分布式事务TCC、Seata
一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
CAP:
- 一致性:数据分布在不同节点,某个节点数据进行更新,其他节点都能读取到这个数据,就是强一致性。如果某个节点没读到,就是分布式不一致。
- 可用性:非故障的节点应该在合理的时间内返回合理且正确的响应。
- 分区容错性:当出现网络分区后,系统能够继续工作
一定有P,因为分布式系统要有分区容错性,出现分区故障,要保障整套系统能够继续运行是非常重要的。
选择CP来追求强一致性,如zk,mogodb。假设发生了网络分区故障,要保证P,那么系统还是要正常运行的,但是网络分区导致两个节点互相不能通信,这时候写入数据到一个节点,但是这个节点没办法同步数据到其他节点了,为了保证两个节点数据一致,那么就只能牺牲可用性,系统直接不对外提供服务,查询返回异常,不让查到不一致的数据,保证一致性。或者选择AP放弃强一致性,追求分区容错和可用性。以上面为例,保证可用性,那么系统继续对外提供服务,就会造成节点数据不能同步,但是对外提供服务,就产生了节点的数据不一致。如12036,电商业务一般是AP,看到的商品或火车票库存是旧的,但是在购买时会检查库存。保证可用性,任何时候都要响应结果,不能频繁事变。
BASE:对AP的一个扩展,追求基本可用(BA)、软状态(S)、最终一致性(E)三点
- 基本可用:允许损失部分可用服务,保证核心服务可用。通过降级可以来保证核心服务的正常。
- 软状态:允许系统中存在中间状态,这个状态不影响系统可用性。
- 最终一致:经过一段时间后,所有节点都将会达到一致。
与ACID相反,BASE是牺牲强一致性获得可用性,并允许数据在一段时间内不一致,但最终达到一致。BASE解决了CAP中网络延迟,利用软状态和最终一致性,保证了延迟后的一致性。
XA规范:
X/Open组织定义分布式事务模型,包含几个角色。
- Application(应用程序):服务实例
- TM(事务管理器):在系统中嵌入一个专门管理横跨多个数据库的事务的组件
- RM(资源管理器):数据库
- CRM(通信资源管理器):可以是消息中间件,也可以不用
全局事务概念:一个横跨多个数据库的事务,涉及多个数据库操作,要保证多个数据库操作中,一个操作失败,其他所有库的操作回滚,也就是分布式事务
XA:定义好TM和RM之间的接口规范,管理分布式事务的组件跟各自数据库之间通信的接口。管理数据库事务统一提交或回滚,具体实现由数据库厂商提供。
JTA和全局事务:
- 全局事务:这个概念主要针对于X/Open定义的一套分布式事务的模型和规范,属于DTP(Distributed Transaction Processing Reference Model)模型中的一个概念。分布式事务处理模型。一个横跨多个数据库的事务,涉及多个数据库操作,要保证多个数据库操作中,一个操作失败,其他所有库的操作回滚,也就是分布式事务。
- JTA事务:是站在另一个角度,属于J2E中的概念,Java Transaction API。JTA是一套分布式事务的编程API,按照XA、DTP那套模型和规范来搞的,在J2EE中,单库的事务是通过JDBC事务来支持的。如果是跨多个库的事务,通过JTA API来支持的,通过JTA API可以协调和管理横跨多个数据库的分布式事务,一般来说会结合JNDI(J2EE里面老生常谈的一套东西),J2EE里面很多东西定义的很好,但是在业内使用的时候,最近这些年基本没哪个公司用了。
二阶段提交(2PC):
1、第一阶段:协调者(TM)向参与者(RM)发生Prepare请求,接受到请求后,参与者各自执行与事务相关的数据更新,写入Undo log和Redo log。参与者执行成功暂不提交事务,而是想协调者返回完成消息。协调者接收到所有参与者的返回消息,进入第二阶段
2、第二阶段:在第一阶段所有参与者返回的都是成功,那么协调者会向每个参与者发生Commit请求。参与者接收到Commit请求后各自进行事务提交,并释放锁资源。参与者事务完成后,向协调者返回完成消息。协调者接收所有参与者完成反馈后,分布式事务结束。
如果第一阶段有参与者反馈了失败消息,则第二阶段协调者会发生Abort请求,参与者接收到该请求后会进行事务回滚,依照Undo log来进行。
二阶段提交缺陷:
- 同步阻塞:所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。不能支持高并发
- 单点故障:如果协调者挂了,参与者接收不到提交或回滚,参与者会一直处于中间状态无法完成事务
- 脑裂问题:第二阶段中,如果网络异常导致部分参与者接收到了提交消息,一部分未接收到。会导致节点之间数据不一致
- 事务状态丢失:即是TM是双击热备,一个TM挂了自动选举其他TM,但是TM挂掉的时候,接收到的commit消息的某个库也挂了,这样其他TM也不知道这个分布式事务的状态了,因为不知道哪个库接收过commit消息。
解决上述问题有三种分布式事务方案:三阶段提交、MQ事务、TCC事务、最大努力通知
三阶段提交:
- CanCommit阶段:TM发送CanCommit消息给各个数据库,然后各个库返回个结果,不会执行实际的SQL语句的,各个库看看自己网络环境啊,各方面是否ready
- PreCommit阶段:如果各个库对CanCommit消息返回的都是成功,那么就进入PreCommit阶段,TM发送PreCommit消息给各个库,相当于2PC里的阶段一,执行各个SQL语句,只是不提交。如果有个库对CanCommit消息返回了失败,TM发送abort消息给各个库,结束这个事务。
- DoCommit阶段:如果各个库对PreCommit阶段都返回了成功,发送DoCommit消息给各个库,提交事务吧。如果都返回提交成功给TM,那么分布式事务成功;如果有个库对PreCommit返回的是失败,或者超时一直没返回,那么TM认为分布式事务失败,直接发abort消息给各个库,事务回滚。
在两阶段提交基础上增加了CanCommit阶段,并引入了超时机制。一旦参与者迟迟没有接收到协调者的提交请求,会自动本地commit,这样就解决了单点问题。超时机制基于CanCommit阶段,该节点确认了协调者是ok的,保证可以自己执行提交操作。同时一个库如果一直接收不到DoCommit消息,不会一直锁着资源,会提交释放资源的,减轻资源阻塞问题
缺陷:如果TM在DoCommit阶段发送了abort消息给各个库,因为脑裂问题,某个库没接收到abort消息,执行了commit操作,出现数据不一致性
各类分布式事务适用场景:
- XA事务:适用于单系统多库,多系统多库实现麻烦
- TCC:适用于多个服务操作都比较快,因为一堆同步服务包裹在一个事务里,要等到这个事务结束,才能进行下一步操作。
- 可靠消息最终一致性:适用于比较耗时的操作,通过消息中间件异步调用。多个操作在消费端去执行业务逻辑,有些操作可能在一定时间内没执行,一段时间后,会保证数据一致。
- 最大努力通知:类似于可靠消息一致性,但是不保证最后一定会成功,可能会失败,会尽力去通知服务的执行。适合于不太核心的服务调用操作,如消息通知。
TCC事务(二阶段提交):
核心思想:针对每个操作,都有注册一个与其对应的确认和补偿操作。服务化的两阶段编程模型,分为三个阶段:
- Try:做业务检查及资源预留
- Confirm:业务确认操作,Try阶段所有分支执行成功后开始执行Confirm。一般只有Try成功Confirm一定成功,如果Confirm阶段出错,需要引入重试机制
- Cancel:业务执行错误回滚,释放预留资源
TM首先发起所有的分支事务Try操作,任何一个分支事务的Try操作执行失败,TM将会发起所有分支事务的Cancel操作,若Try操作全部成功,TM将会发起所有分支事务的Confirm操作,其中Confirm/Cancel操作若执行失败,TM会进行重试
TCC与2PC的区别:
- 2PC通常都是在跨库的DB层面,而TCC则在应用层面处理,需要通过业务逻辑实现,这种分布式事务的实现方式优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能
- TCC对应用的侵入性非常强,业务逻辑的每个分支都需要实现Try,confirm,cancel三个操作。此外,其实现难度也比较大,需要按照网络状态,系统故障的不同失败原因实现不同的回滚策略
TCC适合强隔离性,严格要求一致性的活动业务,适合执行时间较短的业务。
TCC三种异常处理:
- 幂等性:引入幂等字段进行防重,在Try阶段插入。分支事务状态被初始化为INIT,当二阶段的Confirm/Cancel执行时会将其状态设置为CONFIRMED/ROLLBACKED。当TC重复调用二阶段接口,参与者会先获取事务状态控制表的对应记录查看事务状态。如果事务状态被改变,表示参与者已经处理完了,不需要再次执行。直接返回幂等成功结果给TC。
- 空回滚:二阶段Cancel方法中,通过事务状态控制表来判断Try方法是否被调用执行。如果存在事务状态且状态为INIT,表示一阶段执行成功,事务key正常执行回滚。
- 资源悬挂:TC回滚事务调用二阶段完成空回滚后,一阶段执行成功。事务状态控制记录作为控制手段,二阶段发现无记录时插入记录,一阶段执行时检查记录是否存在。
TCC:
- 主业务服务:发起事务的服务,主要控制整个分布式事务的编排和管理、执行,回滚都是由该服务控制。如充值服务
- 从业务服务:相当于被调用的服务,如积分、抽奖、资金服务。主要提供3个接口是try-confirm-cancel。try接口锁定资源,confirm是业务逻辑,cancel是回滚逻辑
- 业务活动管理器:管理具体的分布式事务的状态,分布式事务中各个服务对应的子事务的状态,包括负责触发各个从业务服务的confirm和cancel接口的执行和调用
普通tcc流程图:

TCC方案需要考虑的细节:接口拆分:从业务服务需要拆分三个接口,try-confirm-cancel。
接口特殊情况:
- 空回滚:事务发起者会先申请一个分布式事务,然后发起一阶段调用。在调用实际发起前,一般会有拦截感知这次try,写入一条分布式事务记录,然后实际调用try。实际调用过程中如果产生宕机或网络抖动,导致try没有执行。但是事务记录已经落库了,这个时候发起放可能认为当前分布式事务无法成功,通知tc回滚,回滚后会调用cancel
- try回滚及confirm回滚:try阶段执行了,但是其他服务的try失败了,那么会调用cancel回滚,要可以回滚掉try阶段的操作。confirm阶段执行了,但是别的服务失败了,要回滚掉confirm阶段的操作
- 倒置请求:刚调完try接口,网络超时导致判断结果失败,直接调用cancel空回滚。然后过几秒钟try接口请求来了,此时需要不允许执行try操作。同理confirm超时也一样。
- 接口幂等:无论多次调用三个接口,都要保证接口幂等性,可以考虑zk
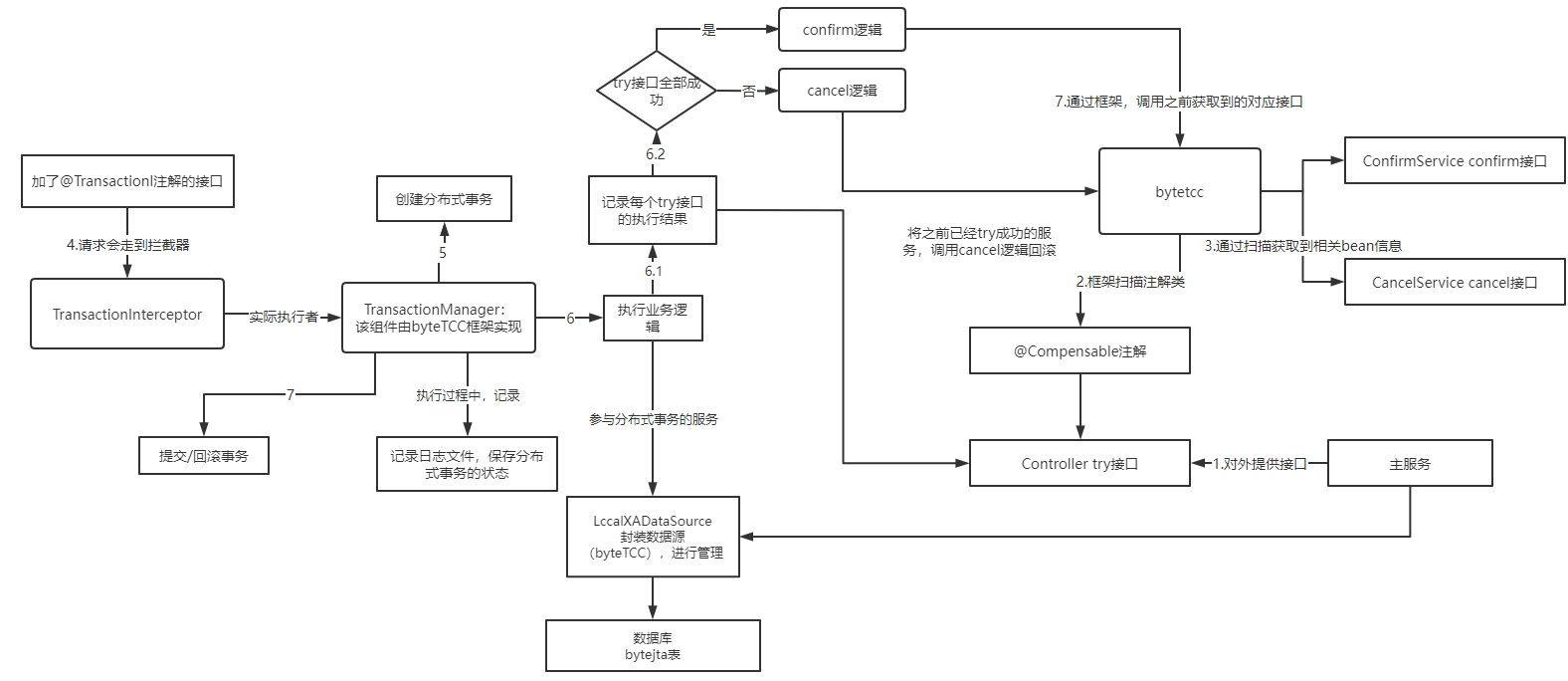
ByteTCC框架
架特性:
- try阶段和cancel是配对的,try阶段成功后如果要回滚,可以通过cancel回滚。但是对于confirm,如果有失败,默认策略是对于失败的confirm,后台会不断重试和调用。
- 设计的理念是,try阶段很可能失败,如果失败需要对所有服务回滚,try-cancel配对实现。而如果try阶段都成功了,confirm有服务失败了,那么confirm只要一直重试一定可以成功,保证数据的一致性。
- 使用框架,在每个参与tcc事务的数据库中创建一张bytejta表。事务执行的日志和状态都记录在数据库,如果系统宕机,事务执行一半,重启后会自动读取事务执行,将未完成事务继续执行。
框架原理:
Seata
开源的分布式事务解决方案,提供了 AT、TCC、SAGA 和 XA 事务模式
- TC:seata服务端,事务协调者。维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM:应用服务,事务管理器。定义全局事务的范围:开始全局事务、提交或回滚全局事务
- RM:数据库,管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的2PC方案(AT模式,基于支持本地ACID事务的关系型数据库):
- 一阶段:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段提交:马上成功结束,自动异步批量清理回滚日志
- 二阶段回滚:通过回滚日志,自动 生成补偿操作,完成数据回滚。
Seata原理:

本文来自博客园,作者:难得,转载请注明原文链接:https://www.cnblogs.com/zhangbLearn/p/18829194

 浙公网安备 33010602011771号
浙公网安备 33010602011771号