KG-CRAFT 基于知识图谱和大型语言模型的对比推理以增强自动事实核查
KG-CRAFT
一、基础信息
|
类别
|
详情
|
|
标题
|
KG-CRAFT: Knowledge Graph-based Contrastive Reasoning with LLMs for Enhancing Automated Fact-checking
基于知识图谱和大型语言模型的对比推理以增强自动事实核查
|
|
作者
|
Vítor N. Lourenço、Aline Paes、Tillman Weyde、Audrey Depeige、Mohnish Dubey
|
|
来源
|
EACL 2026
|
|
发布时间
|
2026 年 1 月 27 日
|
二、研究背景与问题
(一)研究动机(现有不足)
- 信息环境挑战:数字转型改变了社会信息消费与分享方式,社交媒体导致新闻生态碎片化,同时加速了错误信息传播,在选举、公共卫生等高危领域易引发严重社会危害,对高效、可扩展的事实核查方法需求迫切。
- 早期自动事实核查(AFC)局限:早期 AFC 依赖分类和证据检索流水线,虽融入关系结构、知识库及分层架构提升了性能,但缺乏大型语言模型(LLMs)的可扩展性和适应性。
- LLM-based 方法缺陷:近年基于 LLM 的 AFC 方法通过整合外部知识和引入检索机制取得进展,但常缺乏结构化推理机制,导致核查过程不可靠;对比推理虽能提升模型可解释性和决策能力,但其在事实核查中的应用尚未充分探索。
- 无结构文本生成对比的难题:仅从无结构文本生成有意义对比存在挑战,若无事实及关系的结构化表示,对比问题可能聚焦表面语言差异,而非语义层面重要区别,导致对比信息无效或随意。
(二)研究问题
- 在有界语境下(每个声明附带预先定义的相关报告集合),如何将知识图谱与对比推理结合,提升 LLM 在自动事实核查中声明验证的准确性。
- 知识图谱驱动的对比问题相较于纯 LLM 生成的对比问题,对事实核查性能的提升效果如何。
- 对比问题数量(K)对 KG-CRAFT 在声明验证中的性能有何影响。
- KG-CRAFT 能否有效提升小型语言模型(SLMs)在事实核查中的性能,缩小其与大型 LLM 的性能差距。
三、Methods
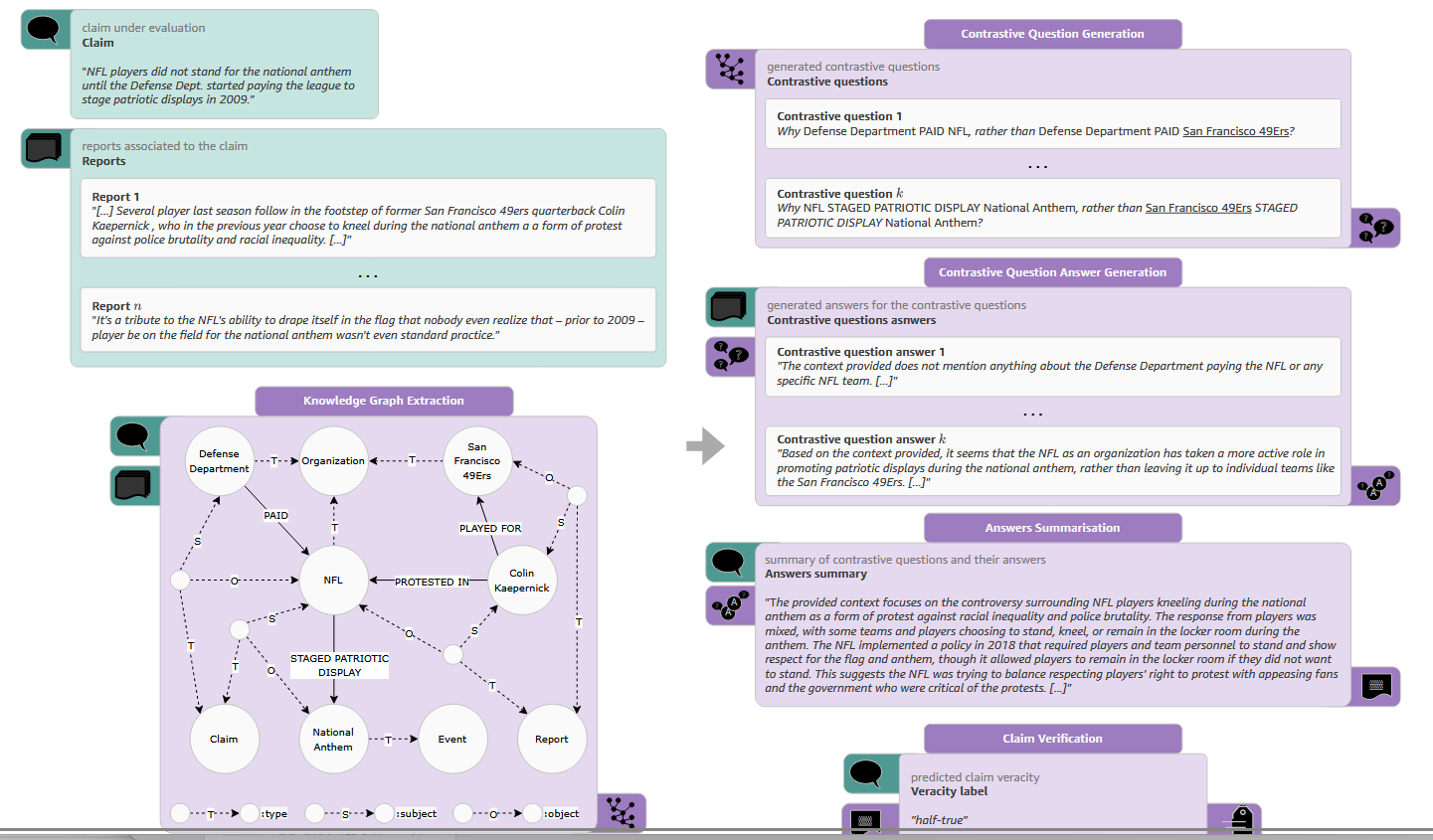
3.1 Knowledge Graph Extraction(知识图谱提取)
核心目标
从声明(c)及其相关报告集合(\(R_{C}\))中提取实体和关系,构建输入知识图谱,为后续对比推理提供结构化事实表示。
具体流程
- 实体识别与分类:借鉴现有研究思路,利用 LLM 通过多阶段少样本提示(few-shot prompting)实现。首先识别文本中的实体(E),然后根据概念类别(\(\mathbb{C}\))对实体进行标注,赋予实体语义意义以实现消歧,例如区分 “NFL” 和 “San Francisco 49ers” 同属 “体育组织” 类别。
- 关系识别与三元组构建:进一步识别已识别实体间的关系(R),形成三元组集合(\(T \subseteq E × R × E\)),每个三元组包含头实体、关系、尾实体,如(Defense Department, PAID, NFL)。
- 知识图谱整合:将实体集合(E)、关系集合(R)、三元组集合(T)及实体类别(\(\mathbb{C}\))整合,构成输入知识图谱\(G_{C, R_{C}}=(E, R, T, \mathbb{C})\)。

3.2 Contrastive Reasoning(对比推理)
核心目标
基于构建的知识图谱生成上下文相关的对比问题,利用报告回答问题并汇总,为声明验证提供聚焦且有对比性的证据。
具体流程
- 对比问题构建(Algorithm 1)
- 输入参数:知识图谱\(G=(E, R, T, \mathbb{C})\)、声明提取的三元组\(T_{claim} \subseteq T\)、期望的最大对比问题数量 K。
- 实体类别匹配:对\(T_{claim}\)中的每个三元组(h, r, t),确定头实体 h 和尾实体 t 所属的类别\(h_{c}=\tau(h)\)、\(t_{c}=\tau(t)\)(\(\tau\)为实体到类别的映射函数)。
- 对比实体集生成:生成头实体对比集\(H_{contr}=\{h' | h' \in E, \tau(h') = h_{c}\} \setminus \{h\}\)(与头实体同类别但不同的实体)和尾实体对比集\(T_{contr}=\{t' | t' \in E, \tau(t') = t_{c}\} \setminus \{t\}\)(与尾实体同类别但不同的实体)。
- 问题生成:通过替换原三元组中的头实体或尾实体(保持关系不变)生成对比问题,遵循 “为什么 [原头实体] 而非 [替代头实体]?” 或 “为什么 [替代尾实体] 而非 [原尾实体]?” 的模式,例如 “Why Defense Department PAID NFL, rather than Defense Department PAID San Francisco 49ers?”。
- 问题排序(MMR 策略):计算所有生成问题的嵌入向量\(Q_{Em}\),构建相似度矩阵;选择与其他问题平均相似度最高的嵌入作为初始查询向量\(q_{\theta}\);通过最大化\(Sim(q, q_{\theta}) - max_{q' \in Q_{ranked}} Sim(q, q')\)(\(Sim\)为余弦相似度,\(Q_{ranked}\)为已选嵌入集合)迭代选择问题,平衡相关性与多样性,最终返回前 K 个问题\(Q_{ranked}^{K}\)。
- 对比问题回答生成:采用结构化查询 - 响应提示机制(\(p_{ag}\)),让 LLM 基于声明相关报告集合(\(R_{C}\))独立回答\(Q_{ranked}^{K}\)中的每个对比问题,生成回答集合\(\tilde{A}=\{LLM_{p_{ag}}(q, R_{C}) | q \in Q_{ranked}^{K}\}\),确保回答可追溯至报告,突出支持声明真实性的关键证据。
- 回答汇总:利用提示(\(p_{as}\))引导 LLM 将声明(c)、对比问题(\(Q_{ranked}^{K}\))及对应回答(\(\tilde{A}\))聚合为简洁的基于证据的摘要\(A_{C}=LLM_{p_{as}}(C, \{(q_{i}, a_{i}) | q_{i} \in Q_{ranked}^{K}, a_{i} \in \tilde{A}\})\),保留关键对比元素和语义关联,去除非必要信息,为声明验证提供精炼信息源。



3.3 Verification of Claim Veracity(声明真实性验证)
核心目标
基于精炼的对比证据摘要,利用 LLM 准确判断声明的真实性标签。
具体流程
- 提示设计:构建提示(\(p_{cv}\)),包含原始声明(c)和生成的摘要(\(A_{C}\)),并明确可能的真实性标签及其描述,避免原始报告中的噪声干扰。
- 真实性预测:将提示输入 LLM,让其作为分类器推断声明的真实性标签,即\(V_{C}=LLM_{p_{cv}}(C, A_{C})\),确保验证基于对比推理生成的精炼证据。

四、Experiment 实验部分详细笔记
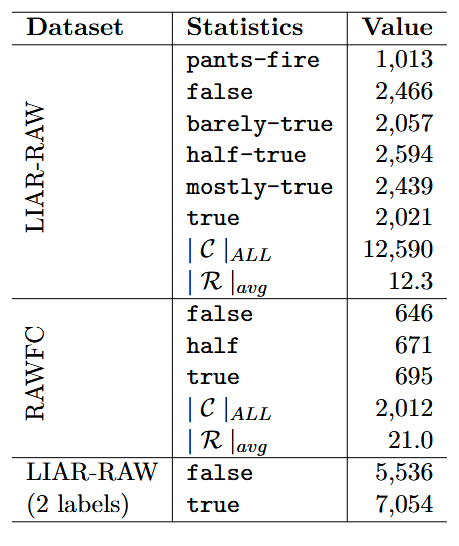
(一)数据集
|
数据集
|
来源
|
规模与结构
|
标签体系
|
用途
|
|
LIAR-RAW
|
扩展自 LIARPLUS(Alhindi et al., 2018),数据来自 Politifact
|
共 12,590 条声明,平均每条声明关联 12.3 份报告;按 8:1:1 分为训练集、测试集、验证集
|
6 类:pants-fire(彻头彻尾虚假)、false(虚假)、barely-true(勉强真实)、half-true(半真)、mostly-true(基本真实)、true(真实)
|
主要用于评估 KG-CRAFT 性能,包括消融实验(如对比问题生成方式、问题数量影响)
|
|
RAWFC
|
数据来自 Snopes
|
共 2,012 条声明,平均每条声明关联 21.0 份报告;按 8:1:1 分为训练集、测试集、验证集
|
3 类:false(虚假)、half(半真)、true(真实)
|
评估 KG-CRAFT 在不同标签体系和数据来源下的性能
|
|
LIAR-RAW(2 labels)
|
对 LIAR-RAW 的修改版本
|
保持原始数据分割和报告关联,仅调整标签
|
2 类:将 {pants-fire, false, barely-true} 归为 false(虚假),{half-true, mostly-true, true} 归为 true(真实)
|
用于分析对比问题数量(K)对 KG-CRAFT 性能的影响
|
|
SciFact
|
数据来自研究论文摘要(Wadden et al., 2020)
|
使用验证集,仅保留有完整支持或反驳证据的声明
|
2 类:supports(支持)、refutes(反驳)
|
评估 KG-CRAFT 在科学声明核查场景的泛化能力
|
|
PubHealth
|
涵盖健康相关和公共政策声明(Kotonya and Toni, 2020)
|
使用测试集,仅选择包含数据集支持上下文的声明
|
3 类:true(真实)、false(虚假)、mixture(混合)
|
评估 KG-CRAFT 在健康与政
策领域声明核查的泛化能力
|
(二)Baselines
将对比方法分为三类,具体如下:
|
类别
|
方法
|
特点
|
|
Traditional(传统方法)
|
dEFEND(Shu et al., 2019)
SBERT-FC(Kotonya and Toni, 2020)
GenFE/GenFE-MT(Atanasova et al., 2020)
CofCED(Yang et al., 2022)
EExpFND(Wang et al., 2025)
|
不使用 LLM,依赖文本嵌入和监督分类器;部分引入注意力机制、多任务优化或分层编码器
|
|
Naïve LLM(朴素 LLM 方法)
|
Llama 2 7B(Wang et al., 2024a)
ChatGPT 3.5 Turbo(Wang et al., 2024a)
Claude 3.5 Sonnet
Claude 3.7 Sonnet
Llama 3.3 70B
|
直接应用 LLM,无专门提示或推理策略,仅输入声明和相关报告进行验证
|
|
Specialised LLM(专用 LLM 方法)
|
FactLLAMA/FactLLAMA\(_{know}\)(Cheung and Lam, 2023)
L-Defense\(_{LLAMA2}\)/L-Defense\(_{ChatGPT}\)(Wang et al., 2024a)
DelphiAgent\(_{gpt-4o-mini}\)/DelphiAgent\(_{gpt-4o}\)(Xiong et al., 2025)
|
对 LLM 进行显著适配,如低秩适应(LoRA)微调、整合外部知识、引入防御式框架或多智能体验证机制
|
(三)实验内容、结果与结论
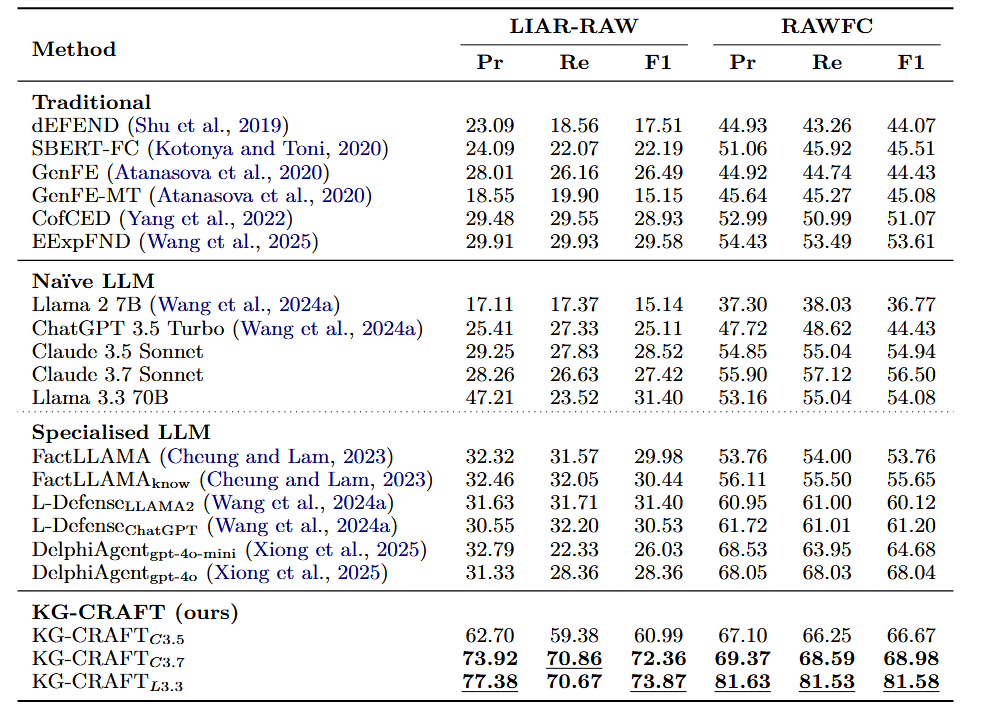
1. 声明验证性能评估(RQ1)
- 实验内容:在 LIAR-RAW 和 RAWFC 数据集上,对比 KG-CRAFT(基于 Claude 3.5 Sonnet、Claude 3.7 Sonnet、Llama 3.3 70B)与各类 Baselines 的性能,采用精确率(Pr)、召回率(Re)、F1 分数作为评估指标。
- 实验结果:
- 在 LIAR-RAW 数据集上,KG-CRAFT\(_{L3.3}\)表现最佳,F1 分数达 73.87%,较次优方法 L-Defense(Wang et al., 2024a)提升 44 个百分点;相较于其朴素 LLM 版本(Llama 3.3 70B,F1=31.40%),提升 42 个百分点。
- 在 RAWFC 数据集上,KG-CRAFT\(_{L3.3}\)的 F1 分数为 81.58%,较次优方法 DelphiAgent\(_{gpt-4o}\)(Xiong et al., 2025,F1=68.04%)提升 13 个百分点;相较于其朴素 LLM 版本(Llama 3.3 70B,F1=54.08%),提升 27 个百分点。
- KG-CRAFT\(_{C3.7}\)在两个数据集上也表现优异,LIAR-RAW 的 F1=72.36%,RAWFC 的 F1=68.98%;KG-CRAFT\(_{C3.5}\)仅在 RAWFC 上略逊于 DelphiAgent\(_{gpt-4o}\),其余场景均优于所有 Baselines。
- 结论:KG-CRAFT 在两个真实世界数据集上均实现了最先进的预测性能,显著优于传统方法、朴素 LLM 方法和专用 LLM 方法,证明知识图谱驱动的对比推理能有效提升 LLM 的事实核查能力。
2. 知识图谱 vs LLM 生成对比问题(RQ2)
- 实验内容:在 LIAR-RAW 数据集上,将 KG-CRAFT 的 “知识图谱生成对比问题” 替换为 “LLM 少样本提示生成对比问题”(K=5),对比两种方式的事实核查 F1 分数、宏观 / 加权 AlignScore(信息对齐度)和宏观 / 加权 RQUGE(问题可接受度)。

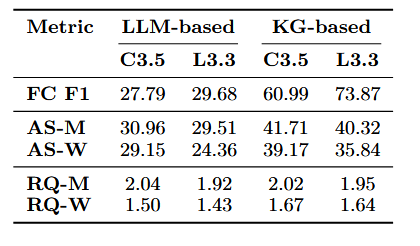
- 实验结果:
- 事实核查 F1 分数:KG-based 方法显著更高,如 Claude 3.5 Sonnet 的 KG-based F1=60.99%,LLM-based F1=27.79%;Llama 3.3 70B 的 KG-based F1=73.87%,LLM-based F1=29.68%。
- AlignScore(信息对齐):KG-based 方法的宏观和加权分数均高于 LLM-based,如 Claude 3.5 Sonnet 的 KG-based 宏观 AlignScore=41.71%,LLM-based=30.96%。
- RQUGE(问题质量):KG-based 方法的宏观和加权分数略高于 LLM-based,如 Llama 3.3 70B 的 KG-based 加权 RQUGE=1.64,LLM-based=1.43。
- 结论:基于知识图谱生成的对比问题能提升回答摘要与声明的信息对齐度及问题本身的可接受度,进而提升事实核查性能;纯 LLM 生成的对比问题易聚焦非关键差异,导致核查效果不佳。
3. 对比问题数量(K)的影响(RQ3)
- 实验内容:在 LIAR-RAW(2 labels)数据集上,使用 KG-CRAFT\(_{C3.5}\),设置 K∈{1,3,5,7,10},分析不同 K 值对精确率、召回率、F1 分数的影响,以 K=5 为基准对比相对性能。
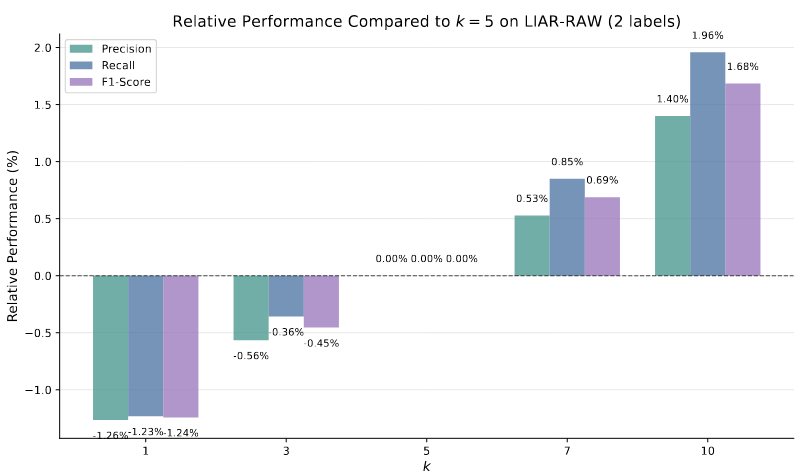
- 实验结果:
- 随着 K 增加,性能整体提升但增益逐渐减小:K=1 时性能最差,较 K=5 下降约 1.2 个百分点;K=10 时性能最佳,较 K=5 提升约 1.6 个百分点。
- 所有 K 值下性能差异在 ±2 个百分点内,KG-CRAFT 在不同 K 值下均保持稳健性能。
- 结论:对比问题数量增加有助于提升性能,但边际效益递减;K=5 是性能与计算效率的有效平衡点。
4. KG-CRAFT 与小型语言模型(SLMs)(RQ4)
- 实验内容:评估 4 个 SLMs(SmolLM2 135M、Qwen3 0.6B、SmolLM2 1.7B、Qwen3 1.7B)结合 KG-CRAFT 后的 F1 性能,对比朴素 Claude 3.7 Sonnet(大型 LLM)和 KG-CRAFT\(_{C3.7}\)。
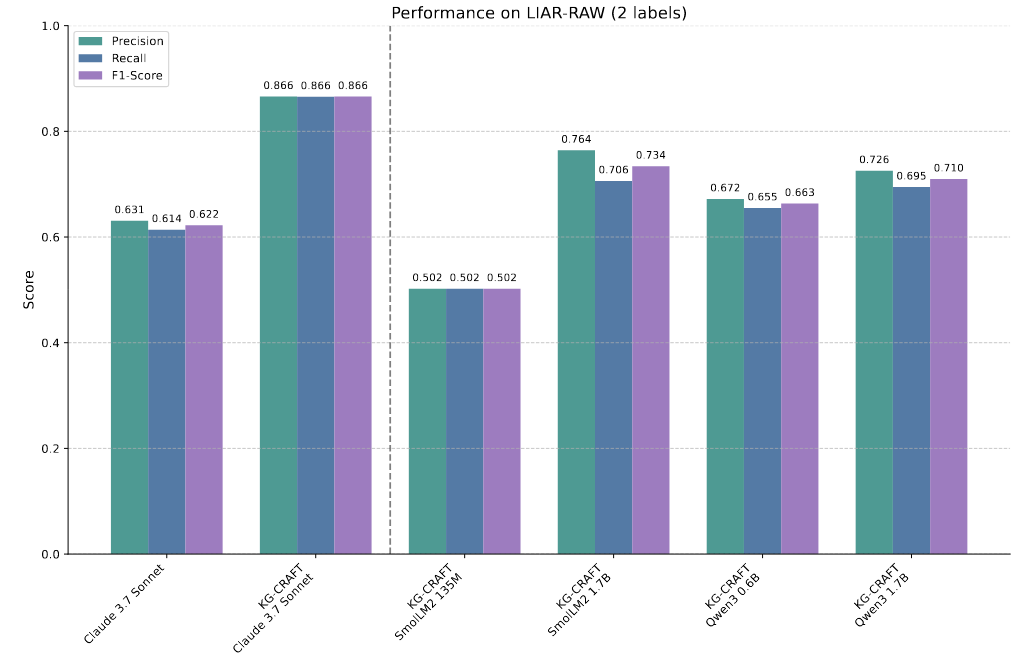
- 实验结果:
- SmolLM2 1.7B 结合 KG-CRAFT 后 F1 分数达 73.40%,显著优于朴素 Claude 3.7 Sonnet(62.22%)。
- 较小的 Qwen3 0.6B 结合 KG-CRAFT 后 F1=66.34%,同样超过朴素 Claude 3.7 Sonnet,尽管其参数规模远小于后者。
- 所有 SLMs 结合 KG-CRAFT 后性能均大幅提升,缩小了与大型 LLM 的性能差距。
- 结论:KG-CRAFT 能有效弥补 SLMs 的性能缺陷,通过提供相关验证线索,使小型模型在事实核查任务上具备与大型 LLM 竞争的能力,降低了事实核查对高计算资源模型的依赖。
5. 跨数据集泛化性评估
- 实验内容:在 SciFact(科学摘要)和 PubHealth(健康 / 政策声明)数据集上,对比 KG-CRAFT 与其他专用方法(如 MULTIVERS、ProgramFC、GraphFC 等)的性能,评估泛化能力。
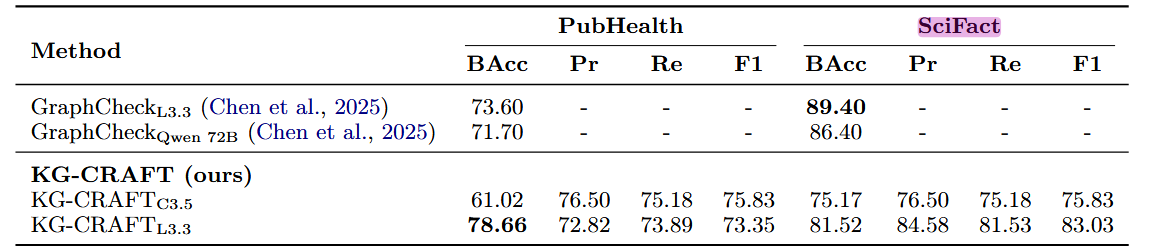
- 实验结果:
- SciFact 数据集:KG-CRAFT\(_{L3.3}\)的 F1=83.03%,优于除 GraphFC(87.37%)外的所有方法,较 MULTIVERS(72.50%)提升超 10 个百分点;平衡准确率(BAcc)为 81.52%,略低于 GraphCheck\(_{L3.3}\)(89.40%)。
- PubHealth 数据集:KG-CRAFT\(_{L3.3}\)的 BAcc=78.66%,超过 GraphCheck\(_{L3.3}\)(73.60%)和 GraphCheck\(_{Qwen 72B}\)(71.70%),F1=73.35%,表现稳健。
- 结论:KG-CRAFT 在科学、健康、政策等不同领域的声明核查任务中均表现出良好的泛化能力,尽管在 SciFact 上与 GraphFC 存在小幅差距(可能因该数据集报告较短导致知识图谱多样性不足),但整体跨领域适应性强。
6. 组件消融实验
- 实验内容:在 LIAR-RAW 和 RAWFC 数据集上,对比 KG-CRAFT 完整框架与三个变体的性能:朴素 LLM(仅声明 + 报告)、LLM+KG(无对比推理)、LLM+LLM 生成对比问题(无 KG)。
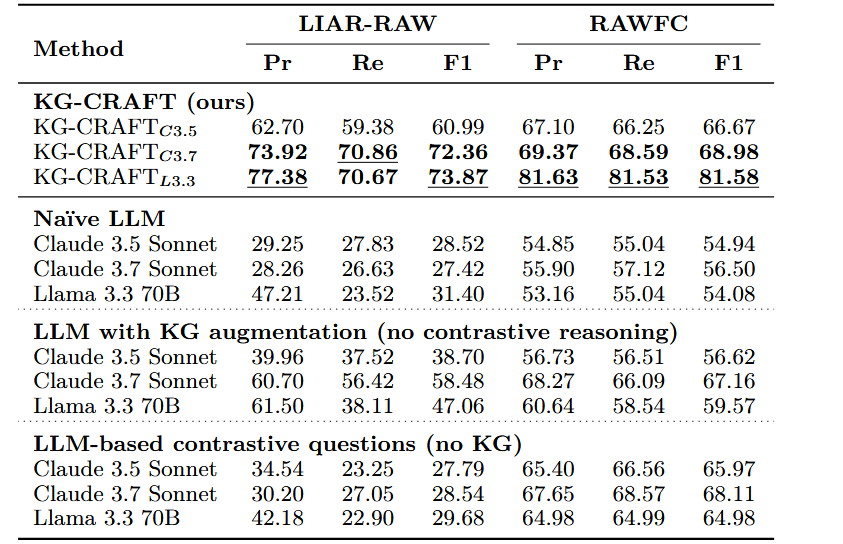
- 实验结果:
- 朴素 LLM 性能最差,如 Llama 3.3 70B 在 LIAR-RAW 的 F1=31.40%。
- LLM+KG 变体性能较朴素 LLM 提升但有限,如 Llama 3.3 70B 的 F1=47.06%,仅提升 15.66 个百分点。
- LLM+LLM 生成对比问题变体性能仍较低,如 Llama 3.3 70B 的 F1=29.68%,低于 LLM+KG。
- KG-CRAFT 完整框架性能最优,如 Llama 3.3 70B 的 F1=73.87%,较朴素 LLM 提升 42.47 个百分点。
- 结论:KG-CRAFT 的性能提升源于知识图谱与对比推理的协同作用,其中对比推理是核心驱动因素;单独引入 KG 或纯 LLM 生成对比问题均无法实现同等性能提升,验证了框架各组件的必要性。
(四)论文核心观点 / 贡献
- 方法创新:提出一种基于知识图谱的对比推理方法(KG-CRAFT),将知识图谱的结构化表示与 LLM 的语言理解能力结合,通过生成上下文相关的对比问题引导证据提炼,填补了对比推理在事实核查领域应用的空白。
- 性能突破:在 LIAR-RAW、RAWFC 等多个真实世界数据集上实现最先进性能,显著超越传统方法和现有 LLM-based 方法,证明了结构化对比推理对事实核查的有效性。
- 资源效率:通过增强小型语言模型(SLMs)的性能,降低了事实核查对大型、高计算成本模型的依赖,为资源受限场景提供了可行解决方案。
- 泛化能力:在科学、健康、政策等跨领域任务中表现稳健,验证了方法的广泛适用性,为不同领域的自动事实核查提供了通用框架。
- 组件验证:通过全面消融实验,明确了知识图谱、对比问题生成、回答汇总等组件的作用,为后续事实核查方法的设计提供了理论与实践参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号