LLM-based Few-Shot Early Rumor Detection with Imitation Agent
论文信息
论文标题:LLM-based Few-Shot Early Rumor Detection with Imitation Agent
论文翻译:基于大语言模型与模仿智能体的少样本早期谣言检测
论文作者:Fengzhu Zeng、Qian Shao、Ling Cheng、Wei Gao、Shih-Fen Cheng、Jing Ma、Cheng Niu
论文来源:KDD 2026
发布时间:2025 年 12 月 20 日
论文地址:
论文代码:
二、研究背景与问题
1. 研究动机(现有不足)
- 谣言传播的危害:虚假谣言传播会引发严重社会后果,例如 2024 年 7 月英国绍斯波特持刀袭击事件后,社交媒体上虚假谣言指控袭击者为穆斯林移民,引发英国历史上最严重的暴力骚乱之一,凸显早期谣言检测(EARD)的迫切需求。
- 现有 EARD 方法的局限:
- 依赖循环神经网络(RNN)作为谣言检测模块,早期时间点预测模块常用深度强化学习、固定概率阈值或神经霍克斯过程,两模块紧密耦合联合训练,需大量标注数据,且难以替换为更优模块。
- 社交媒体新事件不断涌现,新事件标注数据稀缺,早期传播阶段相关帖子少,标注成本高;等待大量帖子积累再决策会导致谣言进一步扩散,现有方法难以应对数据有限场景。
- 大语言模型(LLM)应用于 EARD 的不足:LLM 在少样本 NLP 任务中表现出色,但不适合处理时序数据,难以表示序列依赖关系;训练 LLM 处理时序数据需大量资源,且 EARD 场景下需在每个时间步生成预测,上下文长度随时间增加,推理成本高、延迟大。
2. 研究问题
在数据有限的场景下,如何高效且有效地利用 LLM 的强语言理解能力,实现少样本早期谣言检测,即在获取少量标注数据的情况下,准确且尽早地确定谣言检测的时间点,同时控制计算成本与推理延迟。
三、Methods
1. MDP Formulation for EARD(EARD 的马尔可夫决策过程建模)
- 核心定义:将 EARD 任务建模为马尔可夫决策过程(MDP),用元组\(M=(S, A, P, R)\)表示,各组件含义如下:
- 状态空间(S):每个状态\(s_t \in S\)包含截至当前时间步\(t\)的所有观测帖子以及上一个动作,即\(s_t=(m_{0:t}, a_{t-1})\),其中\(m_{0:t}\)表示 0 到\(t\)时间步的帖子集合。
- 动作空间(A):动作是二元的,包括 “继续观测”(记为 0,继续监控帖子流)和 “停止观测”(记为 1,终止观测并触发 LLM 进行谣言检测)。
- 转移函数(P):具有确定性,若当前状态为\(s_t=(m_{0:t}, a_{t-1})\)、动作为\(a_t\),则下一个状态为\(s_{t+1}=(m_{0:t+1}, a_t)\)。
- 奖励函数(R):奖励函数\(r(s, a) \in R\)反映状态 - 动作对的即时奖励,\(\bar{\gamma} \in(0,1)\)为折扣因子。
- 策略与期望回报:
- 用\(\Pi\)表示所有平稳随机策略集合,策略\(\pi \in \Pi\)根据状态从动作空间选择动作。
- 在\(\bar{\gamma}\)折扣无限时域设定下,期望回报定义为\(\mathbb{E}_{\pi}[r(s, a)] \triangleq \mathbb{E}_{\pi}[\sum_{t=0}^{\infty} \bar{\gamma}^{t} r(s_{t}, a_{t})]\),其中\(s_0 \sim p_0\)(\(p_0\)为初始状态分布),\(a_t \sim \pi(\cdot | s_t)\),\(s_{t+1} \sim P(\cdot | s_t, a_t)\)(\(t \geq0\))。
- 特殊规则:当状态包含时间线中最后一个帖子时,过程强制终止。
2. Imitation Learning(模仿学习)
2.1 选择模仿学习的原因
- 强化学习(RL)依赖明确、可观测的奖励函数引导智能体动作,但 EARD 中设计有效奖励函数极具挑战:确定早期检测时间点需考虑观测信息充分性和检测器能力,二者难以量化;手动指定的奖励函数可能稀疏或与任务目标不一致,导致智能体难以学习最优策略,甚至出现延迟预测等问题;学习奖励函数需大量标注数据和计算资源。
- 模仿学习(IL)无需显式定义奖励函数,能从少量专家轨迹中学习最优策略,在序列决策问题中应用成功,且需更少数据、收敛更快,适合 EARD 场景。
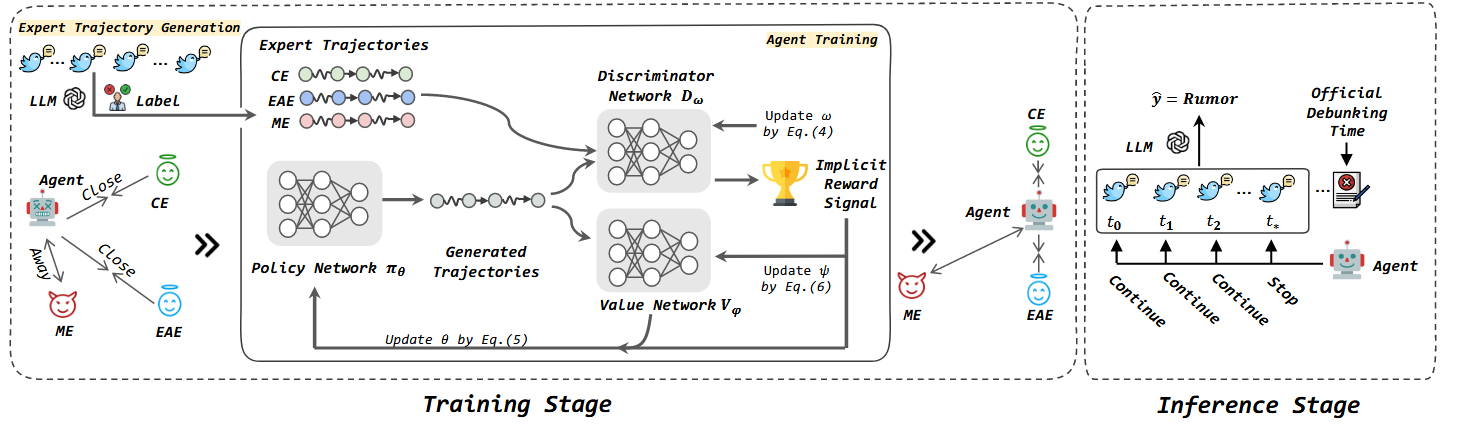
2.2 Trajectories Generation(轨迹生成)
- 核心逻辑:LLM 在观测帖子流过程中,每个时间步\(t_i\)生成预测\(\hat{y}_i\)(谣言或非谣言),观测终止后得到长度为\(|M|\)的预测序列\(\hat{y}_0, \hat{y}_1, ..., \hat{y}_{|M|}\);通过将预测序列与真实标签\(y\)对比,构建专家轨迹,确定早期检测时间点。
- 专家轨迹定义:对于序列长度为\(|M|\)的实例,专家\(E\)选择的早期时间点为\(t_{i^*}\)(\(0 \leq i^* \leq|M|\)),专家轨迹表示为\(\tau_E = \{(s_0, a_0), ..., (s_{i^*}, a_{i^*}), ..., (s_{|M|}, a_{|M|})\}\),其中\(s_j \in S\),\(a_j \in A\),且\(0 \leq j < i^*\)时\(a_j=0\),\(i^* \leq j \leq|M|\)时\(a_j=1\)。
- 三类专家设计:
- 保守专家(CE):受 Zeng 和 Gao(2022)启发,选择预测准确且后续无反转的最早时间点,即\(t_{i^*}=min\{t_k | \hat{y}_k=\hat{y}_j=y, \forall k<j \leq|M|, k \in\{0, ...,|M|\}\}\)。优点是保证预测稳定性,缺点是过于谨慎可能延迟检测,易受传播中无关帖子干扰。
- 早期行动专家(EAE):在 CE 策略基础上更主动,选择预测首次与真实标签一致的时间点,即\(t_{i^*}=min\{t_k | \hat{y}_k=y, k \in\{0, ...,|M|\}\}\)。优点是能实现最早预测,缺点是在一定程度上牺牲了预测稳定性。
- 误导专家(ME):捕捉 LLM 考虑所有帖子后仍预测错误的场景,选择首次预测错误且后续预测不变的时间点,即$t_{i^*}=min{t_k | \hat{y}_k \neq y且\hat{y}_k=\hat{y}_j, \forall k<j \leq|M|, k \in{0, ...,|M|}}$。作用是让智能体学习规避误导性行为。
2.3 Objective Function(目标函数)
- 专家轨迹与占用测度:通过轨迹生成策略得到三类专家轨迹集合\(\Phi_E = \{\tau_E \sim \pi_E\}\)(\(E=\{c, e, m\}\)分别对应 CE、EAE、ME),轨迹包含专家策略\(\pi_E\)在环境中的状态 - 动作对。
- 占用测度定义:策略\(\pi\)的占用测度\(\rho_{\pi} \in \Gamma\)(\(\Gamma\)为所有平稳随机策略的占用测度集合)定义为\(\rho_{\pi}(s, a)=\pi(a | s) \sum_{t=0}^{\infty} \bar{\gamma}^t P(s_t = s | \pi)\),
核心作用是量化策略$\pi$对各状态-动作对的访问频率,反映策略的整体行为特征,反映状态 - 动作对的分布,且策略与占用测度存在一一对应关系,优化占用测度的匹配度即可实现策略的优化。
- 目标函数设计:智能体需学习综合三类专家策略的最优策略,即最小化与 CE、EAE 占用测度的差异,最大化与 ME 占用测度的差异,目标函数为:\( \min_{\pi} -H(\pi) + \alpha \psi^*(\rho_{\pi}, \rho_{\pi_c}) + \beta \psi^*(\rho_{\pi}, \rho_{\pi_e}) - \gamma \psi^*(\rho_{\pi}, \rho_{\pi_m}) \)
其中:
- \(H(\pi) \triangleq \mathbb{E}_{\pi}[-log \pi(a | s)]\)为策略\(\pi\)的因果熵,鼓励探索,避免策略陷入确定性。
- \(\psi^*\)为詹森 - 香农散度(JSD),用于衡量占用测度间的距离,$\psi^*(ρ_π, ρ_{π_E}) = max_{D \in(0,1)^{S×A}} \mathbb{E}_π[log D(s,a)] + \mathbb{E}_{π_E}[log(1-D(s,a))]$(\(D\)为区分智能体与专家轨迹的判别器)。
- \(\alpha, \beta, \gamma, \lambda\)为参数,控制因果熵和不同专家占用测度距离的影响;实验中设\(\alpha=0.7\)(优先 CE 轨迹,保证稳定性),\(\beta=\gamma=0.15\)(EAE 和 ME 轨迹贡献均等,平衡学习过程)。
2.4 Training(训练过程)
- 网络结构:智能体包含三个神经网络:
- 策略网络\(\pi_{\theta}\)(参数\(\theta\)):输出动作选择概率。
- 判别器网络\(D_{\omega}\)(参数\(\omega\)):区分专家轨迹与智能体生成轨迹,提供隐式奖励信号。
- 价值网络\(V_{\phi}\)(参数\(\phi\)):估计状态价值函数\(V_{\phi}(s)\),稳定策略更新,计算动作优势值。
- 训练流程:
- 轨迹收集:用当前策略\(\pi_{\theta_k}\)运行\(K\)个时间步,收集智能体轨迹\(\Phi_k = \{\tau_i\}\)。
- 隐式奖励计算:通过判别器输出计算\(K\)个时间步的隐式奖励\(r_t = -log(D_{\omega}(s_t, a_t))\)。
- 价值与优势值计算:计算\(K\)个时间步的价值函数\(V_{\phi}(s_t)\),并利用广义优势估计(GAE)计算优势值\(A^{\pi_{\theta_k}}\)和回报总和\(\hat{R}_t\)
- 网络更新:
- 策略网络更新:采用近邻策略优化(PPO)-clip 方法,更新目标为\(\theta_{k+1} = \arg max_{\theta} \mathbb{E}_{s,a \sim \pi_{\theta_k}}[L(s,a,\theta_k,\theta)]\),其中\(L\)为 PPO 目标函数,\(\epsilon\)为控制新老策略偏差的超参数。
- 价值网络更新:最小化价值函数与回报总和的均方误差,更新公式为\(\phi' \leftarrow \phi - \frac{1}{K} \sum_{t=1}^K \alpha_r \nabla_{\phi}(V_{\phi}(s_t) - \hat{R}_t)^2\)(\(\alpha_r\)为价值网络学习率)。
- 判别器网络更新:用 Adam 优化器最大化目标函数,更新参数\(\omega\),梯度计算基于判别器的分类损失。
- 迭代终止:重复上述步骤直至收敛,得到最优策略\(\pi_{\theta}\)。
3. Inference(推理过程)
- 训练完成后,将训练好的策略网络\(\pi_{\theta}\)直接用于早期时间点预测,无需再生成专家轨迹。
- 推理时,智能体持续监控社交媒体帖子流,通过策略网络判断当前时间点是否停止观测;若判断停止,则激活 LLM,利用已观测帖子进行谣言检测并输出结果。
四、Experiment 实验部分详细笔记
1. 数据集(Datasets)
|
数据集名称
|
来源与内容
|
用途
|
|
PHEME
|
收集新闻事件相关对话线程中的帖子
|
用于早期谣言检测模型训练与测试,验证模型在通用事件谣言检测中的性能
|
|
TWITTER
|
从事实核查网站获取事件帖子,是谣言检测研究的常用数据集
|
用于对比不同模型在经典谣言检测场景下的表现
|
|
Twitter-COVID-19
|
收集讨论 COVID-19 疫情相关事件的对话线程帖子
|
用于测试模型在特定领域(疫情)新事件中的泛化能力
|
|
BEARD
|
专为 EARD 任务设计的数据集,重点包含事件早期阶段的帖子
|
用于验证模型在早期帖子稀缺场景下的早期检测能力
|
- 所有数据集均按时间顺序整理相关帖子,标注为 “谣言”(\(y=1\))或 “非谣言”(\(y=0\));少样本设置下,从训练集中随机采样\(K\)个实例,不设验证集以贴合真实数据有限场景。
2. 基准模型(Baselines)
- 传统 EARD 方法:
- ERD:采用深度 Q 网络(DQN),通过手动设计奖励函数引导模型关注早期时间区间。
- CED:基于预测可信度的固定概率阈值,判断是否终止检测过程。
- HEARD:利用神经霍克斯过程构建检测稳定性分布,确定未来预测不变的检测时间点。
- LLM 基准模型(采用两种早期检测策略):
- 最早谣言检测策略:仅使用每个实例的第一条帖子,让 LLM(Mistral、Llama 3、ChatGPT)进行预测,验证 LLM 在极少数据下的检测能力。
- 预设时间 checkpoint 策略:设置 {1h, 6h, 12h, 24h, 36h} 为时间 checkpoint,将每个 checkpoint 前的所有帖子输入 LLM 进行预测,对比模型在不同时间节点的检测性能。
3. 实验设置(Experimental Settings)
- 数据采样:随机采样 50 个带标签训练实例用于生成专家轨迹,100 个无标签实例作为智能体探索环境,模拟在线策略学习场景。
- 特征与网络参数:用预训练 BERTweet 模型获取状态嵌入;策略、价值、判别器网络均采用两个隐藏层(大小 64),激活函数为 Tanh;因果熵系数\(\lambda=0.01\),GAE 参数\(\bar{\gamma}=0.99\)、\(\lambda_0=0.97\),价值网络学习率\(3Ã10^{-4}\),PPO-clip 参数\(\epsilon=0.1\)。
- LLM 配置:使用 7B 参数的 Mistral(Mistral-Instruct-v0.3)、8B 参数的 Llama 3(Llama-3-Instruct)开源模型,以及 OpenAI 的 ChatGPT API(GPT-4o-mini);所有模型使用相同提示模板:“Analyze the given sequence of social media posts, determine if it is a rumor. Respond Yes or No only. Posts: [the list of observed posts in chronological order]”。
- 评估指标:
- 分类性能:宏 F1 分数(macro-F1),衡量谣言与非谣言分类的综合准确性。
- 早期性:早期率(ER),定义为\(ER = \frac{1}{|C_{test}|} \sum_{C \in C} \frac{i_C}{|C|}\)(\(C_{test}\)为测试集,\(i_C\)为实例\(C\)的检测决策对应的帖子序号,\(|C|\)为实例\(C\)的总帖子数),ER 值越低表示检测越早。
- 实验重复与统计:每个实验用不同随机种子重复 5 次,报告均值与标准差,保证结果可靠性。
4. 实验内容及其对应的实验结果、结论
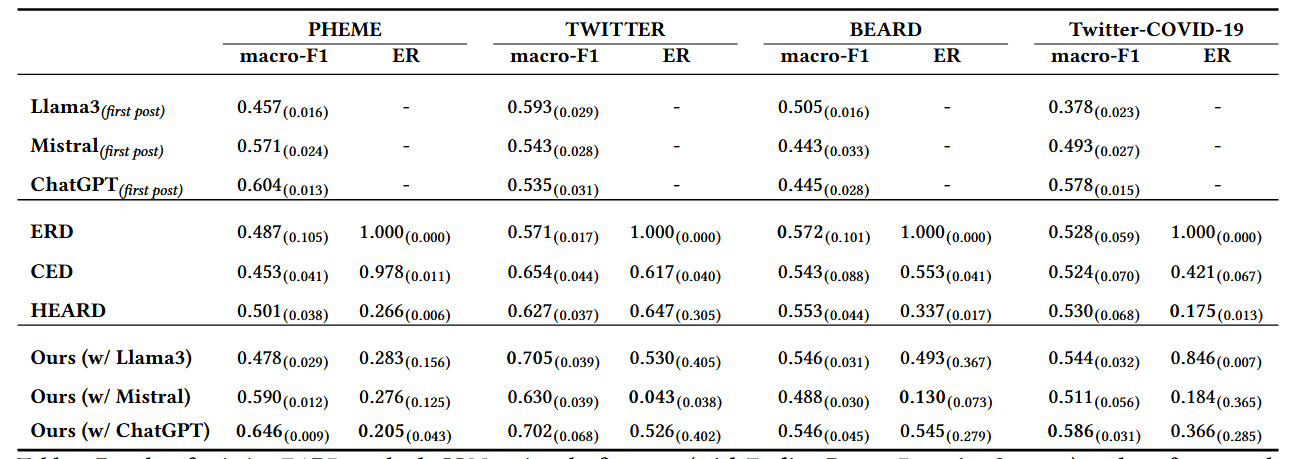
4.1 主要结果对比(Main Results)
- 实验内容:对比现有 EARD 方法、采用最早谣言检测策略的 LLM,以及集成所提框架的 LLM 在四个数据集上的 macro-F1 和 ER。
- 实验结果:
- 仅用第一条帖子的 LLM 表现优于多数传统 EARD 方法:ChatGPT 在 PHEME 和 Twitter-COVID-19 上分别比现有 EARD 方法高出 33.3% 和 10.3%;Mistral 在 PHEME 上超越所有传统 EARD 方法,Llama 3 在 TWITTER 上优于 ERD。
- 所提框架显著提升 LLM 性能:在四个数据集上,集成框架后 Mistral 的 macro-F1 平均提升 8.2%,ChatGPT 提升 15.6%,Llama 3 提升 18.9%;例如在 TWITTER 数据集上,集成框架的 Mistral 不仅 macro-F1 超越所有 EARD 基准,且 ER(0.043)远低于 ERD(1.000)、CED(0.617)和 HEARD(0.647)。
- 传统 EARD 方法在少样本场景表现不佳:ERD 因依赖手动奖励函数,在少样本下策略不稳定,ER 始终为 1.000(无法早期检测);HEARD 虽能早期检测,但 macro-F1 低于集成框架的 LLM。
- 结论:LLM 具备强少样本谣言检测能力,所提框架通过智能体的早期时间点决策,进一步释放 LLM 潜力,在准确性和早期性上均优于传统 EARD 方法,且具有模型无关性(适配不同 LLM)。
4.2 跨数据集泛化性实验(Cross-dataset Evaluation)
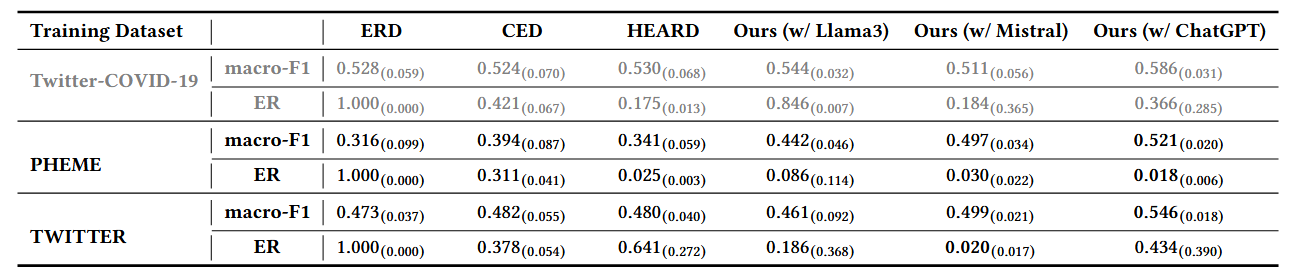
- 实验内容:用 PHEME 和 TWITTER(均早于 COVID-19)训练模型,在 Twitter-COVID-19(疫情相关新事件)上测试,验证模型对未见过事件的泛化能力。
- 实验结果:
- 所有模型在跨数据集测试中性能均下降,但所提框架下降幅度更小:ERD、CED、HEARD 在 PHEME 上训练后,macro-F1 相对下降 67.8%、33.1%、55.4%,而集成 Mistral 的框架仅下降 2.8%;在 TWITTER 上训练时,传统方法下降 11.6%-10.4%,框架下降 2.4%。
- 集成框架在跨数据集场景下仍优于传统 EARD 方法:例如集成 Mistral 的框架在跨数据集测试中的 macro-F1 和 ER 均优于 ERD、CED、HEARD。
- 结论:所提框架在数据有限的跨事件场景中泛化能力更强,能更好地适应未见过的新事件谣言检测任务。
4.3 与 LLM 预设时间 checkpoint 策略对比
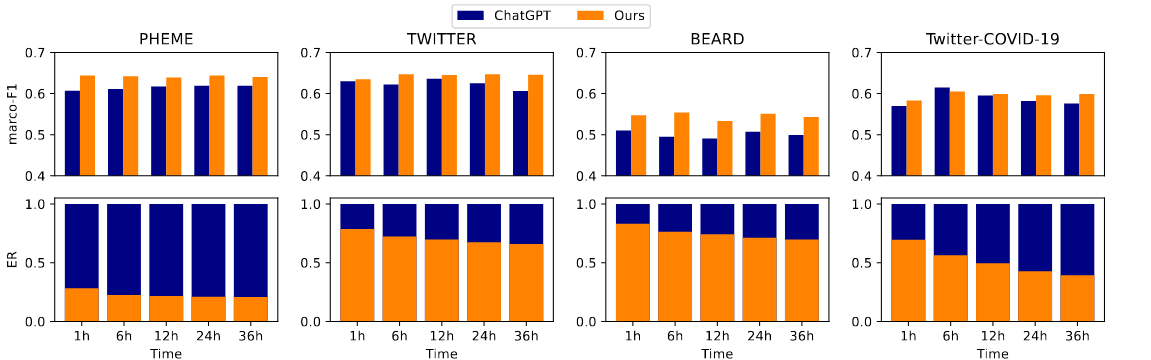
- 实验内容:以表现最优的 ChatGPT 为基础,对比其在预设时间 checkpoint 策略下与集成所提框架后的 macro-F1 和 ER(如图所示)。
- 实验结果:
- 所提框架在所有 checkpoint 和数据集上均提升 ChatGPT 性能:例如在 Twitter-COVID-19 数据集上,12h checkpoint 时,集成框架后 ChatGPT 的 ER 降低 50% 以上(低于 0.5),同时 macro-F1 更高。
- 在 EARD 专用数据集 BEARD 上,框架提升效果更显著:因 BEARD 包含更多早期帖子,框架能更有效利用早期信息,实现更早更准的检测。
- 结论:智能体的自动早期时间点决策优于预设 checkpoint 策略,能让 LLM 用更少帖子实现更优早期检测性能。
4.4 不同 LLM 的泛化性差异分析
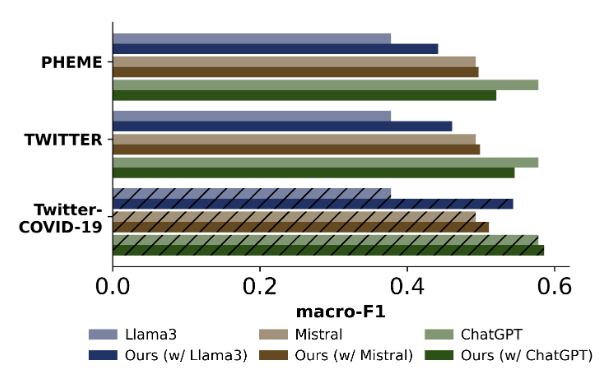
- 实验内容:分析不同基础 LLM(Llama 3、Mistral、ChatGPT)集成框架后,在跨数据集场景(PHEME/TWITTER 训练→Twitter-COVID-19 测试)中的泛化性能差异(如图所示)。
- 实验结果:
- 基础 LLM 性能越低,框架提升越显著:Llama 3 集成框架后 macro-F1 提升约 17%-18%,Mistral 提升较小,ChatGPT 甚至出现小幅下降。
- 少量新事件数据可改善性能:在 Twitter-COVID-19 上添加少量训练样本后,所有 LLM 集成框架后的性能均提升。
- 结论:框架对基础性能较弱的 LLM 提升更明显;当基础 LLM 性能较强时,需结合少量新事件数据优化智能体,未来可考虑将问题建模为部分可观测马尔可夫决策过程(POMDP)以处理不确定性。
4.5 少样本鲁棒性实验
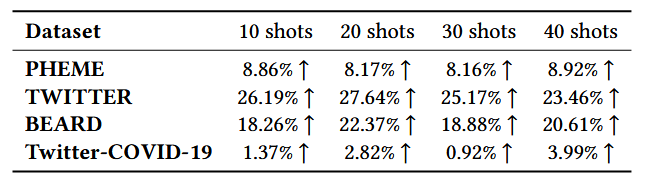
- 实验内容:减少训练样本数量(10、20、30、40 shot),以 ChatGPT 为基础 LLM,测试框架在不同样本量下的 macro-F1 提升情况(如表所示)。
- 实验结果:
- 框架在极少量样本下仍有效:10 shot 时,在 TWITTER 上 macro-F1 相对提升 26.19%,在 BEARD 上提升 18.26%;40 shot 时,在 PHEME 上提升 8.92%,在 Twitter-COVID-19 上提升 3.99%。
- 所有数据集上,框架均稳定优于基础 ChatGPT,无明显性能波动。
- 结论:所提框架在数据稀缺场景下鲁棒性强,仅需极少量标注样本即可实现有效早期谣言检测。
4.6 准确性与早期性权衡分析
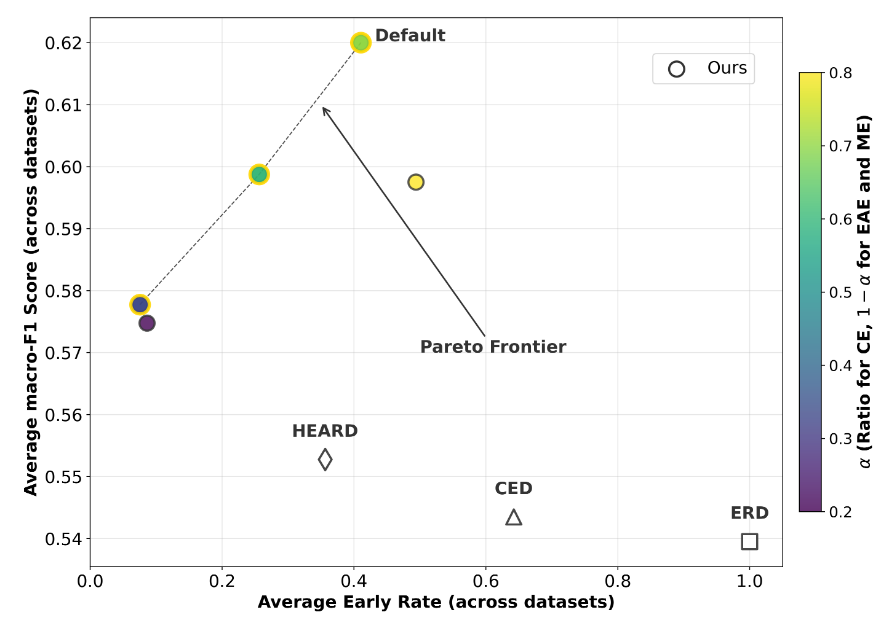
- 实验内容:调整专家轨迹比例(改变\(\alpha\),\(1-\alpha\)均分给 EAE 和 ME),分析框架在准确性(macro-F1)与早期性(ER)之间的权衡,对比传统 EARD 方法(如图 所示)。
- 实验结果:
- 框架的多个设置位于帕累托前沿(无其他设置能同时提升准确性和早期性),而传统 EARD 方法(ERD、CED、HEARD)均不在前沿上,且 macro-F1 更低、ER 更高。
- 降低 CE 比例(增加 EAE 比例)会降低 ER(更早检测),但会牺牲 macro-F1;默认设置(\(\alpha=0.7\))在帕累托前沿上实现最高 macro-F1 和有竞争力的 ER。
- 结论:通过平衡不同专家轨迹比例,框架能在准确性和早期性之间取得最优权衡,默认设置可实现稳定且准确的早期检测,避免过于谨慎或激进。
5. 论文核心观点 / 贡献
- 方法创新:提出首个少样本 EARD 框架,结合轻量级模仿智能体与无训练 LLM,智能体负责早期时间点决策,LLM 负责谣言检测, decouple 两模块,仅需训练智能体,降低计算成本。
- 建模创新:将 EARD 建模为 MDP,设计三类专家轨迹(CE、EAE、ME)捕捉准确性、早期性和规避误导行为,通过模仿学习让智能体学习最优策略,无需显式设计复杂奖励函数。
- 理论支撑:从理论上证明所提方法能导出早期、稳定、准确检测的最优策略,基于生成对抗模仿学习框架,通过占用测度匹配保证策略最优性。
- 实验验证:在四个真实数据集上验证框架有效性,适配 Mistral、Llama 3、ChatGPT 等 LLM,在准确性、早期性、泛化性、少样本鲁棒性上均优于传统 EARD 方法,为数据有限场景下的早期谣言检测提供实用解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号