
软件作业2:论文查重
| 软件工程 | 个人作业2:论文查重 |
|---|---|
| 作业要求 | 要求 |
| 作业目标 | 学习使用Python建立工程项目,学会论文查重的具体实现步骤 |
github链接
3121004845
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| -Estimate | -估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 430 | 370 |
| -Analysis | -需求分析 (包括学习新技术) | 150 | 90 |
| -Design Spec | -生成设计文档 | 60 | 0 |
| -Design Review | -设计复审 | 20 | 20 |
| -Coding Standard | -代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| -Design | -具体设计 | 30 | 30 |
| -Coding | -具体编码 | 120 | 180 |
| -Code Review | -代码复审 | 20 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 220 | 260 |
| -Reporting | -报告 | 100 | 120 |
| -Test Report | -测试报告 | 60 | 60 |
| -Size Measurement | -计算工作量 | 40 | 40 |
| -Postmortem & Process Improvement Plan | -事后总结, 并提出过程改进计划 | 20 | 40 |
| 合计 | 560 | 660 |
JAVA实现简易论文查重
一、计算模块接口的设计与实现过程
算法设计(SimHash算法+海明距离算法)
SimHash算法
分词:对文本进行分词,得到 N 个 词
赋权重:对文本进行词频统计,为各个词设置合理的权重
哈希:计算每个分词的哈希值,得到一个定长的二进制序列,一般是 64 位,也可以是 128 位;
加权重:变换每个分词的hash值,将 1 变成正的权重值,0 变成负的权重值,得到一个新的序列
累加:各个位上的数值做累加,最终得到一个序列,序列的每一位都是所有分词的权重的累加值;
降维:再将lastHash 变换成 01 序列 simHash ,方法是:权重值大于零的位置设置为 1,小于 0 的位置设置为 0,它就是整个文本的局部哈希值,即指纹、
海明距离算法
在信息论中,两个等长字符串之间的海明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
算法结构
read类:读文件,写入文件结果
SimHash类:计算SimHash值
Hamming类:计算海明距离
Main类:main函数
实现过程
SimHash类
利用MessageDigest的SHA-1得到每个分词的hash值

利用HanLP的TermFrequencyCounter类分词

利用HanLP的TermFrequency的getFrequency()方法得到词频

加权、求和

降维

Hamming类
得到海明距离

计算相似度

二、计算模块接口部分的性能改进
遥测

实时内存
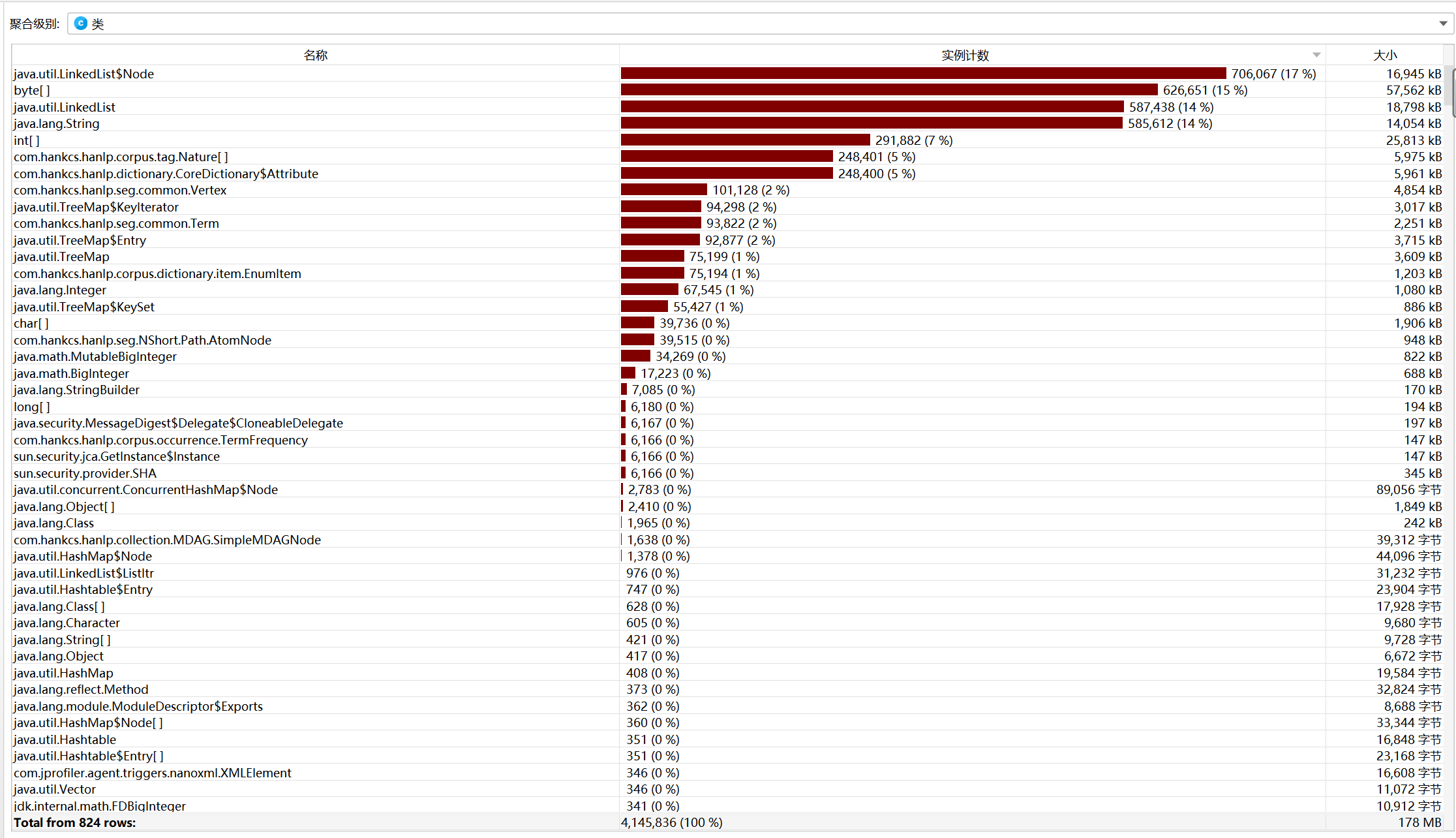
性能分析显示HanLP调用较多,无需改进
三、计算模块部分单元测试展示。
read类测试
测试代码
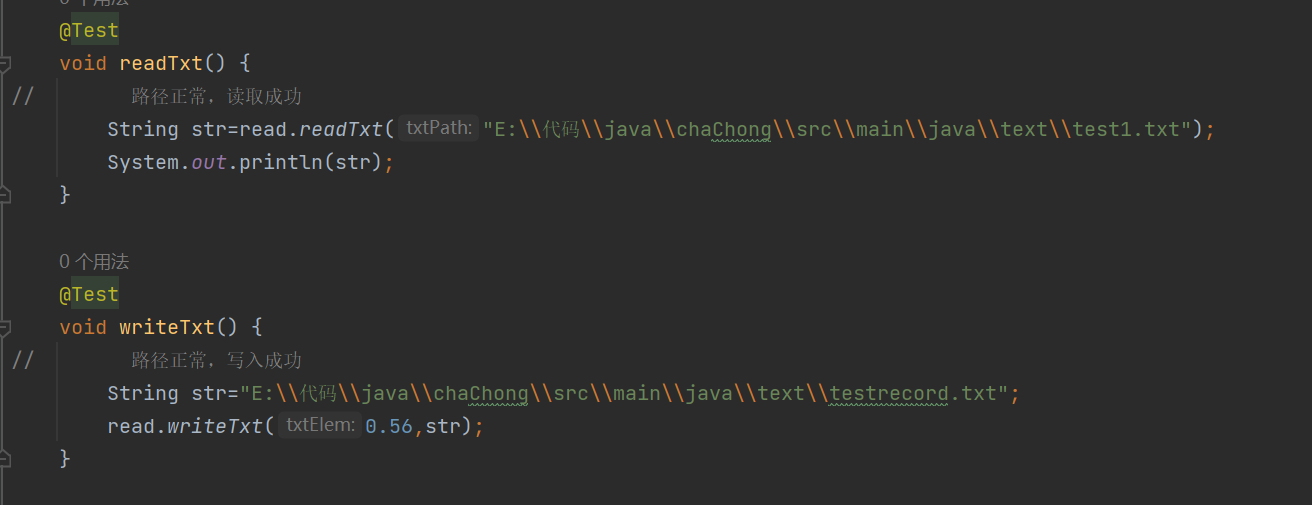
测试结果

SimHash类测试
测试代码
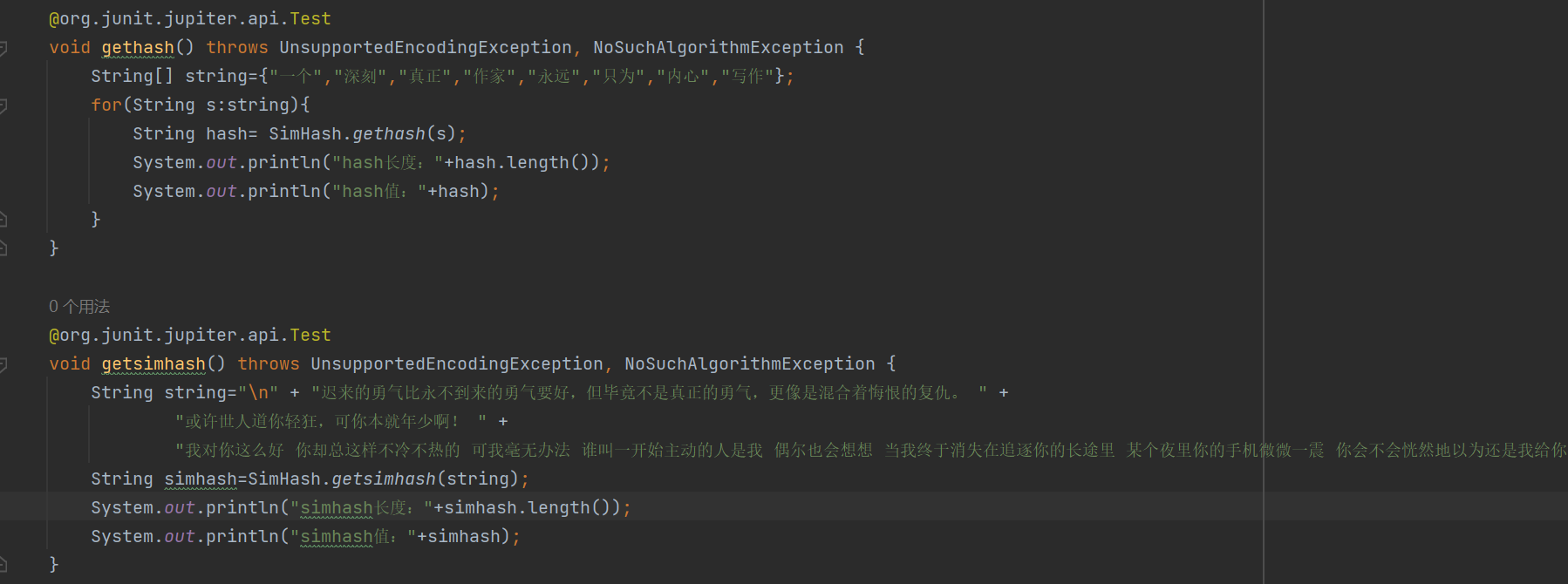
测试结果

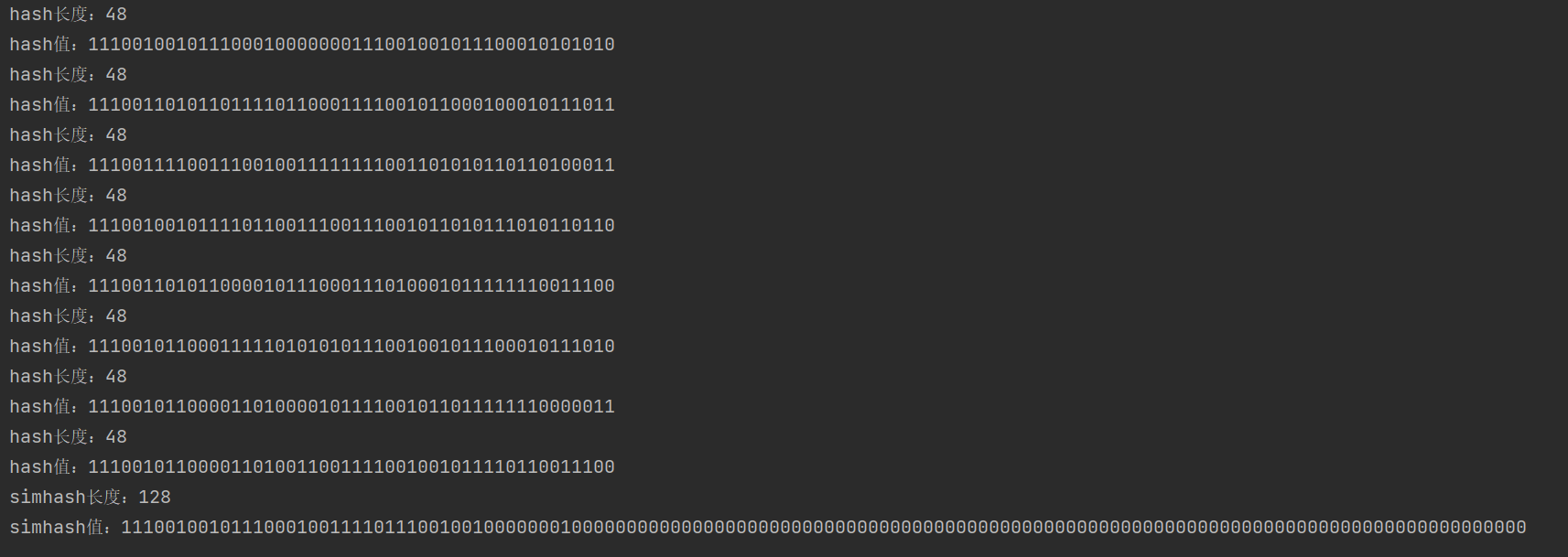
Hamming类测试
测试代码
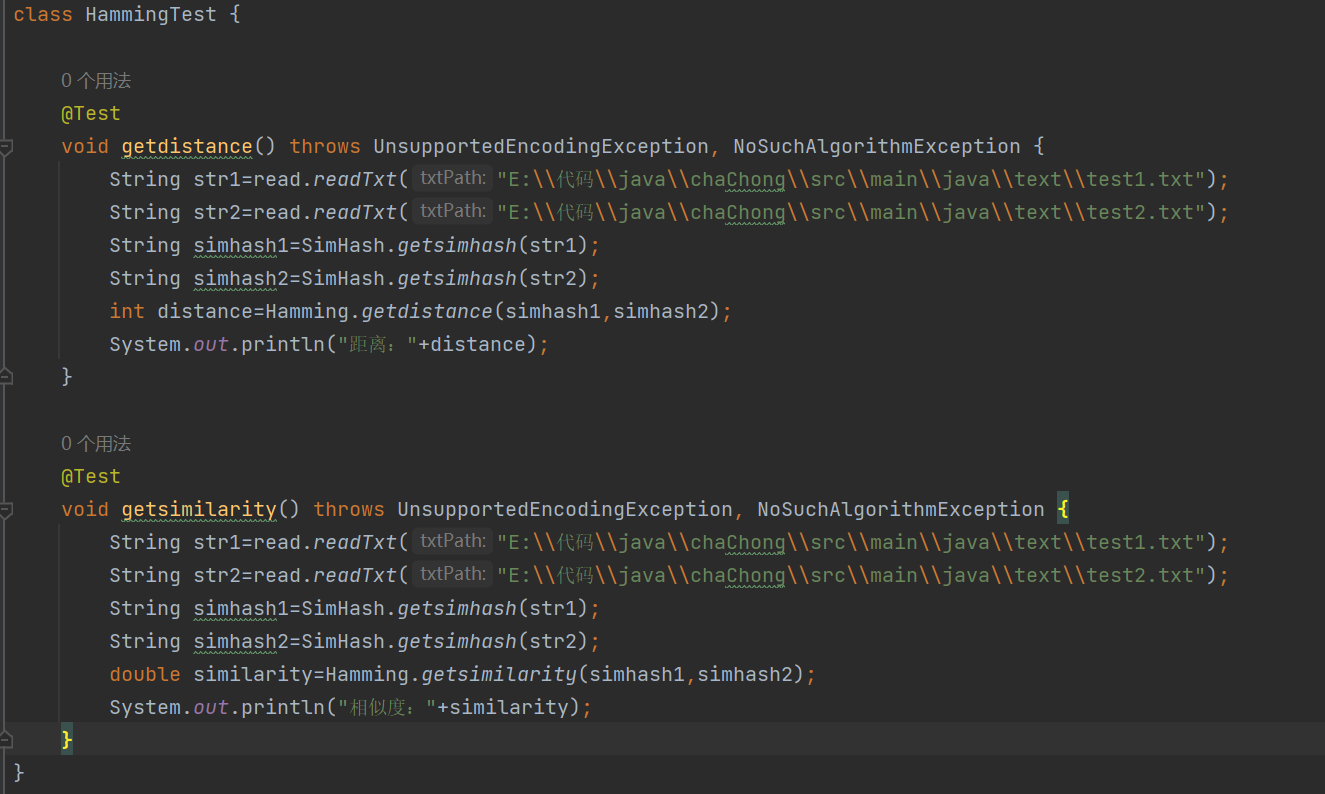
测试结果

Main类测试
测试代码
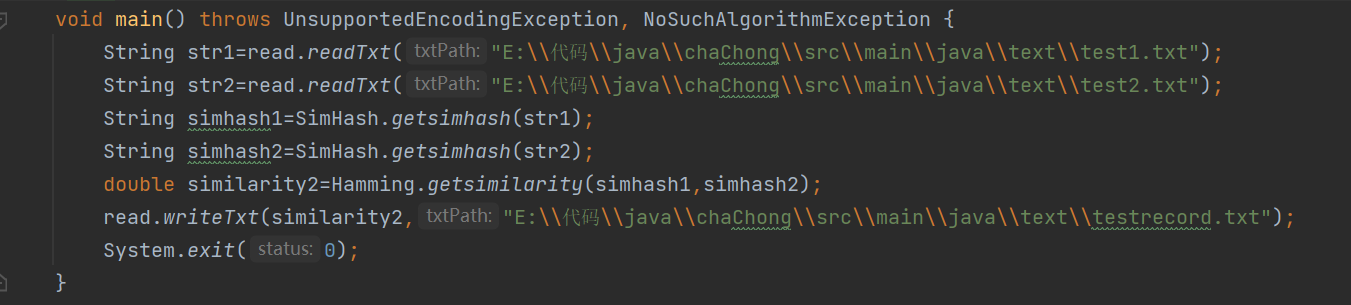
测试结果

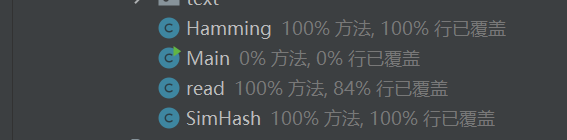
代码覆盖率
三、计算模块部分异常处理说明。
异常:读写模块文件不存在
测试代码
测试错误

改正结果:输入正确的路径
四、测试结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号