python3 自动识图
一、安装依赖库
pip install pytesseract
pip install pillow
二、安装识图引擎tesseract-ocr
https://pan.baidu.com/s/1QaYJc4ggpqhljf4sq_-WQw
密码:2v4a
下载tesseract-ocr-setup-4.00.00dev.exe并安装

三、修改pytesseract库指向tesseract的配置
1、找到python3的安装路径
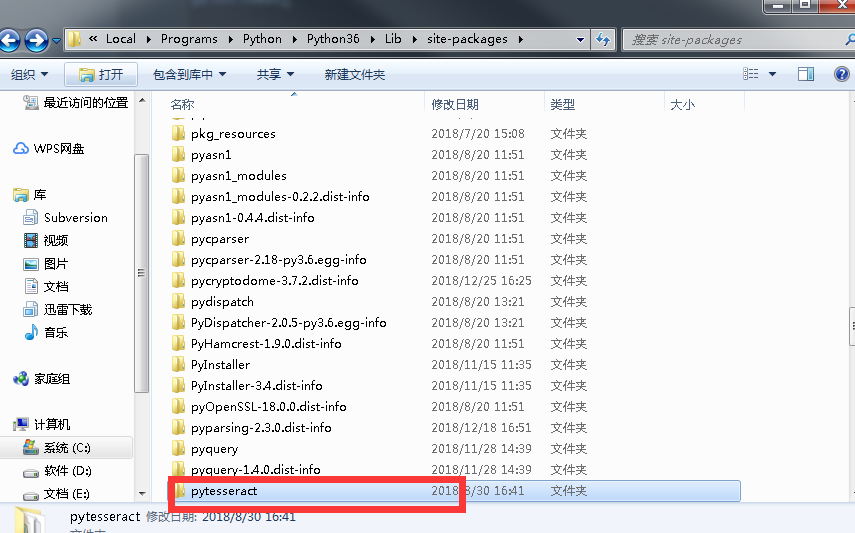
2、修改pytesseract.py文件
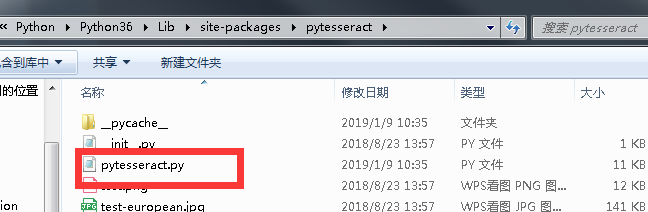
2、将tesseract_cmd的配置改成tesseract安装的执行文件

四、测试识图
1、图片内容

2、代码
from PIL import Image from pytesseract import image_to_string tessdata_dir_config = '--tessdata-dir "C:/Program Files (x86)/Tesseract-OCR/tessdata"' img = Image.open("1.png") text = image_to_string(img,lang = 'eng',config=tessdata_dir_config) print(text)
3、结果

五、支持中文
所有语音包地址
https://github.com/tesseract-ocr/tessdata
1、下载中文语音包
https://github.com/tesseract-ocr/tessdata/raw/master/chi_sim.traineddata
2、将下载好的chi_sim.traineddata包放入Tesseract-OCR安装地址中的tessdata目录中

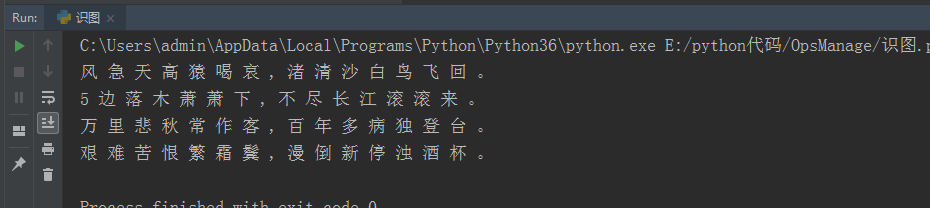
3、测试中文图片
中文图片

测试代码
from PIL import Image from pytesseract import image_to_string tessdata_dir_config = '--tessdata-dir "C:/Program Files (x86)/Tesseract-OCR/tessdata"' img = Image.open("3.png") text = image_to_string(img,lang = 'chi_sim',config=tessdata_dir_config) #之前安装的中文包名 print(text)
测试结果
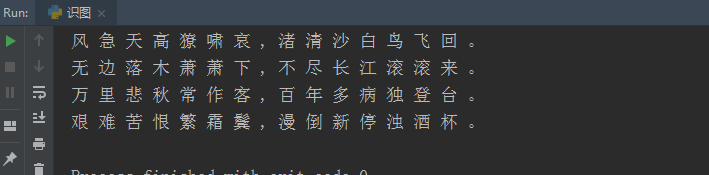
4、图标二值化
灰度化和二值化后的图片

代码
from PIL import Image from pytesseract import image_to_string tessdata_dir_config = '--tessdata-dir "C:/Program Files (x86)/Tesseract-OCR/tessdata"' img = Image.open("3.png") #灰度化 image = img.convert('L') pixels = image.load() threshold = 200 #阈值
#二值化 for x in range(image.width): for y in range(image.height): if pixels[x, y] > threshold: pixels[x, y] = 255 else: pixels[x, y] = 0 image.show() text = image_to_string(image,lang = 'chi_sim',config=tessdata_dir_config) print(text)
#结果
#结论
汉字的识别率不是太高,如果要求高的话可以使用百度云的百度识图,文档地址:https://cloud.baidu.com/doc/IMAGERECOGNITION/ImageClassify-Python-SDK.html#.E5.8A.A8.E7.89.A9.E8.AF.86.E5.88.AB
使用百度识图需要创建百度云账号,百度识图有免费额度(我没试过),阿里云的识图有点贵。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号