
Spark设计与运行原理、基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
目前,Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件,这些组件可以非常容易地把各种处理流程整合在一起,而这样的整合,在实际数据分析过程中是很有意义的。不仅如此,Spark的这种特性还大大减轻了原先需要对各种平台分别管理的依赖负担。下面,通过一张图描述Spark的生态系统,具体如下图1所示。
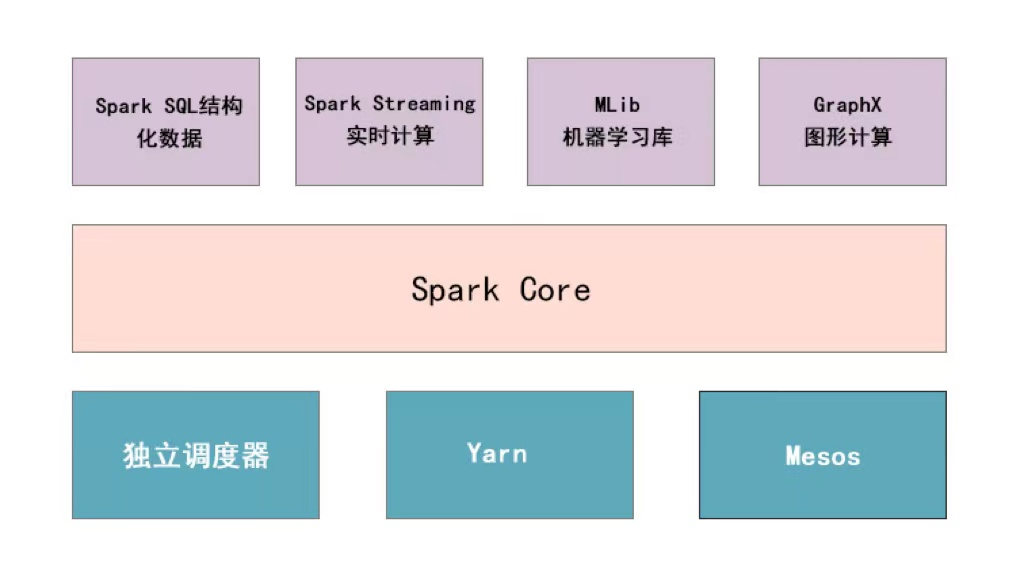
通过上面图片可以看出,Spark生态系统主要包含Spark Core、Spark SQL、Spark Streaming、MLib、GraphX以及独立调度器,下面对上述组件进行一一介绍。推荐了解黑马程序员大数据培训课程。
(1)Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed Datasets,RDD)的API定义,RDD是只读的分区记录的集合,只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
(2)Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、 HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD在处理结构化数据时,开发人员无须编写 MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。
(3)Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core进行快速处理。Spark Streaming支持多种数据源,如 Kafka以及TCP套接字等。
(4)MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
(5) GraphX: Spark提供的分布式图处理框架,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
(6)独立调度器、Yarn、 Mesos: Spark框架可以高效地在一个到数千个节点之间伸缩计算,集群管理器则主要负责各个节点的资源管理工作,为了实现这样的要求,同时获得最大的灵活性, Spark支持在各种集群管理器( Cluster Manager)上运行, Hadoop Yarn、Apache Mesos以及 Spark自带的独立调度器都被称为集群管理器。
Spark生态系统各个组件关系密切,并且可以相互调用,这样设计具有以下显著优势。
(1) Spark生态系统包含的所有程序库和高级组件都可以从 Spark核心引擎的改进中获益。
(2)不需要运行多套独立的软件系统,能够大大减少运行整个系统的资源代价。
(3)能够无缝整合各个系统,构建不同处理模型的应用。
综上所述,Spak框架对大数据的支持从内存计算、实时处理到交互式查询,进而发展到图计算和机器学习模块。Spark生态系统广泛的技术面,一方面挑战占据大数据市场份额最大的Hadoop,另一方面又随时准备迎接后起之秀Flink、Kafka等计算框架的挑战,从而使Spark在大数据领域更好地发展。
2.请阐述Spark的几个主要概念及相互关系:
RDD,DAG,Application, job,stage,task,Master, worker, driver,executor,Claster Manager
1. RDD之间的依赖(以分区为说明)
窄依赖:每一个父RDD的Partition中的数据,最多被子RDD的一个Partition使用(单分区 -> 单分区);
窄依赖在源码里是OneToOneDependency
宽依赖:同一个父RDD的Partition中的数据,被多个子RDD的Partition使用(单分区 -> 多分区),会引起shuffle,数据打乱重组;典型的宽依赖是ByKey的各种算子,依据key进行suffle。
画一张简单的示意图来看宽窄依赖的区别:
2. RDD任务划分原理
窄依赖不会shuffle,所有的RDD分区转换可以并行进行,所以各种task可以在同一个stage中进行;
宽依赖由于会产生shuffle,上一个stage没完,数据不会进行shuffle到下一个stage,下一个stage只能等待,所以宽依赖是划分阶段的依据。
RDD任务切分级别为:Application、Job、Stage、Task
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个action算子生成一个Job;
(3)Stage:遇到一个宽依赖划分一个Stage;
(4)Task:一个分区对应一个task,将Stage划分的结果发送到不同的Executor中执行。
关系:
1个Application中至少有1个Job;
1个Job中依据宽窄依赖划分至少有一个Stage(至少有一个ResultStage);
1个Stage中依据分区至少有一个Task(至少一个分区)。
ps:shuffle之后会产生新的Stage,重新分区
3. Spark中RDD执行阶段划分示意图
通过示意图,分析Spark中任务如何划分,阶段如何划分,依赖关系是怎样的,以及最后如何执行的。
eg:跑一个wordCount的小demo,Spark阶段划分如下
(1)首先通过sc.textfile从文件中读取数据到Partition0和1中;
(2)然后通过flatMap算子进行扁平化,分区不改变;
(3)做统计转换,用map算子,A -> (A,1)变成了元组的形式,分区依然没变;
(4)reduceByKey,相同的key聚合在一起,分区数据被打乱shuffle重组;
(5)collect
整个过程是 窄依赖 -> shuffle -> 宽依赖
调用行动算子的时候,会运行作业(JOB),进行阶段(Stage)的划分以及提交阶段(SubmitStage)后的任务(Task)划分,最后提交任务(submitTask)。
(1)划分阶段(查找shuffle)
提交作业首先划分阶段,首先一定会有一个ResultStage;
然后再看之前有没有其他阶段,根据血缘关系从最后一个RDD往前看,查找宽依赖,即shuffleDependency;
创建ShuffleMapStage,与shuffle后的RDD区别开,
这样阶段划分完毕,形成2个阶段:ShuffleMapStage -------shuffle-----------ResultStage
(2)提交ShuffleMapStage阶段,划分任务
提交ResultStage阶段前,会找上一级阶段,也就是ShuffleMapStage;
接着看ShuffleMapStage有没有上一级阶段,发现没有,开始对ShuffleMapStage阶段划分task;
task数取决于分区数,这里分了2个区,所以划分了2个Task,并行计算,提交给Executor执行;
(3)shuffle等待
shuffle等待上一个阶段出结果,源码中waitChildStage;
(4)提交ResultStage阶段
再从ResultStage开始依次提交各个阶段。
所以总流程是:
划分Stage(从后往前查找shuffle)-> 划分任务Task -> 提交阶段(从前往后提交,shuffle等待)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号