

问题:
在数据库编程开发中,有时会遇到数据量比较大的情况,如果直接大批量进行添加数据、修改数据、删除数据,就会是比较大的事务,事务日志也比较大,耗时久的话会对正常操作造成一定的阻塞。虽不至于达到删库跑路的程度,但也严重影响了用户体验,老是卡巴死机的感觉。这时我们可以对这个大批量操作进行分小批事务操作处理,使每批时间比较短,减少阻塞。大而化小,小而化了。举个例子:如果大批事务需要跑5分钟,那就阻塞了5分钟;如果分成10个小批,每小批0.5分钟,那就降低了长时间阻塞的几率,提高了用户体验。
把目光放宽广一点,其实不只是在数据库编程,有时候我们也需要在其他编程语言中,实现分批处理的逻辑,例如使用C#对大批量Excel数据进行处理。
对于如何求批次这个问题,我们当然是希望有统一的计算公式,不管是什么编程语言都通用的,而不是换种编程语言,就得根据不同编程语言的语法重新实现这个算法。以达到快速开发目的,一次写的表达式,去到哪里都能通用。
而求批次(或求分页数)这个问题有点像初中代数的求解:
已知总数据量a,每批(或每页)数据量为b,求所需批次(或所需总页数)x?
假设a为388888,b为10000。
解决方案:
方法1(不推荐):
如果是数据库编程,可能大部分人的思维习惯就是:
先用a / b得出除得尽部分,例如这里是38;
然后再用case when去判断a % b除不尽部分也就是余数是否为0,如果不为0,则批次加1,例如这里是8888,虽然不够10000,但是也不在38个批次之内,需要在第39批次。
使用T-SQL实现:@a / @b + case when @a % @b > 0 then 1 else 0 end
缺点:
- 很明显这样的表达式比较长,不是很简洁。
- 而且如果改用C#实现,可是不支持case when的,得重新修改表达式实现功能。
方法2(推荐):
可以直接根据四则运算,表达式为(@a + @b - 1) / @b
这个表达式,是博主自己想到的方法,解释如下:
由于序号是从1开始,第1批是从1到10000,而不是从0到9999,所以这里@a - 1,就是为了从编程习惯的角度由序号0开始;
而 + @b则是因为,0到9999中任意一个数字,除以每批数据量10000的话,都是 < 1,但实际是当1批了,需要加回。
优点:
- 单纯使用四则运算,无需case when等条件判断,代码简洁。
- 方便代码移植到C#等其他语言,只需要把参数改成相应C#变量之类,无需把case when改成C#能支持的if之类条件判断。
方法3(推荐):
可以直接根据四则运算,表达式为(@a - 1) / @b + 1
这个表达式,也是博主自己想到的方法,解释如下:
由于序号是从1开始,第1批是从1到10000,而不是从0到9999,所以这里@a - 1,就是为了从编程习惯的角度由序号0开始;
而 + 1则是因为,0到9999中任意一个数字,除以每批数据量10000的话,都是 < 1,但实际是当1批了,需要加回。
优点:
- 单纯使用四则运算,无需case when等条件判断,代码简洁。
- 方便代码移植到C#等其他语言,只需要把参数改成相应C#变量之类,无需把case when改成C#能支持的if之类条件判断。
方法2和方法3,从代数的角度看,关系式是等价的:
方法2关系式去掉括号后是:@a / @b + 1 - 1 / @b
方法3关系式去掉括号后是:@a / @b - 1 / @b + 1
脚本:
/* 问题:已知总数据量a,每批数据量为b,求所需批次x?假设a为388888,b为10000。 脚本来源:https://www.cnblogs.com/zhang502219048/p/11108723.html */ declare @a int = 388888, @b int = 10000, @x1 int, @x2 int, @x3 int --方法1(不推荐):除了四则运算外,还有取模运算,而case when条件判断更是使脚本变得长而复杂,也不利于移植到其他编程语言 select @x1 = @a / @b + case when @a % @b > 0 then 1 else 0 end --方法2(推荐):只使用四则运算就实现 select @x2 = (@a + @b - 1) / @b --方法3(推荐):只使用四则运算就实现 select @x3 = (@a - 1) / @b + 1 --查看计算结果 select @x1 as x1, @x2 as x2, @x3 as x3
在博主的上一篇技术博文《sql server使用公用表表达式CTE通过递归方式编写通用函数自动生成连续数字和日期》,说明了怎么批量生成连续数字,我们就直接生成10W数据量来验证一下本篇博文《sql server编写简洁四则运算表达式脚本实现计算批次功能(C#等其它编程语言也能直接用此通用表达式)》所述的计算批次表达式是否正确。
问题扩展到:
已知总数据量a,每批数据量为b,求每条数据所属批次x?假设a为100000,b为1000。
验证脚本:
/* 问题:已知总数据量a,每批数据量为b,求每条数据所属批次x?假设a为100000,b为1000。 作者:zhang502219048 脚本来源:https://www.cnblogs.com/zhang502219048/p/11108723.html 脚本基于:https://www.cnblogs.com/zhang502219048/p/11108991.html */ declare @a int = 100000, @b int = 1000 select vid --方法1(不推荐):除了四则运算外,还有取模运算,而case when条件判断更是使脚本变得长而复杂,也不利于移植到其他编程语言 , x1 = vid / @b + case when vid % @b > 0 then 1 else 0 end --方法2(推荐):只使用四则运算就实现 , x2 = (vid + @b - 1) / @b --方法3(推荐):只使用四则运算就实现 , x3 = (vid - 1) / @b + 1 into #t from fun_ConcatStringsToTable(1,@a) --查看所有数据和所属批次 select * from #t --检查批次计算结果是否一致 select distinct case when x1 = x2 and x2 = x3 then 'Right!' else 'Wrong!' end as Result from #t drop table #t
验证脚本运行结果: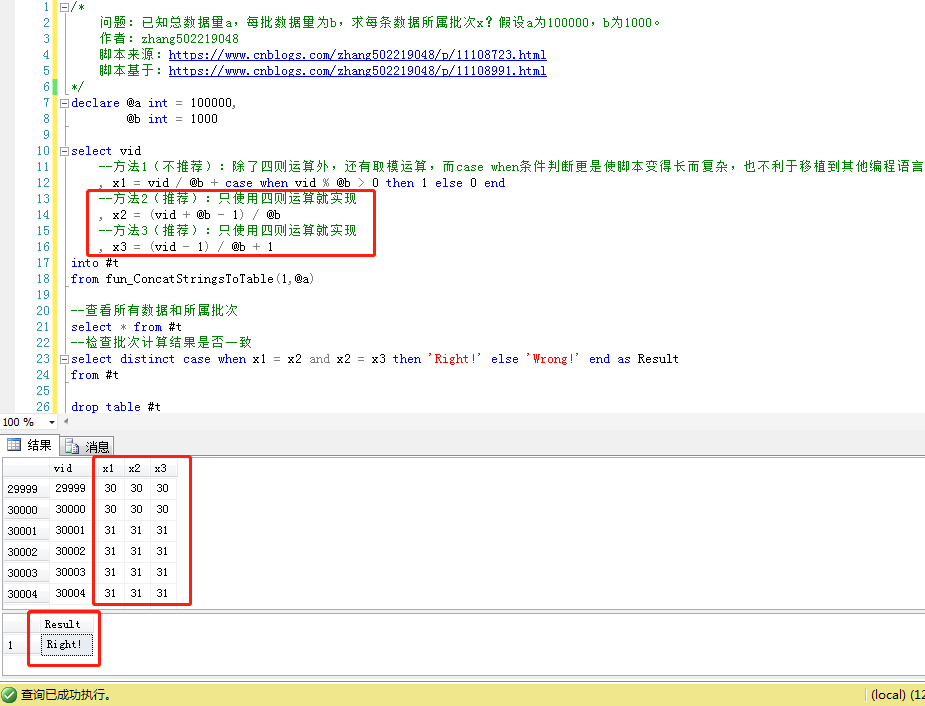
总结:
博主对于计算批次的新思路就介绍到这里,大家如果觉得有用的话可以直接拿来用,是不是觉得很方便呢?感觉为批次计算的算法注入了新的思想,标新立异。
【转载请注明博文来源:https://www.cnblogs.com/zhang502219048/p/11108723.html】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号