知识库服务运行卡顿分析及说明文档
原文内容来自于LZ(楼主)的印象笔记,如出现排版异常或图片丢失等问题,可查看当前链接:https://app.yinxiang.com/shard/s17/nl/19391737/5c09c99d-a567-4402-89c2-596b88a3fd4f
场景介绍:
2019-03-26 现场客户反馈知识库服务短时间卡顿的问题说明,从现场拿到的GC日志,以及相关的DUMP文件入手,所书写的一份服务卡顿说明文档,目的则是为了表达服务的运行问题以及服务异常的原因,以及告知客户方运维需要给我们的服务增加机器内存。。。。
由于客户方运维对JAVA应用并不熟悉的情况,所以一直在争论服务的预占用内存以及实际占用内存的问题,根据运维的说法是,你们的这个服务实际只使用了几十兆的内存,而我们给你们这台机器已经提供的8G内存,已经完全够你们这个服务运行使用了。。但是你们的服务还是会出现卡顿的情况,所以,这个锅~ 是要我们这边来通过优化程序来进行处理~ ,但,,但,,,但,,身为铁打的研发人员,怎么会如此轻易屈服,,,,于是有理有据的列出了服务的实际运行问题,用于告知我们的服务运行状态,以及当前实际遇到的问题和优化的方案,最终,,,在双方欢声笑语中确定了最终的优化方案,和平解决问题~~
客户方配合增加下相关的服务器内存,我方也会配合调整下相关的GC参数,最终优化到客户所要求的服务卡顿范围。
调整新生代的大小:
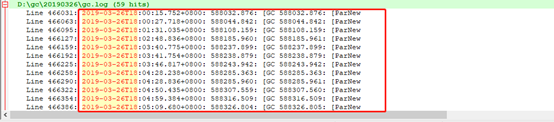
业务高峰期,每一分钟产生一次MinorGC,最快一分钟内产生多次MinorGC,每次停顿约为30MS;
按照高峰访问业务时间段为6点开始计算:在18:00开始到18:05,单位时间内共发生MinorGC次数为12次,如上图所示,每次GC时间为30毫秒,假设接口平均响应时间为50ms,且请求均匀到达,那么在18:00到18:05期间,一共有:(50 + 30)/5的比例请求受到GC的影响,其中GC前到达的请求访问时间都会增加30ms,按照上述的业务时间进行计算,单位时间5分钟内,发生12次MinorGC,即GC的影响请求占比为: (50 + (30 * (12/5))),GC前的请求,在5分钟的单位时间内,每分钟受影响的请求时间为122ms,所以无论是降低单位时间内GC的次数(12),还是降低每次GC的停顿时间(30),都能有效的降低MinorGC时对请求的影响;此处建议新增新生代内存,以减少单位时间内MinorGC的次数;(对于增加新生代的大小后是否会增加每次GC时间的问题,暂不在此次状况内,如有疑问可与我联系;)
服务卡顿高峰期事件说明
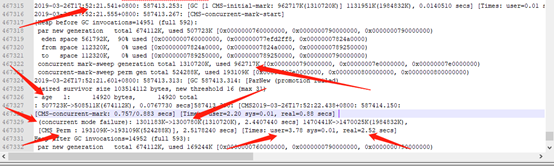
由上图可以看出在26号下午52的时候,正常CMS GC时,新生代被瞬间占满99%,此时触发MinorGC,动态年龄分布范围为 age 1, MinorGC后新生代对象直接晋升至老年代,老年代由原本的962717K提升至1301183K,此时老年代空间不足,CMS并发标记失败(concurrent mode failure),直接进行类的卸载触发CMS Perm,[CMS Perm : 193109K->193109K(524288K)], 2.5178240 secs]此时耗用回收时间为2.5秒;在此之后则是频繁的Full GC
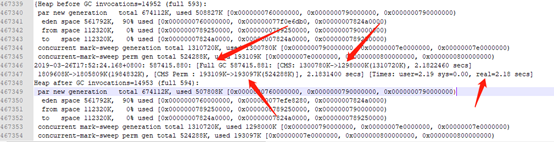
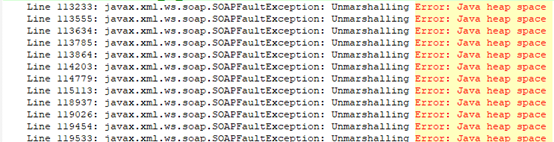
由于Full GC时为STW的,此时对用户线程暂停使用影响到达高峰,导致知识库频繁卡顿,如上图,从最初的17:52开始Full GC外,后续每分钟保持着4次的FULL GC速度进行垃圾回收,尽管Full GC的频率很高,但由于新晋升对象为活跃对象,所以FULL GC的回收并未对内存有实际的效果,如上图所示,FULL GC后,Perm区空间不变,CMS也只回收了2780K;FULL GC的回收时间持续大概10分钟左右,在18:02左右垃圾回收情况好转,部分非活跃对象被正常回收,此时GC卡顿影响时间约10分钟左右;而在对应GC不断回收过程当中,直接映射到知识库日志的信息则是:Unmarshalling Error: Java heap space,如下图:
由上述分析可知,在业务高峰期阶段,由于新生代不断的快速占满,新晋升的对象导致CMS回收失败,而引起不断的FULL GC,导致服务高可用性能降低,我方将会调整对应的CMS回收阀值,保证CMS的顺利回收,除此之外也会优化相关的Remark阶段的新生代回收参数,保证CMS回收时尽可能少的对象标记,最后,调整对应的新生代和老年代各参数之间的比例,以达到最优的服务状态;
扩增服务内存作用说明
按照上述分析可知,我方将会调整对应的GC优化参数以及对应的各内存分区比例,但在现有的服务内存的状态下,当前JVM参数已经为正常比例配置,后续需增加新生代内存,则必须扩增现有的服务内存:
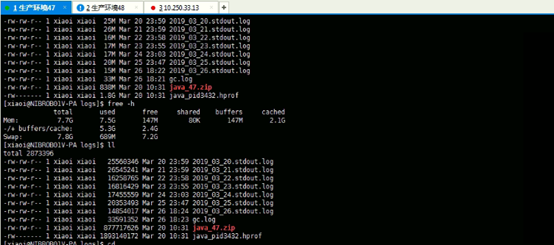
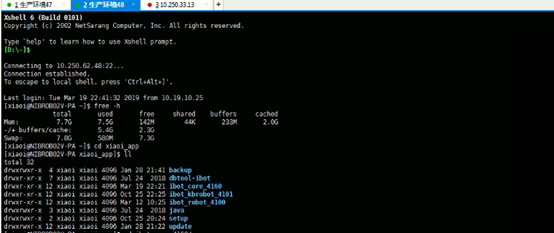
上图为2月26日服务卡顿现象时所获取的服务剩余内存截图:此时剩余可使用内存为147M与142M; 剩余内存的情况不满足现有的JVM参数调整,且剩余的服务内存也很难再满足新线程的请求创建,故需要为现有的生产环境47,48服务分别增加相关的内存,建议:将对应的47和48环境已有的8G内存,升级为16G
预占用内存与服务器内存之间关系
此处简单解释下JVM服务预占用内存和服务器内存之间的关系,由上述的GC分析可知,尽管JVM预占用内存很高,但JVM所预占用的内存都在持续的使用中,而并非客户方运维所说,JVM预占用2G内存,而实际使用内存,只有几十兆的情况,相反JVM预占用内存已经是在持续回收的过程当中;
DUMP分析

26号从客户生产环境所拿Dump文件产生时间为3月20日与此次卡顿事件无关,故此次事件可忽略;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号