C#规范整理·集合和Linq
开始!
前言
C#中的集合表现为数组和若干集合类。不管是数组还是集合类,它们都有各自的优缺点。如何使用好集合是我们在开发过程中必须掌握的技巧。不要小看这些技巧,一旦在开发中使用了错误的集合或针对集合的方法,应用程序将会背离你的预想而运行。正文
### 1.元素数量可变的情况下不应使用数组 在C#中,数组一旦被创建,长度就不能改变。如果我们需要一个动态且可变长度的集合,就应该使用ArrayList或List<T>来创建。而数组本身,尤其是一维数组,在遇到要求高效率的算法时,则会专门被优化以提升其效率。一维数组也称为向量,其性能是最佳的,在IL中使用了专门的指令来处理它们(如newarr、ldelem、ldelema、ldlen和stelem)。从内存使用的角度来讲,数组在创建时被分配了一段固定长度的内存。如果数组的元素是值类型,则每个元素的长度等于相应的值类型的长度;如果数组的元素是引用类型,则每个元素的长度为该引用类型的IntPtr.Size。数组的存储结构一旦被分配,就不能再变化。而ArrayList是数组结构,可以动态地增减内存空间,如果ArrayList存储的是值类型,则会为每个元素增加12字节的空间,其中4字节用于对象引用,8字节是元素装箱时引入的对象头。List<T>是ArrayList的泛型实现,它省去了拆箱和装箱带来的开销。
注意
由于数组本身在内存上的特点,因此在使用数组的过程中还应该注意大对象的问题。所谓“大对象”,是指那些占用内存超过85 000字节的对象,它们被分配在大对象堆里。大对象的分配和回收与小对象相比,都不太一样,尤其是回收,大对象在回收过程中会带来效率很低的问题。所以,不能肆意对数组指定过大的长度,这会让数组成为一个大对象。
- 如果一定要动态改变数组的长度,一种方法是将数组转换为ArrayList或List<T>,需要扩容时,内部数组将自动翻倍扩容
- 还有一种方法是用数组的复制功能。数组继承自System.Array,抽象类System.Array提供了一些有用的实现方法,其中就包含了Copy方法,它负责将一个数组的内容复制到另外一个数组中。无论是哪种方法,改变数组长度就相当于重新创建了一个数组对象。
2.多数情况下使用foreach进行循环遍历
采用foreach最大限度地简化了代码。它用于遍历一个继承了IEmuerable或IEmuerable<T>接口的集合元素。借助于IL代码可以看到foreach还是本质就是利用了迭代器来进行集合遍历。如下:
List<object>list=new List<object>();
using(List<object>.Enumerator CS$5$0000=list.GetEnumerator())
{
while(CS$5$0000.MoveNext())
{
object current=CS$5$0000.Current;
}
}
除了代码简洁之外,foreach还有两个优势
- 自动将代码置入try-finally块
- 若类型实现了IDispose接口,它会在循环结束后自动调用Dispose方法。
3.foreach不能代替for
- foreach存在的一个问题是:它不支持循环时对集合进行增删操作。 取而代之的方法是使用for循环。
不支持原因:
-
foreach循环使用了迭代器进行集合的遍历,它在FCL提供的迭代器内部维护了一个对集合版本的控制。那么什么是集合版本?简单来说,其实它就是一个整型的变量,任何对集合的增删操作都会使版本号加1。foreach循环会调用MoveNext方法来遍历元素,在MoveNext方法内部会进行版本号的检测,一旦检测到版本号有变动,就会抛出InvalidOperationException异常。
-
如果使用for循环就不会带来这样的问题。for直接使用索引器,它不对集合版本号进行判断,所以不存在因为集合的变动而带来的异常(当然,超出索引长度这种情况除外)。
public bool MoveNext()
{
List<T>list=this.list;
if((this.version==list._version)&&(this.index<list._size))
{
this.current=list._items[this.index];
this.index++;
return true;
}
return this.MoveNextRare();
}
无论是for循环还是foreach循环,内部都是对该数组的访问,而迭代器仅仅是多进行了一次版本检测。事实上,在循环内部,两者生成的IL代码也是差不多的。
4.使用更有效的对象和集合初始化
举例:
class Program {
static void Main(string[]args)
{
Person person=new Person(){Name="Mike",Age=20};
}
}
class Person
{
public string Name{get;set;}
public int Age{get;set;}
}
对象初始化设定项支持在大括号中对自动实现的属性进行赋值。以往只能依靠构造方法传值进去,或者在对象构造完毕后对属性进行赋值。现在这些步骤简化了,初始化设定项实际相当于编译器在对象生成后对属性进行了赋值。
集合初始化也同样进行了简化:
List<Person>personList=new List<Person>( )
{
new Person() {Name="Rose",Age=19},
mike,
null
};
重点:初始化设定项绝不仅仅是为了对象和集合初始化的方便,它更重要的作用是为LINQ查询中的匿名类型进行属性的初始化。由于LINQ查询返回的集合中匿名类型的属性都是只读的,如果需要为匿名类型属性赋值,或者增加属性,只能通过初始化设定项来进行。初始化设定项还能为属性使用表达式。
举例
List<Person>personList2=new List<Person>()
{
new Person(){Name="Rose",Age=19},
new Person(){Name="Steve",Age=45},
new Person(){Name="Jessica",Age=20}
};
var pTemp=from p in personList2
select new {p.Name, AgeScope=p.Age>20?"Old":"Young"};
foreach(var item in pTemp)
{
Console.WriteLine(string.Format("{0}:{1}",item.Name,item.AgeScope));
}
5.使用泛型集合代替非泛型集合
注意,非泛型集合在System.Collections命名空间下,对应的泛型集合则在System.Collections.Generic命名空间下。
泛型的好处不言而喻,,如果对大型集合进行循环访问、转型或拆箱和装箱操作,使用ArrayList这样的传统集合对效率的影响会非常大。鉴于此,微软提供了对泛型的支持。泛型使用一对<>括号将实际的类型括起来,然后编译器和运行时会完成剩余的工作。
6.选择正确的集合
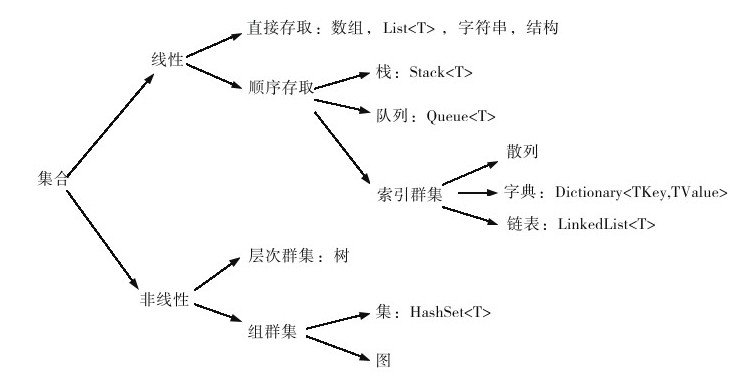
要选择正确的集合,首先需要了解一些数据结构的知识。所谓数据结构,就是相互之间存在一种或多种特定关系的数据元素的集合
说明
-
直接存储结构的优点是:向数据结构中添加元素是很高效的,直接放在数据末尾的第一个空位上就可以了。它的缺点是:向集合插入元素将会变得低效,它需要给插入的元素腾出位置并顺序移动后面的元素。
如果集合的数目固定并且不涉及转型,使用数组效率高,否则就使用List<T>(该使用数组的时候,还是要使用数组) -
顺序存储结构,即线性表。线性表可动态地扩大和缩小,它在一片连续的区域中存储数据元素。线性表不能按照索引进行查找,它是通过对地址的引用来搜索元素的,为了找到某个元素,它必须遍历所有元素,直到找到对应的元素为止。所以,线性表的优点是插入和删除数据效率高,缺点是查找的效率相对来说低一些。
-
队列Queue<T>遵循的是先入先出的模式,它在集合末尾添加元素,在集合的起始位置删除元素。
-
栈Stack<T>遵循的是后入先出的模式,它在集合末尾添加元素,同时也在集合末尾删除元素。
-
字典Dictionary<TKey, TValue>存储的是键值对,值在基于键的散列码的基础上进行存储。字典类对象由包含集合元素的存储桶组成,每一个存储桶与基于该元素的键的哈希值关联。如果需要根据键进行值的查找,使用Dictionary<TKey, TValue>将会使搜索和检索更快捷。
-
双向链表LinkedList<T>是一个类型为LinkedListNode的元素对象的集合。当我们觉得在集合中插入和删除数据很慢时,就可以考虑使用链表。如果使用LinkedList<T>,我们会发现此类型并没有其他集合普遍具有的Add方法,取而代之的是AddAfter、AddBefore、AddFirst、AddLast等方法。双向链表中的每个节点都向前指向Previous节点,向后指向Next节点。
-
在FCL中,非线性集合实现得不多。非线性集合分为层次集合和组集合。层次集合(如树)在FCL中没有实现。组集合又分为集和图,集在FCL中实现为HashSet<T>,而图在FCL中也没有对应的实现。
集的概念本意是指存放在集合中的元素是无序的且不能重复的。 -
除了上面提到的集合类型外,还有其他几个要掌握的集合类型,它们是在实际应用中发展而来的对以上基础类型的扩展:SortedList<T>、SortedDictionary<TKey, TValue>、Sorted-Set<T>。它们所扩展的对应类分别为List<T>、Dictionary<TKey, TValue>、HashSet<T>,作用是将原本无序排列的元素变为有序排列。
-
除了排序上的需求增加了上面3个集合类外,在命名空间System.Collections.Concurrent下,还涉及几个多线程集合类。它们主要是:
- ConcurrentBag<T>对应List<T>
- ConcurrentDictionary<TKey, TValue>对应Dictionary<TKey, TValue>
- ConcurrentQueue<T>对应Queue<T>
- ConcurrentStack<T>对应Stack<T>
FCL集合图如下: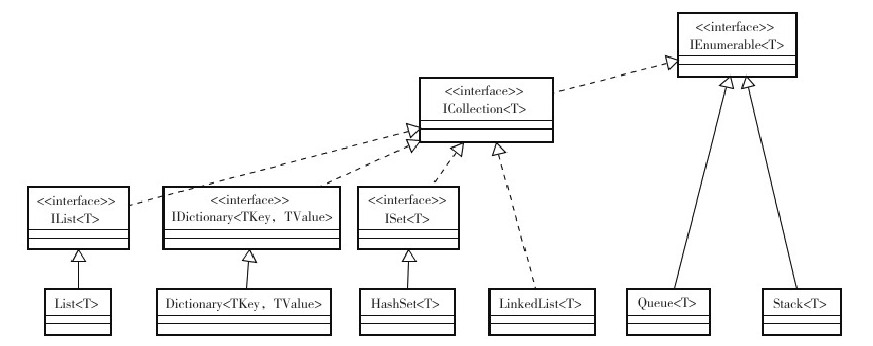
7.确保集合的线程安全
集合线程安全是指在多个线程上添加或删除元素时,线程之间必须保持同步。
泛型集合一般通过加锁来进行安全锁定,如下:
static object sycObj=new object();
static void Main(string[]args)
{
//object sycObj=new object();
Thread t1=new Thread(()=>{
//确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
lock(sycObj)
{
foreach(Person item in list)
{
Console.WriteLine("t1:"+item.Name);
Thread.Sleep(1000);
}
}
}
8.避免将List<T>作为自定义集合类的基类
如果要实现一个自定义的集合类,不应该以一个FCL集合类为基类,而应该扩展相应的泛型接口。FCL集合类应该以组合的形式包含至自定义的集合类,需扩展的泛型接口通常是IEnumer-able<T>和ICollection<T>(或ICollection<T>的子接口,如IList<T>),前者规范了集合类的迭代功能,后者则规范了一个集合通常会有的操作。
List<T>基本上没有提供可供子类使用的protected成员(从object中继承来的Finalize方法和Member-wiseClone方法除外),也就是说,实际上,继承List<T>并没有带来任何继承上的优势,反而丧失了面向接口编程带来的灵活性。而且,稍加不注意,隐含的Bug就会接踵而至。
9.迭代器应该是只读的
FCL中的迭代器只有GetEnumerator方法,没有SetEnumerator方法。所有的集合类也没有一个可写的迭代器属性。
原因有二
- 这违背了设计模式中的开闭原则。被设置到集合中的迭代器可能会直接导致集合的行为发生异常或变动。一旦确实需要新的迭代需求,完全可以创建一个新的迭代器来满足需求,而不是为集合设置该迭代器,因为这样做会直接导致使用到该集合对象的其他迭代场景发生不可知的行为。
- 现在,我们有了LINQ。使用LINQ可以不用创建任何新的类型就能满足任何的迭代需求。
10.谨慎集合属性的可写操作
如果类型的属性中有集合属性,那么应该保证属性对象是由类型本身产生的。如果将属性设置为可写,则会增加抛出异常的几率。一般情况下,如果集合属性没有值,则它返回的Count等于0,而不是集合属性的值为null。
11.使用匿名类型存储LINQ查询结果(最佳搭档)
从.NET 3.0开始,C#开始支持一个新特性:匿名类型。匿名类型由var、赋值运算符和一个非空初始值(或以new开头的初始化项)组成。匿名类型有如下的基本特性:
- 既支持简单类型也支持复杂类型。简单类型必须是一个非空初始值,复杂类型则是一个以new开头的初始化项;
- 匿名类型的属性是只读的,没有属性设置器,它一旦被初始化就不可更改;
- 如果两个匿名类型的属性值相同,那么就认为两个匿名类型相等;
- 匿名类型可以在循环中用作初始化器;
- 匿名类型支持智能感知;
- 还有一点,虽然不常用,但是匿名类型确实也可以拥有方法。
11. 在查询中使用Lambda表达式
LINQ实际上是基于扩展方法和Lambda表达式的,理解了这一点就不难理解LINQ。任何LINQ查询都能通过调用扩展方法的方式来替代,如下面的代码所示:
foreach(var item in personList.Select(person=>new{PersonName= person.Name,CompanyName=person.CompanyID==0?"Micro":"Sun"}))
{
Console.WriteLine(string.Format("{0}\t:{1}",item.PersonName, item.CompanyName));
}
针对LINQ设计的扩展方法大多应用了泛型委托。System命名空间定义了泛型委托Action、Func和Predicate。可以这样理解这三个委托:Action用于执行一个操作,所以它没有返回值;Func用于执行一个操作并返回一个值;Predicate用于定义一组条件并判断参数是否符合条件。Select扩展方法接收的就是一个Func委托,而Lambda表达式其实就是一个简洁的委托,运算符“=>”左边代表的是方法的参数,右边的是方法体。
12.理解延迟求值和主动求值之间的区别
样例如下:
List<int>list=new List<int>(){0,1,2,3,4,5,6,7,8,9};
var temp1=from c in list where c>5 select c;
var temp2=(from c in list where c>5 select c).ToList<int>();
在使用LINQ to SQL时,延迟求值能够带来显著的性能提升。举个例子:如果定义了两个查询,而且采用延迟求值,CLR则会合并两次查询并生成一个最终的查询。
13.区别LINQ查询中的IEnumerable<T>和IQueryable<T>
LINQ查询方法一共提供了两类扩展方法,在System.Linq命名空间下,有两个静态类:Enumerable类,它针对继承了IEnumerable<T>接口的集合类进行扩展;Queryable类,它针对继承了IQueryable<T>接口的集合类进行扩展。稍加观察我们会发现,接口IQueryable<T>实际也是继承了IEnumerable<T>接口的,所以,致使这两个接口的方法在很大程度上是一致的。那么,微软为什么要设计出两套扩展方法呢?
我们知道,LINQ查询从功能上来讲实际上可分为三类:LINQ to OBJECTS、LINQ to SQL、LINQ to XML(本建议不讨论)。设计两套接口的原因正是为了区别对待LINQ to OBJECTS、LINQ to SQL,两者对于查询的处理在内部使用的是完全不同的机制。针对LINQ to OBJECTS时,使用Enumerable中的扩展方法对本地集合进行排序和查询等操作,查询参数接受的是Func<>。Func<>叫做谓语表达式,相当于一个委托。针对LINQ toSQL时,则使用Queryable中的扩展方法,它接受的参数是Ex-pression<>。Expression<>用于包装Func<>。LINQ to SQL引擎最终会将表达式树转化成为相应的SQL语句,然后在数据库中执行。
那么,到底什么时候使用IQueryable<T>,什么时候使用IEnumerable<T>呢?简单表述就是:本地数据源用IEnumerable<T>,远程数据源用IQueryable<T>。
注意
在使用IQueryable<T>和IEnumerable<T>的时候还需要注意一点,IEnumerable<T>查询的逻辑可以直接用我们自己所定义的方法,而IQueryable<T>则不能使用自定义的方法,它必须先生成表达式树,查询由LINQ to SQL引擎处理。在使用IQueryable<T>查询的时候,如果使用自定义的方法,则会抛出异常。
13.使用LINQ取代集合中的比较器和迭代器
LINQ提供了类似于SQL的语法来实现遍历、筛选与投影集合的功能。借助于LINQ的强大功能,我们通过两条语句就能实现上述的排序要求。
var orderByBonus=from s in companySalary orderby s.Bonus select s;
foreach实际会隐含调用的是集合对象的迭代器。以往,如果我们要绕开集合的Sort方法对集合元素按照一定的顺序进行迭代,则需要让类型继承IEnumerable接口(泛型集合是IEnumerable<T>接口),实现一个或多个迭代器。现在从LINQ查询生成匿名类型来看,相当于可以无限为集合增加迭代需求。
有了LINQ之后,我们是否就不再需要比较器和迭代器了呢?答案是否定的。我们可以利用LINQ的强大功能简化自己的编码,但是LINQ功能的实现本身就是借助于FCL泛型集合的比较器、迭代器、索引器的。LINQ相当于封装了这些功能,让我们使用起来更加方便。在命名空间System.Linq下存在很多静态类,这些静态类存在的意义就是为FCL的泛型集合提供扩展方法
- 强烈建议你利用LINQ所带来的便捷性,但我们仍需掌握比较器、迭代器、索引器的原理,以便更好地理解LINQ的思想,写出更高质量的代码。最好是能看懂Linq源码。
public static IOrderedEnumerable<TSource>OrderBy<TSource,TKey>(this IEnumerable<TSource>source,Func<TSource,TKey>keySelector){ //省略}
14.在LINQ查询中避免不必要的迭代
- 比如常使用First()方法,First方法实际完成的工作是:搜索到满足条件的第一个元素,就从集合中返回。如果没有符合条件的元素,它也会遍历整个集合。
- 与First方法类似的还有Take方法,Take方法接收一个整型参数,然后为我们返回该参数指定的元素个数。与First一样,它在满足条件以后,会从当前的迭代过程直接返回,而不是等到整个迭代过程完毕再返回。如果一个集合包含了很多的元素,那么这种查询会为我们带来可观的时间效率。
会运用First和Take等方法,都会让我们避免全集扫描,大大提高效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号