
zookeeper+kafka+filebeat部署
zookeeper+kafka+filebeat部署
架构图
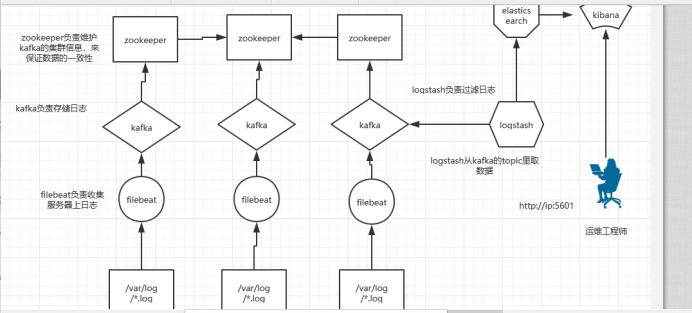
首先关闭防火墙,seliunx
三台机器:
[root@bogon ~]# systemctl stop firewalld
[root@bogon ~]# setenforce 0
然后把主机名修改成 kafka01 #依次递增
之后做一下端口映射:
192.168.253.225 kafka01
192.168.253.226 kafka02
192.168.253.227 kafka03
然后测试是否能ping通
ping kafka01
(请记住每一台都要做端口映射)
把前期工作做好!
部署zookeeper
zookeeper也是需要jdk环境的所以先安装jdk环境,
上传jdk包:
安装jdk:
rpm -ivh jdk-8u20-linux-x64.rpm
安装完之后检查它的版本号:
[root@kafka01 ~]# java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
然后上传zookeeper 包,安装:
解压 tar zxf zookeeper-3.4.14.tar.gz
然后可以给它放在本地目录下:
[root@kafka01 ~]# mv zookeeper-3.4.14 /usr/local/zookeeper 安装好之后进入它的配置文件: [root@kafka01 zookeeper]# cd conf/ [root@kafka01 conf]# cp zoo_sample.cfg zoo.cfg [root@kafka01 conf]# vim zoo.cfg 修改复制出来那个 vim zoo.cfg 修改dataDir=/usr/local/zookeeper/zkdata 目录为自己定义的
然后在最末尾行添加三台主机ip:
server.1=192.168.11.139:2888:3888 #服务器及其编号,服务器IP地址,通信端口,选举端 server.2=192.168.11.140:2888:3888 #服务器及其编号,服务器IP地址,通信端口,选举端口 server.3=192.168.11.141:2888:3888 #服务器及其编号,服务器IP地址,通信端口,选举端口
创建myid文件 (里面的数据是依次递增的)
例如:
echo “1” > /usr/local/zookeeper/zkdata/myid
然后,其他两台同理以上操作。
[root@kafka01 bin]# pwd
/usr/local/zookeeper/bin
然后开启zookeeper ./zkServer.sh start 查看状况: ./zkServer.sh status 开启第一台可能会报错 然后开启第二台,在查看第一台状态就不会报错了 之所以会报错,是开一台没法选举,所以会报错。
kafka部署
它也是需要jdk环境 上面已经安装过了就不要安装了。
然后上传kafka 包:
解压: tar zxf kafka_2.11-2.2.0.tgz
也给它放在本地目录:
[root@kafka01 ~]# mv kafka_2.11-2.2.0 /usr/local/kafka/ [root@kafka01 ~]# cd /usr/local/kafka/config/ 然后配置文件:server.properties 修改 修改 broker.id=0 #三台依次递增 修改 advertised.listeners=PLAINTEXT://kafka01:9092 #你的主机名字三台依次递增
开启 kafka
[root@kafka01 bin]# pwd
/usr/local/kafka/bin
[root@kafka01 bin]# ./kafka-server-start.sh -daemon ../config/server.properties (后台启动)
同步一下时间 yum -y install ntpdate
ntpdate 2. cn. pool. ntp.org
后面两台机器同理。
测试zookeeper 和 kafka 是否能同步:
测试:
创建生产者 :
[root@kafka01 bin]# pwd /usr/local/kafka/bin ./kafka-topics.sh --create --zookeeper 192.168.253.225:2181 --replication-factor 2 --partitions 3 --topic zs <=(生产者的名字)
查看创建的生产者:
[root@kafka01 bin]# pwd /usr/local/kafka/bin ./kafka-topics.sh --list --zookeeper 192.168.253.225:2181
模拟生产者:
[root@kafka01 bin]# pwd /usr/local/kafka/bin ./kafka-console-producer.sh --broker-list 192.168.253.225:9092 --topic zs <=(生产者的名字)
创建消费者 :
[root@kafka01 bin]# pwd /usr/local/kafka/bin ./kafka-console-consumer.sh --bootstrap-server 192.168.253.226:9092 --topic zs<=(生产者的名字)--from-beginning
然后 测试 生产者 生产的数据 消费者是否能接收到。
安装filebeat
Filebeat安装 创建yum元 vim/etc/yum.repos.d vim filebeat.repo [filebeat-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
然后用yum 安装 yum -y install filebeta
[root@kafka01 filebeat]# pwd
/etc/filebeat
然后配置 vim /etc//etc/filebeat.yml
修改内容
enabled: true #开启 paths: - /var/log/ 例如:messages 添加 : output.kafka: enbled: true #开启 hosts: ["192.168.253.225:9092","192.168.253.231","192.168.253.232"] 三台主机ip topic: messages
开启filebeta
[root@kafka01 filebeat]# systemctl start filebeat
其他两台同理。
创建 topic 脚本
[root@kafka01 bin]# pwd /usr/local/kafka/bin [root@kafka01 bin]# cat kafka-topic-create.sh #! /bin/bash readp"请输入你想创建的topic:"topic /kafka-topics.sh --create --zookeeper 192. 168.253.225:2181 -- replication-factor 3 --partitions 3 --topic $topic /kafka-topics.sh --list --zookeeper 192.168.253.225:2181
logstash .conf配置
进入conf.d目录创建。Conf文件 例如: messages.conf
先去kafka创建topic
例如:
收集messages的日志
[root@kafka02 conf.d]# cat messages.conf input{ kafka{ bootstrap_servers => ["192.168.253.225:9092,192.168.253.231:9092,192.168.253.232:9092"] group_id => "logstash" topics => "messages" consumer_threads => 5 } } output{ elasticsearch{ hosts => "192.168.253.225:9200" index => "messages-%{+YYYY-MM-dd}" } }
开启 systemctl start logstash.service
如果有报错可以查看日志
kibana 展示
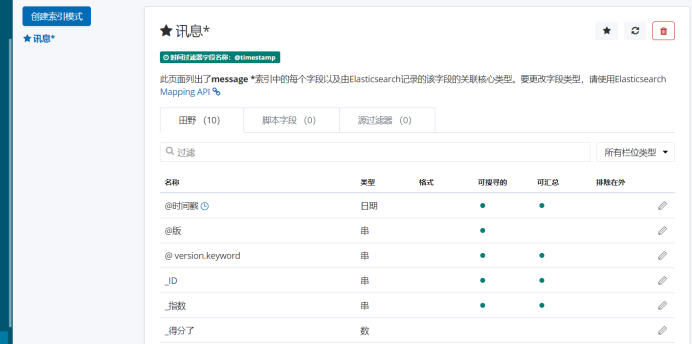
进入Kibana ui页面
创建索引查看。
页面展示:
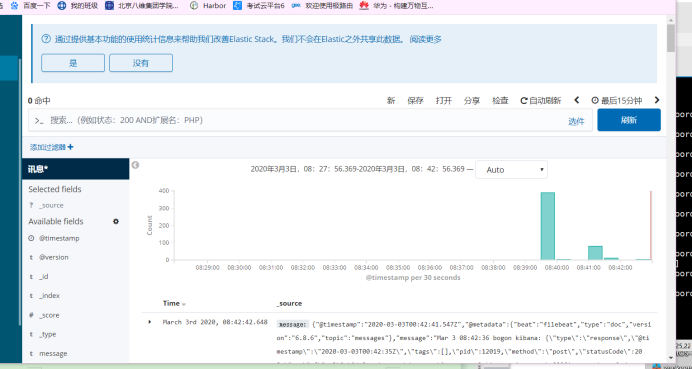
想看更多内容,记得关注我哈!
欢迎进群讨论:QQ群294668383(有意向可以添加)
