REACT : 语言模型中推理与行动的协同
ReAct:语言模型中推理与行动的协同(ReAct: Synergizing Reasoning and Acting in Language Models)
一、基础信息
|
类别
|
详情
|
|
标题
|
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct:语言模型中推理与行动的协同
|
|
作者
|
Shunyu Yao、Jeffrey Zhao、Dian Yu、Nan Du、Izhak Shafran、Karthik Narasimhan、Yuan Cao(所属机构:1 普林斯顿大学计算机科学系;2 谷歌研究院大脑团队)
|
|
来源
|
国际学习表征会议(ICLR 2023,International Conference on Learning Representations 2023),作为会议论文发表
|
|
发布时间
|
2023 年( arXiv 预印本版本更新时间为 2023 年 3 月 10 日)
|
二、研究背景与问题
1. 研究动机(现有不足)
人类智能的独特之处在于能无缝结合面向任务的行动与语言推理,这种 “推理 - 行动” 协同能帮助人类快速学习新任务、应对未知场景。但现有大语言模型(LLMs)相关研究存在以下两大割裂问题:
- 推理能力局限:链式思维(CoT)等推理方法仅依赖模型内部表征生成静态推理轨迹,未与外部世界关联,易出现事实幻觉(虚构不存在的事实)和推理误差传播(前序错误导致后续推理偏差),例如在问答任务中生成不符合真实信息的结论。
- 行动能力局限:面向交互式决策的语言模型(如用于文本游戏、网页导航)仅聚焦于通过语言先验预测行动,缺乏抽象推理高层目标或维护工作记忆的能力,难以应对复杂环境中的任务规划与异常处理,例如在文本游戏中重复无效行动却无法调整策略。
此外,现有研究未系统性探索 “推理 - 行动” 协同对通用任务解决的价值,缺乏对两者结合能否带来性能提升、可解释性增强等问题的验证。
2. 研究问题
- 如何设计一种通用范式,让大语言模型能交替生成推理轨迹与任务特定行动,实现 “推理引导行动、行动支撑推理” 的协同?
- 这种 “推理 - 行动” 协同范式在知识密集型推理任务(如多跳问答、事实验证)和交互式决策任务(如文本游戏、网页购物)中,能否超越仅推理或仅行动的基线方法,同时提升模型的可解释性与可信度?
- 如何结合模型内部知识(如 CoT 的推理结构)与外部知识(如通过 API 获取的实时信息),进一步优化任务解决性能?


三、Methods
2.1 ReAct 核心框架:推理与行动的协同设计
1. 问题建模
- 环境 - 智能体交互框架:设智能体在时刻\(t\)从环境接收观测\(o_t \in O\),并根据策略\(\pi(a_t | c_t)\)执行行动\(a_t \in A\),其中\(c_t=(o_1,a_1,\cdots,o_{t-1},a_{t-1},o_t)\)为智能体的历史上下文。
- 核心痛点:当上下文到行动的映射(\(c_t \mapsto a_t\))高度复杂时(如多步骤推理后需决策下一步行动),仅行动的智能体易陷入轨迹理解困难(如无法整合多步观测推导正确行动),仅推理的智能体则缺乏外部信息支撑。
2. 行动空间扩展
- 扩展策略:将智能体的行动空间从原始行动集\(A\)扩展为\(\hat{A}=A \cup L\),其中\(L\)为语言空间(即推理轨迹 / 思维的集合)。
- 推理轨迹(Thought)特性:
- 不直接影响外部环境,无观测反馈;
- 作用是基于当前上下文\(c_t\)整合有用信息(如分解目标、提取观测关键信息、调整行动规划),并更新上下文为\(c_{t+1}=(c_t,\hat{a}_t)\),为后续推理或行动提供支撑。
- 示例:在多跳问答中,推理轨迹可分解任务目标(“我需要先搜索 X,找到 Y,再确定 Z”);在文本游戏中,可追踪子目标进度(“已找到刀具,下一步需去水槽清洗”)。
3. 大语言模型驱动的 ReAct 实现
- 基础模型:采用冻结的大语言模型 PaLM-540B(部分实验补充 GPT-3 验证通用性),通过少样本上下文示例(1-6 个)引导模型生成推理轨迹与行动。
- 示例设计:每个示例为人类标注的 “行动 - 推理 - 观测” 轨迹,无需特殊格式或复杂设计,仅需标注者在行动旁补充自然语言推理。
- 生成策略:
- 知识密集型推理任务(如 HotpotQA):交替生成推理轨迹与行动,形成 “推理 - 行动 - 观测” 的密集型步骤,确保每步行动均有推理引导。
- 交互式决策任务(如 ALFWorld):允许模型自主决定推理轨迹的稀疏出现时机(如仅在目标分解、异常处理时生成推理),避免冗余推理增加计算成本。
4. ReAct 核心优势
|
优势类别
|
具体描述
|
|
设计简洁性
|
人类标注仅需在行动旁补充自然语言推理,无需特殊格式或示例筛选,易于落地
|
|
任务通用性
|
灵活的推理空间与 “推理 - 行动” 出现格式,适用于问答、事实验证、文本游戏、网页导航等多类任务
|
|
性能鲁棒性
|
少样本(1-6 个示例)设置下可泛化到新任务实例,且对示例选择的敏感度低
|
|
人机对齐性
|
推理轨迹可追溯,人类能区分模型内部知识与外部环境信息,便于验证决策依据,且可通过编辑推理轨迹实时修正模型行为
|
3.1 知识密集型推理任务:实验设计(Setup)
1. 任务选择
聚焦需外部知识检索与多步推理的两大任务:
- HotPotQA:多跳问答基准,需整合至少 2 个维基百科段落的信息回答问题(如 “科罗拉多造山运动东段延伸区域的海拔范围是多少”),实验中模型仅接收问题,需自主检索外部知识。
- FEVER:事实验证基准,需判断主张(Claim)是否有维基百科段落支持(SUPPORTS)、反驳(REFUTES)或信息不足(NOT ENOUGH INFO),模型需自主检索验证依据。
2. 行动空间:维基百科 API 设计
为模拟人类使用维基百科的方式,设计 3 类简单 API 行动,强制模型通过推理明确检索目标:
|
行动类型
|
功能描述
|
|
search[entity]
|
检索指定实体的维基百科页面,返回前 5 个句子;若实体不存在,返回 Top-5 相似实体建议
|
|
lookup[string]
|
模拟浏览器 “Ctrl+F” 功能,返回页面中包含指定字符串的下一个句子
|
|
finish[answer]
|
提交任务答案,结束当前任务
|
3.2 知识密集型推理任务:方法(Methods)
1. ReAct 提示设计(Prompting)
- 示例数量:HotPotQA 随机选择 6 个训练集案例,FEVER 选择 3 个训练集案例,手动标注为 “推理 - 行动 - 观测” 轨迹。
- 推理轨迹功能:涵盖目标分解(“我需要先搜索 X,再查找 Y”)、观测信息提取(“这段未提及 X”)、常识 / 算术推理(“1844<1989,故 A 更早”)、检索重定向(“应搜索 X 而非 Y”)、答案合成(“综上,答案为 X”)等场景。
2. 基线方法(Baselines)
通过裁剪 ReAct 轨迹构建 4 类基线,孤立推理或行动能力,以验证协同价值:
|
基线方法
|
设计逻辑
|
对应缺陷
|
|
Standard(标准提示)
|
移除 ReAct 轨迹中的推理、行动、观测,仅保留问题与答案
|
无推理引导,无外部知识检索
|
|
CoT(链式思维)
|
移除行动与观测,仅保留推理轨迹与答案,为 “仅推理” 基线
|
依赖内部知识,易幻觉、误差传播
|
|
CoT-SC(自一致性 CoT)
|
对 CoT 采样 21 条轨迹(解码温度 0.7),采用多数投票结果,优化 CoT 稳定性
|
仍无外部知识支撑,幻觉问题未解决
|
|
Act(仅行动)
|
移除推理轨迹,仅保留行动与观测,为 “仅行动” 基线
|
无推理引导,检索目标模糊,易无效行动
|
3. 内外知识结合策略
针对 ReAct(外部知识强、推理灵活性弱)与 CoT-SC(内部推理强、事实性弱)的互补性,设计两种融合策略:
- ReAct→CoT-SC:若 ReAct 在指定步数内(HotPotQA 7 步、FEVER 5 步)未返回答案,退回到 CoT-SC 利用内部知识完成推理。
- CoT-SC→ReAct:若 CoT-SC 的 n 个样本中多数答案出现次数不足\(n/2\)(表明内部知识可信度低),退回到 ReAct 检索外部知识。
4. 微调实验(Finetuning)
- 数据构建:采用自举法(Bootstrapping),用 ReAct 生成的 3000 条正确答案轨迹(含推理、行动、观测)作为微调数据。
- 模型选择:针对较小模型 PaLM-8B/62B(避免大模型微调成本),微调目标为 “根据问题 / 主张生成完整轨迹(推理 + 行动 + 观测)”。
- 训练设置:批量大小 64;PaLM-8B 中 ReAct/Act 微调 4000 步,Standard/CoT 微调 2000 步;PaLM-62B 中 ReAct/Act 微调 4000 步,Standard/CoT 微调 1000 步(因 Standard/CoT 微调过多易过拟合)。
4.1 交互式决策任务:实验设计
1. 任务选择
聚焦需长期规划与稀疏奖励的两类语言交互任务:
- ALFWorld:文本基于的家庭环境模拟游戏,对应 ALFRED 实体任务基准,包含 6 类任务(如 “将干净的生菜放在餐桌上”)。环境含 50 + 位置,专家需 50 + 步完成,需模型利用常识(如 “台灯可能在书桌 / 书架上”)规划行动、追踪子目标。
- WebShop:真实网页购物环境,含 118 万真实商品与 1.2 万人类指令(如 “找一个 3 盎司、柑橘味、敏感肌可用、价格低于 140 美元的除臭剂”),需模型通过搜索、选择商品 / 选项、购买等行动完成任务,环境文本(商品标题、描述)噪声大。
2. ReAct 提示设计
- ALFWorld:为 6 类任务各标注 3 条训练集轨迹,推理轨迹稀疏出现,功能包括目标分解(“需找到生菜→清洗→放置到餐桌”)、子目标追踪(“已找到生菜,下一步清洗”)、常识推理(“生菜可能在冰箱 / 餐桌”)。为验证鲁棒性,通过排列组合 2 条标注轨迹构建 6 种提示,与仅移除推理的 Act 基线对比。
- WebShop:设计 1-shot 提示,Act 提示仅含行动(搜索、选商品、选选项、购买),ReAct 提示额外补充推理(如 “该商品符合柑橘味、敏感肌需求,可点击查看”),对比模仿学习(IL)、模仿 + 强化学习(IL+RL)基线。
3. 基线方法
|
任务
|
基线方法
|
训练数据 / 设计
|
|
ALFWorld
|
BUTLER
|
模仿学习模型,每类任务训练 10 万条专家轨迹
|
|
WebShop
|
IL
|
1012 条人类标注轨迹训练
|
|
WebShop
|
IL+RL
|
在 IL 基础上,额外用 10587 条训练指令强化学习
|
4. ablation 实验:ReAct vs. Inner Monologue(IM)
为验证 ReAct 推理轨迹的灵活性价值,设计 IM 风格的消融组(ReAct-IM):
- IM 推理限制:仅允许推理轨迹包含 “当前目标分解”“待完成子目标”,禁止 “子目标完成判断”“常识推理(如物品位置)”。
- 对比逻辑:通过 ReAct 与 ReAct-IM 的性能差异,验证灵活推理(而非仅外部反馈响应)对决策的重要性。
四、Experiment 实验部分详细笔记
1. 知识密集型推理任务:实验结果与分析
1.1 主要实验结果(PaLM-540B 提示设置)
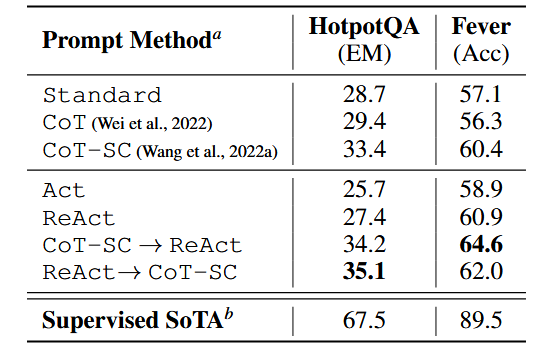
1.2 关键结论
- ReAct 优于仅行动基线:ReAct 在 HotPotQA(27.4 vs 25.7)和 FEVER(60.9 vs 58.9)均优于 Act,证明推理能引导行动聚焦关键目标(如正确合成答案、精准检索验证依据)。
- ReAct 与 CoT 的互补性:
- FEVER 中 ReAct(60.9)优于 CoT(56.3):因事实验证对信息准确性敏感,ReAct 检索的外部知识能修正内部知识偏差。
- HotPotQA 中 ReAct(27.4)略逊于 CoT(29.4):因多跳推理需灵活的推理结构,ReAct 的 “推理 - 行动” 步骤约束降低了推理灵活性,导致部分推理误差。
- 融合策略最优:CoT-SC→ReAct 和 ReAct→CoT-SC 分别在 FEVER(64.6)和 HotPotQA(35.1)达到最佳性能,且仅需 3-5 个 CoT-SC 样本即可接近 21 个样本的 CoT-SC 性能,证明内外知识结合能高效提升推理可靠性。
1.3 错误模式分析(HotPotQA 随机抽样 200 条轨迹)
|
错误类型
|
定义
|
ReAct 占比
|
CoT 占比
|
关键发现
|
|
成功 - 真阳性
|
推理轨迹与事实均正确
|
94%
|
86%
|
ReAct 因外部知识支撑,事实准确性更高
|
|
成功 - 假阳性
|
推理或事实存在幻觉
|
6%
|
14%
|
CoT 幻觉问题更严重
|
|
失败 - 推理误差
|
推理轨迹错误(如重复步骤)
|
47%
|
16%
|
ReAct 受 “推理 - 行动” 步骤约束,灵活性不足
|
|
失败 - 检索误差
|
检索结果为空或无有用信息
|
23%
|
-
|
ReAct 依赖外部检索,检索质量影响性能
|
|
失败 - 幻觉
|
推理或事实幻觉
|
0%
|
56%
|
CoT 无外部知识修正,幻觉是主要失败原因
|
|
失败 - 标签模糊
|
预测正确但与标签表述偏差
|
29%
|
28%
|
两类方法均受标签表述影响,差异小
|
1.4 微调实验结果(HotPotQA)
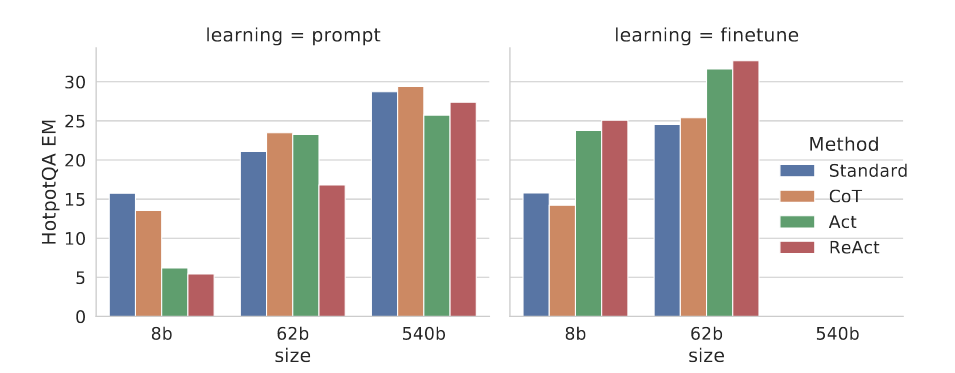
- 规模效应:提示设置下,模型规模越大(8B→62B→540B),ReAct 性能越差(因少样本难以学习 “推理 - 行动” 协同);但微调后,ReAct 性能反超其他方法:
- PaLM-8B 微调 ReAct 优于所有 PaLM-62B 提示方法;
- PaLM-62B 微调 ReAct 优于所有 PaLM-540B 提示方法。
- 原因:Standard/CoT 微调本质是让模型记忆(可能幻觉的)知识,而 ReAct/Act 微调是学习 “通过推理与行动获取外部知识” 的通用技能,泛化性更强。
2. 交互式决策任务:实验结果与分析
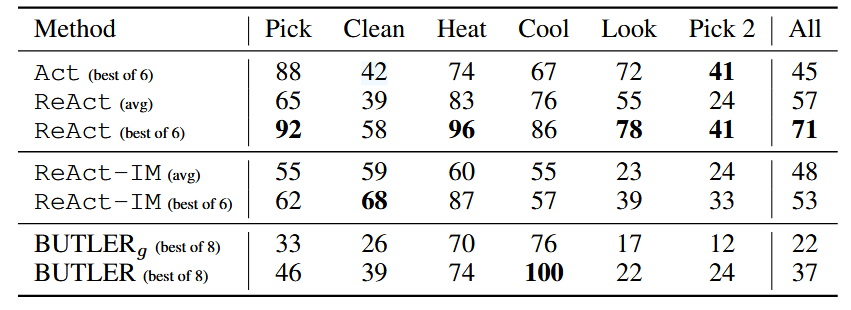
2.1 ALFWorld 实验结果(任务特定成功率,%)
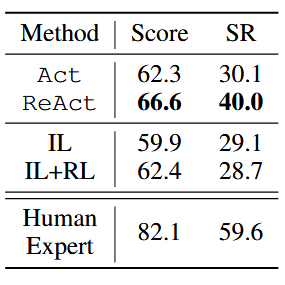
2.2 WebShop 实验结果(Score:属性覆盖率;SR:成功率)
2.3 关键结论
- ReAct 显著优于基线:
- ALFWorld 中,ReAct 最佳组(71%)远超 Act 最佳组(45%)和 BUTLER 最佳组(37%),即使 ReAct 最差组(48%)也优于基线;
- WebShop 中,ReAct 成功率(40.0%)比 IL/IL+RL 高约 10%,证明推理能帮助模型在噪声环境中识别关键属性(如 “敏感肌可用”“价格低于 140 美元”)。
- 灵活推理的价值:ReAct 优于 ReAct-IM(71% vs 53%),因 ReAct-IM 缺乏 “子目标完成判断” 和 “常识推理”,导致无法正确规划下一步行动(如不知道何时切换子目标、找不到物品位置)。
- 与人类的差距:WebShop 中 ReAct 仍远低于人类专家(40.0% vs 59.6%),因人类能更灵活地探索商品、调整搜索关键词,而现有提示方法难以实现复杂的动态调整。
3. 论文核心观点与贡献
1. 核心观点
- “推理 - 行动” 协同是突破 LLMs 局限的关键:推理能引导行动聚焦目标、处理异常,行动能为推理提供外部知识支撑,两者协同可同时解决 “幻觉”“无效行动” 等问题,提升性能与可解释性。
- 少样本提示与微调结合可释放 ReAct 潜力:少样本提示适用于快速落地,微调(尤其是用高质量 “推理 - 行动” 轨迹)能让小模型超越大模型提示性能,且泛化性更强。
- 内外知识融合是优化推理的有效路径:ReAct(外部知识)与 CoT-SC(内部推理)的融合策略,能兼顾事实准确性与推理灵活性,高效提升任务性能。
2. 核心贡献
- 提出 ReAct 范式:首个通过提示让语言模型交替生成推理轨迹与行动的通用范式,实现 “推理 - 行动” 协同,适用于多类任务。
- 多领域实验验证:在 4 类基准任务(HotPotQA、FEVER、ALFWorld、WebShop)中验证 ReAct 优于仅推理或仅行动的基线,尤其在少样本设置下(1-2 个示例)性能显著。
- 系统性分析:深入分析推理对行动、行动对推理的价值,明确 ReAct 的优势(事实性、可解释性)与局限(推理灵活性、检索依赖),并提出融合策略优化性能。
- 微调潜力探索:初步验证微调 ReAct 能让小模型超越大模型提示性能,为低成本落地提供方向,同时指出多任务训练、结合强化学习等未来优化路径。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号