
iptables命令介绍
什么是netfilter
Netfilter是Linux操作系统中的一个网络数据包过滤框架,它提供了强大的网络数据包处理功能。Netfilter可以在Linux内核中的网络协议栈中的不同层级进行数据包过滤、修改和转发操作。
Netfilter的主要功能是实现网络包过滤和网络地址转换(Network Address Translation,NAT)。它可以在数据包进入和离开Linux系统的网络接口时进行处理,根据预先定义的规则集对数据包进行过滤或修改。这些规则可以根据源地址、目标地址、协议类型、端口等条件进行匹配,并根据配置的动作来决定数据包的处理方式,如允许通过、丢弃、修改等。
Netfilter使用一个称为iptables的用户空间工具来配置和管理规则集。iptables允许系统管理员创建、修改和删除规则,以控制网络流量的流向和处理方式。管理员可以定义各种规则,如允许特定端口的数据包通过、阻止某些IP地址的访问、实现端口映射等
Netfilter还提供了网络地址转换(NAT)功能,允许将内部网络的私有IP地址映射为外部网络的公共IP地址,实现多台主机共享单个公网IP地址的功能。NAT功能在实际应用中非常重要,特别是在家庭网络和企业网络中,可以帮助有效管理网络连接。
总结来说,Netfilter是Linux操作系统中的一个网络数据包过滤框架,它提供了强大的网络数据包处理功能,包括过滤、修改和转发。通过使用iptables工具,系统管理员可以配置和管理Netfilter规则集,从而控制网络流量的流向和处理方式。同时,Netfilter还提供了网络地址转换(NAT)功能,允许实现内部网络与外部网络之间的IP地址映射。
什么是用户空间?什么是内核空间
用户空间是指计算机系统中供用户程序执行的区域。用户空间中运行的应用程序通常是由用户启动的,如文本编辑器、浏览器、游戏等。在用户空间中,应用程序可以执行各种操作,如读写文件、网络通信、图形界面显示等。用户空间通常是受限的,它只能访问特定的资源和执行特定的操作。这是为了确保安全性和防止应用程序对系统的滥用。
内核空间是操作系统的核心部分,它控制着计算机系统的各种硬件和软件资源。内核空间有更高的权限级别,可以直接访问系统的所有资源,并执行关键的操作,如管理进程、文件系统、内存管理、设备驱动程序等。内核空间负责调度和协调用户空间中运行的应用程序,并提供接口供应用程序使用系统功能。内核空间通常是受保护的,只有在特定的条件下才能访问,以防止用户程序对系统的破坏
用户空间和内核空间之间通过系统调用(system call)进行通信。当应用程序需要执行一些需要更高权限的操作时,它会通过系统调用请求内核空间执行相应的操作。系统调用是用户空间和内核空间之间的接口,它允许应用程序以受控的方式访问内核功能。
总而言之,用户空间是应用程序运行的环境,受限但更安全,而内核空间是操作系统的核心,具有更高的权限和对系统资源的直接访问能力。
NAT(Network Address Translation)和 DNAT(Destination NAT)都是网络中常见的技术,用于在 IP 数据包在网络中传输时修改源地址或目标地址
NAT(网络地址转换)是一种将私有 IP 地址转换为公共 IP 地址的技术。它通常用于解决 IPv4 地址短缺的问题。当内部网络中的主机通过路由器或防火墙连接到外部网络时,NAT 技术可以将内部主机的私有 IP 地址转换为公共 IP 地址,以便与外部网络进行通信。这样,内部主机的通信流量可以通过单个公共 IP 地址共享出去,实现了网络地址的复用。
DNAT(目标网络地址转换)是 NAT 的一种特定形式。它用于在传输数据包时修改数据包的目标 IP 地址。DNAT 通常用于将外部请求转发到内部网络中的特定主机或服务。当外部网络的请求到达防火墙或路由器时,DNAT 技术可以将目标 IP 地址修改为内部网络中的主机的私有 IP 地址,并将数据包转发到该内部主机。这样,内部主机可以通过防火墙或路由器暴露在外部网络上,接收来自外部网络的请求
总结起来,NAT 是一种网络地址转换技术,用于在内部网络和外部网络之间转换 IP 地址。而 DNAT 是 NAT 的一种特定形式,用于修改数据包的目标 IP 地址,实现外部请求的转发到内部网络中的特定主机或服务。这些技术在网络中起着重要的作用,帮助实现网络连接和通信。
网络地址的复用:在网络中,地址复用指的是多个主机或设备共享相同的网络地址(IP 地址)。这是通过使用网络地址转换(NAT)技术实现的
由于 IPv4 地址的有限性,为了充分利用可用的公共 IP 地址资源,网络地址复用成为一种常见的做法。在一个局域网(例如家庭网络或企业网络)中,可以分配给每个主机一个私有 IP 地址,这些私有 IP 地址不是在公共互联网上可路由的。然后,通过使用 NAT 技术,内部主机的通信可以经过一个或多个公共 IP 地址来访问互联网。
当内部主机发送数据包时,NAT 会将源 IP 地址从私有 IP 地址转换为公共 IP 地址,并将该映射信息保存在转换表中。然后,来自互联网的响应数据包会根据转换表中的映射信息被转发回相应的内部主机。这样,多个内部主机可以共享同一个公共 IP 地址,并且外部网络无法直接访问内部主机的私有 IP 地址。
网络地址复用的好处是可以节约公共 IP 地址的使用,减轻了 IPv4 地址短缺的问题。它允许在一个组织或网络中使用较少的公共 IP 地址,而不需要为每个主机都分配一个唯一的公共 IP 地址。这对于家庭网络、企业网络和云服务提供商等都非常有用
iptables的工作机制
iptables 是一个基于 Linux 内核的防火墙工具,它通过管理防火墙规则来控制网络数据包的流动。下面是 iptables 的工作机制的简要说明:
1、防火墙表(Tables):iptables 使用不同的表来组织和管理防火墙规则。常见的表包括 filter、nat 和 mangle。其中,filter 表用于过滤和控制数据包的流动,nat 表用于网络地址转换,mangle 表用于修改数据包的特定字段
2、链(Chains):每个表包含一系列链,链是规则的集合。常见的链包括 INPUT、OUTPUT 和 FORWARD。INPUT 链用于处理进入系统的数据包,OUTPUT 链用于处理离开系统的数据包,FORWARD 链用于处理通过系统进行转发的数据包。
3、规则(Rules):规则是 iptables 的核心组成部分。每个链包含多个规则,规则定义了如何处理符合特定条件的数据包。规则由多个匹配条件(Matches)和动作(Actions)组成。匹配条件用于匹配数据包的特定属性,如源 IP、目标端口等。动作定义了对匹配的数据包要执行的操作,如接受、丢弃、重定向等
4、匹配和动作过程:当数据包进入系统时,它会被逐个规则进行匹配,直到找到与数据包匹配的规则。如果数据包匹配到一条规则,那么定义在该规则上的动作将被执行。动作可以修改数据包的内容、转发数据包到另一个链,或者丢弃数据包等
5、链的优先级和默认策略:规则按照顺序进行匹配,因此链中的规则顺序非常重要。可以使用 iptables 命令来添加、删除和修改规则的顺序。如果数据包在链中没有匹配到任何规则,将根据链的默认策略来决定数据包的命运,常见的默认策略包括接受(ACCEPT)、丢弃(DROP)和拒绝(REJECT)等
通过配置适当的规则,iptables 可以实现网络流量的过滤、转发、地址转换等功能,从而保护系统安全、管理网络连接,并提供网络服务。具体的 iptables 用法和规则设置将根据具体的需求和网络环境而有所不同。
进入/离开本机的外网接口是路由前还是路由后
进入本机的外网接口(如通过互联网访问本机)以及离开本机的外网接口(如本机向外发送数据包)均是在路由后的过程。
当数据包进入本机的外网接口时,它首先会经过物理层和数据链路层的处理,包括接收、解封装等操作。然后,数据包将传递到网络层,在这一阶段,路由将发挥作用。路由根据数据包的目标 IP 地址和路由表中的信息,确定数据包的下一跳,即数据包应该发送到哪个网络接口或下一个路由器。这个过程被称为路由选择。一旦下一跳确定,数据包将通过相应的外网接口发送出去。
进入本机的内网接口和离开本机的内网接口是在路由前进行的。
当数据包进入本机的内网接口时,它首先会经过物理层和数据链路层的处理,包括接收、解封装等操作。然后,数据包将传递到网络层,在这一阶段,路由之前的处理将发挥作用。这个阶段主要包括以下几个步骤:
1、目标 MAC 地址解析:本机会检查数据包的目标 MAC 地址,如果目标 MAC 地址是本机网卡的 MAC 地址,则表示数据包是发送给本机的,继续处理;否则,数据包将被丢弃或转发到适当的目标。
2、IP 地址解析:本机会检查数据包的目标 IP 地址,如果目标 IP 地址是本机的 IP 地址之一,则表示数据包是发送给本机的,继续处理;否则,数据包将被丢弃或转发到适当的目标
3、网络层处理:在目标 IP 地址确定后,本机会根据数据包的协议类型(如 TCP、UDP、ICMP 等)将数据包传递到相应的上层协议进行处理。
在离开本机的内网接口时,数据包将经过类似的处理过程。本机上层协议生成的数据包将经过网络层处理和目标 IP 地址解析,然后通过数据链路层封装,并发送到合适的内网接口。
总之,进入本机的内网接口和离开本机的内网接口是在路由前进行的,这些接口用于处理数据包的物理层和数据链路层的操作,以及目标 MAC 地址解析和目标 IP 地址解析等处理。一旦数据包经过这些处理后,路由将根据目标 IP 地址进行决策,并将数据包转发到相应的网络接口或下一个路由器
数据包从内核流入用户空间
当数据包从网络流入到内核空间后,它可以进一步被传递到用户空间进行处理。这个过程通常涉及以下步骤:
1、数据包接收:当数据包到达网络接口时,网络驱动程序会将数据包接收到内核空间。这个过程通常包括数据包的解封装和校验
2、包过滤:接收到的数据包将被内核的网络协议栈进行处理。其中的网络协议栈会根据系统中定义的规则(如 iptables 规则)进行包过滤。如果数据包满足特定的过滤规则,则它可以被传递到用户空间进行进一步处理
3、套接字(Socket):如果数据包通过了过滤规则,它可以被传递到用户空间中的应用程序。在用户空间,应用程序可以使用套接字(Socket)接口来接收这些数据包。套接字是一种应用程序与网络协议栈之间进行通信的接口
4、应用程序处理:一旦应用程序通过套接字接收到数据包,它可以对数据包进行进一步的处理,如解析报文内容、执行特定的操作或提供服务等。
从内核流入用户空间时,指的是数据包被传递到运行在操作系统内核之上的应用程序层。在操作系统中,内核是负责管理计算机硬件资源和提供基本系统服务的核心组件,而用户空间是指运行在内核之上的应用程序所在的环境。
为什么nat只能在PREROUTING ,OUTPUT ,POSTROUTING这3个链上
NAT(Network Address Translation,网络地址转换)操作只能在 iptables 的 PREROUTING、OUTPUT 和 POSTROUTING 这三个链上进行,是由于 NAT 涉及到数据包在网络层的转发过程以及源/目标地址的修改,需要在特定的阶段进行处理。
- PREROUTING 链:在数据包到达系统后,进入网络协议栈的早期阶段,此时数据包的目标地址还没有被修改。PREROUTING 链用于对目标地址进行修改或重定向,以实现端口转发(Port Forwarding)或目标地址转换(Destination NAT)等功能
- OUTPUT 链:用于处理由本机发起的数据包,即本机产生的出站流量。OUTPUT 链在数据包离开系统之前的处理阶段,用于对源地址进行修改或重定向,实现源地址转换(Source NAT)等功能
- POSTROUTING 链:在数据包经过路由决策后,即将离开系统之前的最后阶段。POSTROUTING 链用于对数据包的源地址、目标地址或端口进行修改,以实现源地址转换、目标地址转换或源/目标地址端口转换等功能。
这三个链涵盖了数据包在网络层的不同阶段,可以对数据包的源/目标地址进行修改或重定向。这样可以灵活地进行网络地址转换,实现网络连接的映射、隐藏内部网络拓扑、提供出口地址转换等功能。
其他链,如INPUT、FORWARD等,是在数据包已经完成路由决策之后进行处理的,而NAT操作需要在路由决策之前或之后进行,因此只能在 PREROUTING、OUTPUT 和 POSTROUTING 这三个链上进行
INPUT 链: INPUT 链用于处理进入本机的数据包,即目标地址是本机的数据包。在 INPUT 链中,数据包已经到达本机,并且需要被接受和处理。NAT 操作通常不适用于输入链,因为 NAT 操作需要在数据包进入系统之前进行,而 INPUT 链是在数据包已经到达系统之后进行处理。因此,在 INPUT 链上应用 NAT 操作可能无法实现预期的转换效果
FORWARD 链: FORWARD 链用于处理通过本机进行转发的数据包,即目标地址是其他主机的数据包。在 FORWARD 链中,数据包需要经过本机作为路由器或网关的转发决策。虽然在 FORWARD 链中进行 NAT 操作理论上是可能的,但这样做可能会引起数据包的处理顺序问题。由于 NAT 操作涉及到修改数据包的源/目标地址和端口等信息,如果在 FORWARD 链上应用 NAT 操作,可能会导致转发决策过早地进行,从而影响到 NAT 的正确执行。
因此,为了确保 NAT 操作的正确性和一致性,一般建议将 NAT 操作应用于 PREROUTING、OUTPUT 和 POSTROUTING 链。这些链的位置可以确保在适当的时机进行地址转换和转发处理,以实现预期的网络地址转换效果。
INPUT、FORWARD在iptables中分别代表什么意思
在 iptables 中,INPUT 和 FORWARD 是两个重要的过滤表(Filter Table)链,用于控制网络数据包的流向和处理。
1、INPUT 链: INPUT 链用于处理进入本机的数据包,即目标地址是本机的数据包。当数据包到达本机后,经过物理层和数据链路层的处理后,进入网络协议栈的早期阶段。在这个阶段,数据包进入 INPUT 链进行处理。INPUT 链用于控制进入本机的数据包是否接受,以及对数据包的进一步处理,如允许、拒绝或重定向等操作。在 INPUT 链中可以定义规则,根据源 IP 地址、协议类型、目标端口等条件对进入本机的数据包进行过滤和处理。
2、FORWARD 链: FORWARD 链用于处理通过本机进行转发的数据包,即目标地址是其他主机的数据包。当本机作为路由器或网关,需要将数据包从一个接口转发到另一个接口时,数据包会进入 FORWARD 链进行处理。FORWARD 链用于控制通过本机的数据包是否转发,以及对数据包的进一步处理,如允许、拒绝或重定向等操作。在 FORWARD 链中可以定义规则,根据源 IP 地址、目标 IP 地址、协议类型、目标端口等条件对通过本机转发的数据包进行过滤和处理。
总结:
- INPUT 链用于处理进入本机的数据包,控制数据包是否接受和进一步处理。
- FORWARD 链用于处理通过本机转发的数据包,控制数据包是否转发和进一步处理
需要注意的是,OUTPUT 链用于处理从本机发出的数据包,即源地址是本机的数据包。它用于控制本机发出的数据包是否允许通过和对数据包的进一步处理。
5条链的关系示意图:
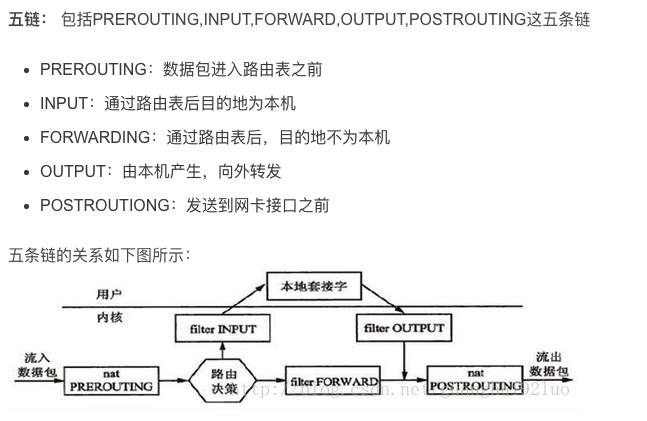
讲的特别好的一篇文章:https://blog.csdn.net/weixin_46560589/article/details/131085125
参考文档:https://blog.51cto.com/u_10551983/1683918?articleABtest=0
https://blog.csdn.net/guanghui92luo/article/details/78865852

 浙公网安备 33010602011771号
浙公网安备 33010602011771号