); 10 Thread thread2 = new Thread(run2); 11 thread1.start(); 12 thread2.start();//两个线程对同一个任务里面的Hashset添加数据,验证hashset不是线程安全的。 13 Thread.sleep(100); 14 System.out.println(run2.set.size());//测试结果表明,一般情况下都是超过1000个数据的 15 } 16 } 17 class TestHashSet implements Runnable { 18 // 实现Runnable 让该集合能被多个线程访问 19 Set<Integer> set = new HashSet<Integer>(); 20 21 // 线程的执行就是插入1000个整数 22 @Override 23 public void run() { 24 for (int i = 0; i < 1000; i++) { 25 set.add(i); 26 } 27 } 28 }
3、集合元素值可以为null
HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。底层数据结构是哈希表。
哈希表:一个元素为链表的数组,综合了数组和链表的优点。
hashSet中add方法解析:
add方法实际上是调用了底层hashMap的put方法。
首先是判断元素Key是否存在,如果不存在那么插入,如果存在,那么不插入。
问:是怎么判断key是否存在呢?
答:当我们向Set对象中添加对象时,首先调用此对象类的hashCode方法,计算出这个对象的哈希值,这个哈希值就相当于具体是那个桶(数组的下标),
再判断,这个桶(下标)的位置有没有已存储对象,如果没有,那么直接存储此对象,如果已存储有对象,则调用equals方法比较两个对象是否相同,相同则不添加,这样也就避免了hashSet中不存在重复值。
hashSet的遍历方式
1 package collection; 2 3 import java.util.HashSet; 4 import java.util.Iterator; 5 6 public class Demo8 { 7 public static void main(String[] args) { 8 HashSet<String> strings = new HashSet<>(); 9 strings.add("你好"); 10 strings.add("hello"); 11 //第一种遍历方式 12 for (String s:strings) { 13 System.out.println(s); 14 } 15 //第二种遍历方式 16 Iterator iterator = strings.iterator(); 17 while (iterator.hasNext()){ 18 System.out.println(iterator.next()); 19 } 20 } 21 }
总结:map是整个HashSet的核心,而PRESENT则是用来造一个假的value来用的。Map有键和值,HashSet相当于只有键,值都是相同的固定值,即PRESENT。
三、TreeSet
首先此集合从名字上来看与树有关,TreeSet也是基于Map来实现,其底层结构为红黑树
与hashSet同理,TreeSet继承AbstractSet类,获得了set集合基础实现操作。
TreeSet中add方法解析:
实际上调用了底层TreeMap的put方法,再put方法中会调用到Compare(Key,Key)方法,进行key大小的比较。
如果比第一个元素大,就存入树结构根的右侧,如果比第一个元素小,就存入树结构根的左侧。
特点:
1、没有重复元素
2、添加,删除元素,判断元素是否存在,效率比较高
3、有序,为了有序,实现了Comparable接口或者通过构造方法提供一个Comparator对象
TreeSet的元素支持两种排序方式:
自然排序:往TreeSet中添加基本类型调用的是TreeSet的无参构造方法,因此是自然排序
1 package collection; 2 3 import java.util.TreeSet; 4 5 public class TreeSetTest { 6 public static void main(String[] args) { 7 //自然排序实现了排序和去重 8 TreeSet<Integer> treeSet = new TreeSet<>(); 9 treeSet.add(11); 10 treeSet.add(13); 11 treeSet.add(12); 12 treeSet.add(12); 13 for (Integer s:treeSet) { 14 System.out.println(s); 15 } 16 } 17 }
根据提供的Comparator进行排序
1 package collection; 2 3 public class Dog implements Comparable{ 4 private String name; 5 private int age; 6 7 public Dog(String name, int age) { 8 this.name = name; 9 this.age = age; 10 } 11 12 public String getName() { 13 return name; 14 } 15 16 public int getAge() { 17 return age; 18 } 19 20 @Override 21 public int compareTo(Object o) { 22 return 0;//当返回0时,集合中只有一个元素 23 //return 1;当返回1时,会顺序存储 24 //return -1;当返回-1时,会倒序存储 25 } 26 }
1 package collection; 2 3 import java.util.TreeSet; 4 5 public class TreeSetTest { 6 public static void main(String[] args) { 7 //自然排序实现了排序和去重 8 TreeSet<Dog> treeSet = new TreeSet<>(); 9 Dog dog1 = new Dog("金毛",25); 10 Dog dog2 = new Dog("哈士奇",22); 11 Dog dog3 = new Dog("阿拉斯加",24); 12 Dog dog4 = new Dog("萨摩耶",21); 13 Dog dog5 = new Dog("柴犬",20); 14 treeSet.add(dog1); 15 treeSet.add(dog2); 16 treeSet.add(dog3); 17 treeSet.add(dog4); 18 treeSet.add(dog5); 19 for (Dog dog : treeSet) { 20 System.out.println(dog.getName()+"---"+dog.getAge()); 21 } 22 } 23 }
问:为什么返回0,只会存一个元素,返回-1会倒序存储,返回1会怎么存就怎么取呢?
答:当返回结果为0时:元素值每次比较都认为是相同的元素,这时就不再插入新元素。
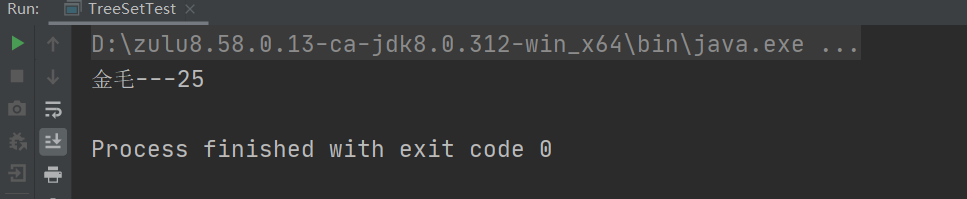
答:当返回结果为1时:元素值每次比较,都认为新插入的元素比上一个元素大,于是二叉树存储时,会存入根的右侧,读取时就是正序
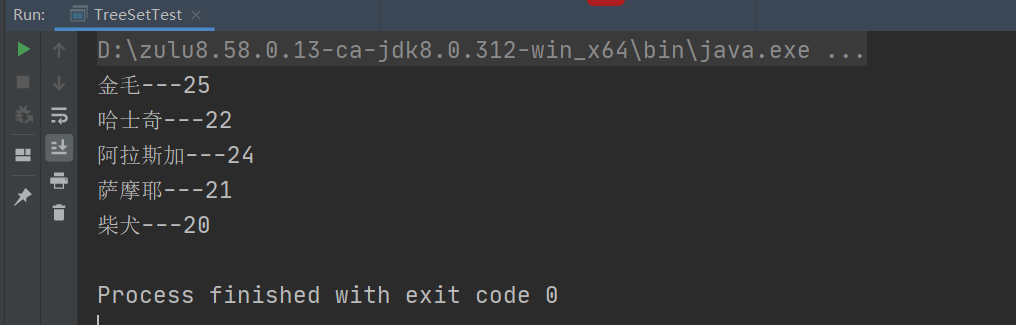
当返回结果为-1时:元素值每次比较,都认为新插入的元素比上一个元素小,于是二叉树存储时,会存再根的左侧,读取时就是倒序
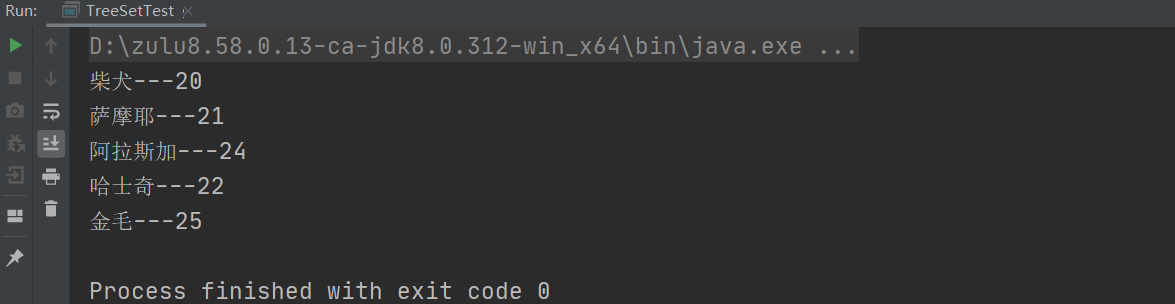
元素是如何存储进去的?
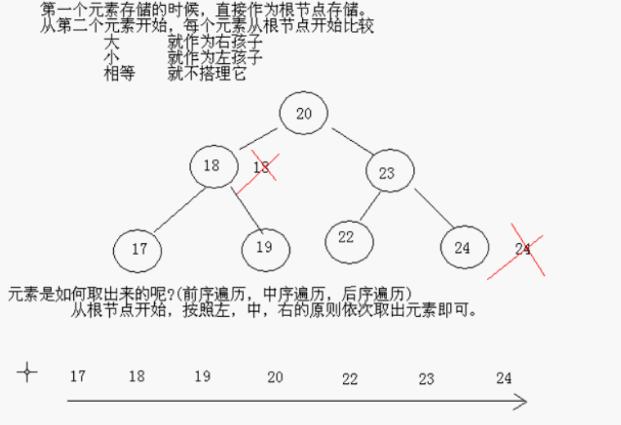
总结,TreeSet底层是二叉树结构,红黑树是一种自平衡的二叉树。对add新对象按照指定的顺序进行排序,每增加一个对象都会进行排序,将对象插入到二叉树指定的位置。
使用场景分析:HashSet是基于hash算法实现的,其性能通常是优于TreeSet,为了快速查找而设计的,通常应该使用HashSet,在需要排序的功能时才使用TreeSet。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号