

第十二章 DOM2和DOM3
元素大小
偏移量
offsetHeight: 元素在垂直方向上占用的空间大小,包括元素的高度,水平滚动条的高度,上边框高度和下边框高度。
offsetWidth: 元素在水平方向上占用的空间大小,包括元素的宽度度,垂直滚动条的高度,左边框高度和右边框高度。
offsetLeft: 元素的左外边框至包含元素的左内边框之间的像素距离。
offsetRight: 元素的左外边框至包含元素的左内边框之间的像素距离。
offsetTop:
offsetParent: 属性返回一个对象的引用,这个对象是距离调用offsetParent的元素最近的(在包含层次中最靠近的),并且是已进行过CSS定位的容器元素。
如果这个容器元素未进行CSS定位, 则offsetParent属性的取值为根元素
客户区大小
元素内容及其内边距占据的空间大小。
clientWidth
clientHeight
滚动大小
包含滚动内容的元素大小。
scrollHeight: 再没有滚动的情况下,元素内容的总高度。
scrollWidth: 在没有滚动的情况下,元素内容的总宽度。
scollLeft: 被隐藏再内容区域左侧的像素。通过设置这个属性可以改变元素的滚动位置。
scollTop: 隐藏再内容区域上方的像素。通过设置这个属性可以改变元素的滚动位置。
确定元素大小
getBoundingClientRect(): 为每个元素返回一个矩形对象,包含4个属性: left, top, right bottom。这些属性给出了元素再页面中相对视口的位置。
function getElementLeft(element) { //获取形参的元素的左外边框指包含元素的左内边框之间的像素差 var actualLeft = element.offsetLeft; //获取包含块的内边距 var current = element.offsetParent; //当包含块不是空的时候 while(current !== null) { //左偏移量 + 包含框的做偏移量 并赋值 actualLeft += current.offsetLeft; //获取包含块的父级 current = current.offsetParent; } 把值返回出去 return actualLeft; } function getElementTop(element) { var actualTop = element.offsetTop; var current = element.offsetParent; while(current !== null) { actualTop += current.offsetTop; current = current.offsetParent; } return actualTop; } function getBoundingClientRect(element) { //获取形参的顶部滚动距离 var scrollTop = document.documentElement.scrollTop; //获取形参的左边滚动距离 var scrollLeft = document.documentElement.scrollLeft; //如果形参的getBoundingClientRect可以用的话 if(element.getBoundingClientRect) { //检测这个函数的形参的自定义属性offset不是数字的时候 if(typeof arguments.callee.offset != "number") { //创建一个div var temp = document.createElement("div"); //给这个div绝对定位 temp.style.cssText = "position: absolute; left: 0; top: 0;"; //把这个元素丢进文档树 document.body.appendChild(temp); //用getboundingClientRect方法获取这个div的高度,-减去滚动的距离,的到这个元素的top值。 arguments.callee.offset =-temp.getBoundingClientRect().top - scrollTop; //从文档树中删除这个div document.body.removeChild(temp); //解除引用 temp = null; } //获取这个形参的bottom.top,left,和right var rect = element.getBoundingClientRect(); // 把这个对象的自定义属性赋给它自己 var offset = arguments.callee.offset; //把值返回出去 return { left: rect.left + offset, right: rect.right + offset, top: rect.top + offset, bottom: rect.bottom + offset } } else { var actualLeft = getElementLeft(element); var actualTop = getEementTop(element); return { left: actualLeft - scrollLeft, right: actualLeft + element.offsetWidth - scrollLeft, top: actualTop - scrollTop, bottom: actualTop + elementoffsetHeifht - scrollTop } }
遍历
DOM遍历是深度优先的DOM结构遍历,移动的方向至少有俩个,遍历以给定节点为根,不可能超出DOM树的根节点。
任何节点都可以作为遍历的根节点。即可以向下遍历,或者向上遍历。
NodeIterator:
document.createNodeIterator()
//创建新实例
接受4个参数.
root:作为搜索起点的树中的节点。
whatToShow: 表示要访问那些节点的数字代码。
filter:NodeFilter对象。一个表示应该接受还是拒绝某种特定节点的函数。
每个NodeFilter对象只有一个方法,即accept-Node();如果应该访问给定节点返回NodeFilter.FILTER_ACCEPT,不应该访问返回NodeFilter.FILTER_SKIP;
NodeFilter的俩个主要方法:
nextNode() 下一个节点, previousNode(),上一个节点。
例如一个展示《p》元素的节点迭代器
var filter = { acceptNode: function(node) { // 如果形参的标签名等于p 就返回 NodeFilter.FILTER_ACCEPT, // 不然返回NodeFilter.FILTER.SKIP; return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER.SKIP; } }; var iterator = document.createNodeIterator(root, Nodefilter.SHOW_ELEMENT, filter, false);
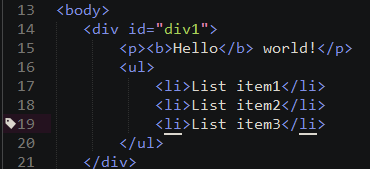
遍历div元素中的所有元素
var oDiv = document.getElementById("div1"); var iterator = document.createNodeIterator(oDiv, NodeFilter.SHOW_ELEMENT, null, false); var node = iterator.nextNode(); while(node !== null) { console.log(node.tagName); node = iterator.nextNode(); } // DIV // P // B // UL // LI(3)
如果只想返回遍历中遇到的li元素,只要使用一个过滤器
var oDiv = document.getElementById("div1"); var filter = function(node) { return node.tagName.toLowerCase() == "li" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
// NodeFilter.FILTER_ACCEPT 和 NodeFilter.FILTER_SKIP都是跳过指定的节点 } var iterator = document.createNodeIterator(oDiv, NodeFilter.SHOW_ELEMENT, filter, false); var node = iterator.nextNode(); while(node !== null) { console.log(node.tagName); node = iterator.nextNode(); } //li(3)
TreeWalker
TreeWalker是NodeIterator的高级版本,提供了不同方向上的遍历DOM结构的方法
parentNode():遍历到当前节点的父节点;
firstChild(): 遍历到当前节点的第一个子节点。
lastChild(): 遍历到当前节点的最后一个子节点。
nextSiblings(): 遍历到当前节点的下一个同辈节点节点。
previousSiblings(): 遍历到当前节点的上一个同辈节点。
TreeWalker和NodeIterator一样接受4个参数, 作为遍历起点的根节点、要显示的节点类型、过滤器。一个表示是否扩展 实例引用的布尔值。
var oDiv = document.getElementById("div1"); var walker = document.createTreeWalker(oDiv,NodeFilter.SHOW_ELEMENT, filter, false); var filter = function (node) { return node.tagName.toLowerCase() == "li" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; // 使用walker时NodeFilter.FILTER_REJECT跳过相应节点及该整个字树 } var node = walker.nextNode(); if( node !== null) { console.log(node.tagName); node = walker.nextNode(); } // LI
使用TreeWalker遍历DOM树,即使不定义过滤器,也可以取得所有<li>元素。
var oDiv = document.getElementById("div1"); var walker = document.createTreeWalker(oDiv, NodeFilter.SHOW_ELEMENT, null, false); walker.firstChild(); //div的第一个子元素即,定位到<p>元素 walker.nextSibling(); //p元素下一个同辈元素,即定位到<ul>元素 var node = walker.firstChild(); // 转到uil的第一个子元素 while(node !== null) { .// 当 node不为空的时候, console.log(node.tagName); // 弹出标签名 node = walker.nextSibling(); // 保存walk的下一个同辈元素 }
范围
为了方便控制页面,"DOM二级遍历和范围" 定义了“范围”接口。通过范围可以选择文档中的一个区域,而不比考虑节点的界限。
var range = document.createRange();
新创建的范围直接与创建它的文档关联,不能用于其他文档。创建范围之后,接下来就可以使用它再后台选择文档中的特定部分。设置位置之后,可以针对范围的内容进入很多操作。
每个范围由一个range类型的实例表示
startContainer: 包含范围起点的节点(选取中第一个节点的父节点)。
startOffset: 范围在startContainer中的偏移量。
endContainer: 包含范围终点的节点。
endOffset: 包含范围在endContainer终点的偏移量=。
commonAncestorContainer: startContainer和endContaine共同祖先节点再文档树中位置最深的那个。
1用DOM范围实现简单选择
用范围选择文档中的一部分。
有俩种方法 selectNode() 或 selectNodeContents()。都接受一个参数,即DOM节点,然后使用这个DOM节点信息来填充范围。
selectNode()选择整个节点,包括子节点。selectNodeContents()只选择节点的子节点。
<body> <p id="p1"><b>Hello</b> world!</p> </body>
可以使用下列的代码创建范围:
var range1 = document.createRange(); var range2 = document.createRange(); p1 = document.getElementById("p1"); range1.selectNode(p1); range2.selectNodeContents(p1);
2、用DOM范围实现复杂选择
使用setStart() ,setEnd()可以实现更复杂的范围选择接受一个参照节点和一个偏移量。
setStart(): 参照节点变成startContainer,偏移量变成startOffset。
setEnd(): 参照节点endContainer, 偏移节点endOffset。
<body> <p id="p1"><b>Hello</b> world!</p> </body>
var p2 = document.getElementById("p1"); helloNode = p1.firstChild.firstChild; worldNode = p1.lastChild; var range3 = document.createRange(); //传入helloNode,并设置偏移量2 (也就是e的位置) range3.setStart(helloNode, 2); ////传入helloNode,并设置偏移量3 (也就是r的位置) range3.setEnd(worldNode, 3)
3 操作DOM范围中的内容
在创建范围时,内部会为这个范围创建一个文档片段,范围所属的全部节点都被添加到这个文档片段中。
deleteContents(): 可以从文档中删除范围所包含的内容。
extractContents(): 也可以从文档中移除范围内容,但是会返回文档片段。
var text = document.getElementById("p2");
var _this = text.firstChild.firstChild;
var _is = text.lastChild;
var range = document.createRange();
range.setStart(_this, 2);
range.setEnd(_is, 3);
var fragment = range.extractContents();
text.parentNode.appendChild(fragment);
4、插入DOM范围中的内容
insertNode(): 可以向范围选区开始处插入一个节点。
<body> <span style="color: red">Inserted text</span> </body>
var p1 = document.getElementById("p2"); var hNode = p1.firstChild.firstChild; var wNode = p1.firstChild; var range = document.createRange(); range.setStart(hNode, 2); range.setEnd(wNode, 3); var eSpan = document.createElement("span"); eSpan.style.color = "red"; eSpan.appendChild(document.createNodeText("Inserted text")); range.insertNode(eSpan);
startContainer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号