Redis哨兵
当Redis做主从复制高可用方案时,如果master宕机了,Redis本身都没有实现自主进行主备切换,而Redis Sentinel是一个独立的进程,能监控多个master-slave集群,发现master宕机后能进行自动切换。
哨兵的作用:
- 监控节点状态
- 当Master节点故障时,自动提升Replication(Slave)为Master
- 发送故障通知
- 配置传播(就是把更新后的集群配置传播给其他哨兵进行更新,保持一致性)
哨兵集群:
使用多个哨兵进行监控任务以保证系统足够稳定。此时哨兵不仅会监控master和slave,同时还会互相监控;这种方式称为哨兵集群,哨兵集群需要解决故障发现、和master决策的协商机制问题
哨兵之间与slaves之间的自动发现机制:
- 哨兵利用了master的发布/订阅机制去自动发现其它也监控了统一master的哨兵节点,通过向名为channel:sentinel:hello的管道中发送消息来实现
- 新加入的sentinel节点向这个channel发布一条消息,包含自己本身的信息,这样订阅了这个channel的sentinel就可以发现这个新的sentinel
- 哨兵中不需要配置某个master的所有slave地址,sentinel会通过询问master来得到这些slave的地址的,哨兵向主库发送INFO命令,主库接收后会把从库列表返回给哨兵,哨兵通过从库列表的连接信息和每个从库建立连接,并通过这个连接持续对从库进行监控
基于pub/sub机制的客户端事件通知:
每个哨兵提供pub/sub机制,客户端可以从哨兵订阅消息,不同消息频道包含了主从库切换过程中的不同关键事件

从这些频道可以让客户端从哨兵订阅消息,客户端可以知道主从切换后新主库的连接信息,监控主从库切换过程中发生的各个重要事件。
master的故障发现:sentinel会定期向master发送心跳来确认其是否存活,如果master在一定时间内没有正确响应,sentinel会把master设置为“主观不可用状态”(SDOWN),这个时候不会马上进行failover,还需要参考其他sentinel的意见,如果超过某个数量的sentinel也主观地认为该master死了,那么会认为master是“客观不可用”(ODOWN)。接着就开始进入选举新的master流程。ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
sentinel.conf配置参数:sentinel monitor mymaster ip:port 2 master名称+master地址+集群数 标识当哨兵集群中两个哨兵认为master不可用了,则master客观下线 sentinel down-after-milliseconds mymaster 60000 master心跳响应时间范围60000ms
但是这里又会遇到一个问题,就是sentinel中,本身是一个集群,如果多个节点同时发现master节点达到客观不可用状态,那谁来决策选择哪个节点作为maste呢?这个时候就需要从sentinel集群中选择一个leader来做决策。而这里用到了一致性算法Raft算法、它和Paxos算法类似,都是分布式一致性算法。但是它比Paxos算法要更容易理解;Raft和Paxos算法一样,也是基于投票算法,只要保证过半数节点通过提议即可;
哨兵的Raft协议:
- 每个在线的哨兵节点都可以成为领导者,当它确认主节点下线时,会向其它哨兵发is-master-down-by-addr命令,征求判断并要求将自己设置为领导者,由领导者处理故障转移;
- 当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者;
- 如果发现自己在选举的票数大于等于sentinel数量/2+1时,将成为领导者,如果没有超过,继续选举
为什么要先获得大多数sentinel的认可时才能真正去执行failover呢?
- 当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。
- 而且,sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,A会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。
- redis sentinel保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
- redis sentinel也保证了安全性:每个试图去failover同一个master的sentinel都会得到一个独一无二的版本号。
网络隔离一致性:
- redis的主从同步过程本身是异步的,master执行完客户端请求的命令后会立即返回结果给客户端,然后异步的方式把命令同步给slave。这一特征保证启用master/slave后 master的性能不会受到影响。
- 但是另一方面,在数据同步过程中,如果master因为主机网络不可用,造成了与slave的网络隔离,哨兵会对Redis集群选举选出新的master,当网络恢复后,原来的master会变为slave。但在网络隔离期间master接收到客户端的写请求,是无法同步给slave,这样就会造成数据丢失。
- 通过以下配置来避免这个问题,当master节点检测不能向至少3个slave上写数据时,它会拒绝客户端的写请求。这样保证原来网络隔离的master不再接受客户的写请求数据。
- min-slaves-to-write 3 表示只有当3个或以上的slave连接到master,master才是可写的 min-slaves-max-lag 10 表示允许slave最长失去连接的时间,如果10秒还没收到slave的响应,则master认为该 slave以断开
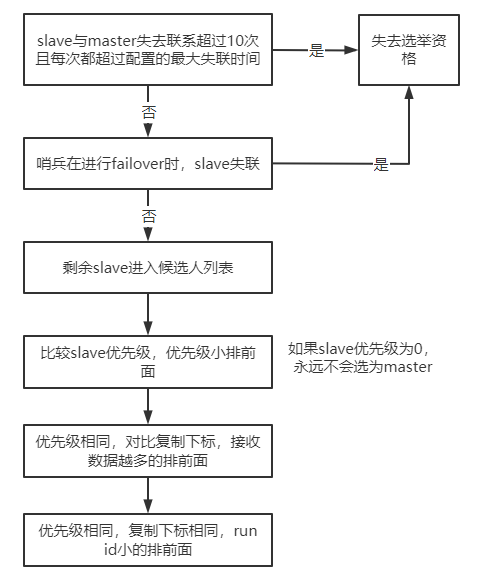
哨兵对Redis集群的选举:
哨兵选举会评估slave的以下几个方面:
与master断开连接次数、slave的优先级、数据复制的下标(用来评估slave当前拥有多少master的数据)、run id
如果一个slave与master失去联系超过10次,并且每次都超过了配置的最大失联时间,就会失去选举资格。如果哨兵在进行failover时,发现slave失联,该slave也会失去选举资格,满足上述条件的slave才会进入候选人列表,然后根据以下顺序来排序:
- 对于slave优先级,优先级小的排前面
- 优先级相同的,对比复制下标,以从master接收的复制数据越多排在前面
- 如果优先级与复制下标都相同,则run id小的排前面
如果一个redis的slave优先级配置为0,那么它将永远不会被选为master
本文来自博客园,作者:难得,转载请注明原文链接:https://www.cnblogs.com/zhangbLearn/p/18829283

 浙公网安备 33010602011771号
浙公网安备 33010602011771号