RAAR:跨领域虚假信息检测的检索增强智能体推理框架
论文信息
论文标题:RAAR: Retrieval Augmented Agentic Reasoning for Cross-Domain Misinformation Detection
论文翻译:用于跨领域虚假信息检测的检索增强智能体推理框架
论文作者:Zhiwei Liu、Runteng Guo、Baojie Qu、Yuechen Jiang、Min Peng、Qianqian Xie*、Sophia Ananiadou(* 为通讯作者)
论文来源:arXiv 2026
发布时间:2026 年 1 月 8 日
论文地址:
论文代码:
二、研究背景与问题
1. 研究动机(现有方法不足)
跨领域虚假信息检测需利用已知源域数据训练模型,在未见过的目标域中识别虚假信息(如公共卫生、政治、金融等领域),但该任务面临显著挑战,现有方法存在三大核心缺陷:
- 单任务局限性:传统机器学习(ML)和深度学习(DL)方法需针对每个虚假信息任务(假新闻、谣言、阴谋论)单独微调或设计任务特定提示,无法跨任务泛化;
- 单视角建模缺陷:多数方法仅从单一维度(如语义)分析数据,忽略情感、写作风格等关键特征,在复杂或数据稀缺的目标域中性能骤降;
- 缺乏系统性推理:现有方法难以对模糊或隐含证据进行逻辑推理,且主流推理大语言模型(LLMs,如 GPT-o1、DeepSeek-R1)仅能处理同分布数据,无法应对跨领域知识结构和话语特征的巨大差异。
2. 研究问题
设计一种能实现跨领域知识迁移、多维度推理和多任务优化的框架,解决以下核心问题:
- 如何突破 “同分布假设”,为目标域样本匹配源域中多视角(语义、情感、风格)的辅助证据,实现跨领域信息互补;
- 如何通过多智能体协作构建可验证的多步推理路径,整合多维度特征以避免单视角偏差;
- 如何通过模型优化(监督微调 + 强化学习)提升模型在跨领域虚假信息检测任务中的泛化能力和推理可靠性。
三、Methods
本文提出的 RAAR 框架分为三大核心阶段,各阶段细节如下:
2.1 Task Formulation(任务定义)
- 核心目标:利用源域标注数据\(D_s\)(已知领域)提升目标域数据\(D_t\)(未见过的挑战性领域)的虚假信息检测性能;
- 数据定义:\(D_s, D_t \subseteq D = \{(x, y^*)\}\),其中\(x\)为文本内容,\(y^*\)为真实标签(如 “真实 / 虚假”“谣言 / 非谣言”“无关 / 相关 / 阴谋论”);
- 框架流程:通过 “检索增强数据构建→多智能体协作推理路径构建→模型优化” 三阶段,最终输出优化后的模型\(\pi_{\theta}^{RAAR}\),实现多视角推理和准确预测。
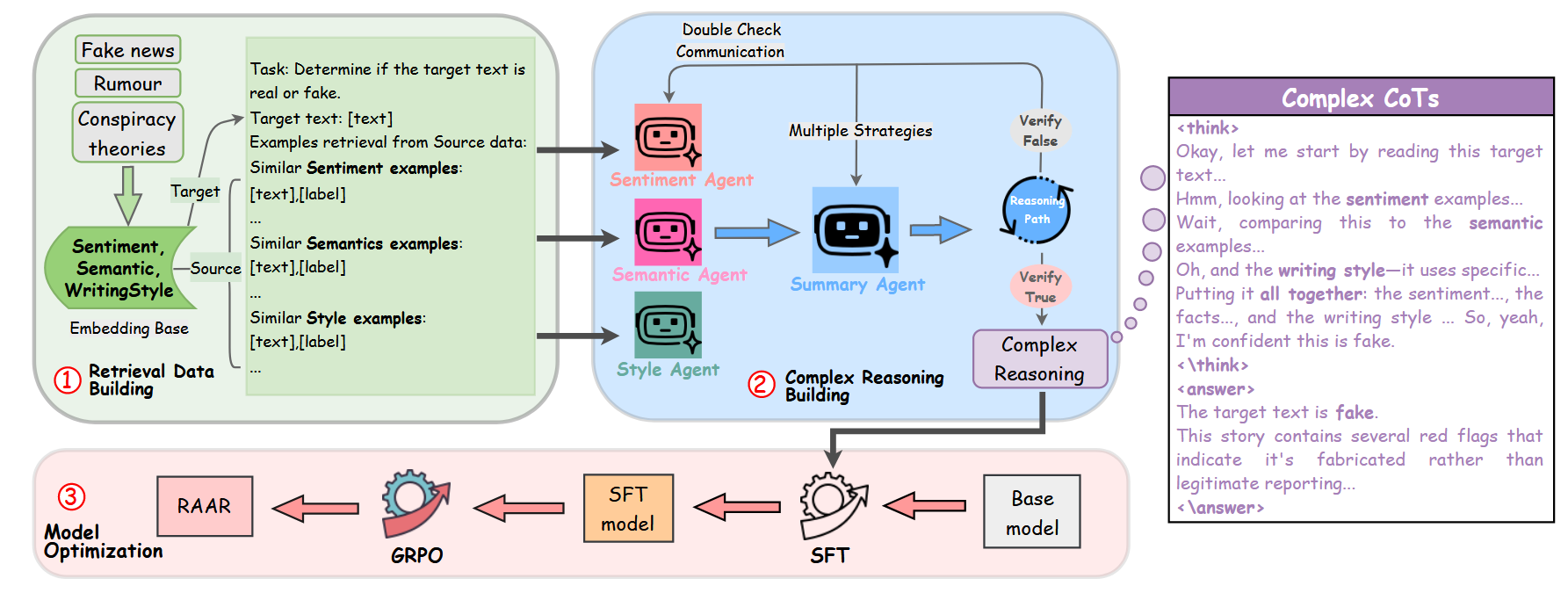
2.2 Stage 1: Retrieval Augmented Data Building(检索增强数据构建)
核心目标
为每个目标域样本检索源域中语义、情感、风格相似的样本,构建多视角辅助证据集,为后续推理提供跨领域参考。
关键步骤
- 特征嵌入选择:
- 情感嵌入:使用 EmoLlama 模型(Liu et al., 2024b)提取文本情感特征,生成目标域情感嵌入\(E_{sen}^t\)和源域情感嵌入\(E_{sen}^s\);
- 语义嵌入:使用 RoBERTa 模型(Liu et al., 2019)提取文本语义特征,生成\(E_{sem}^t\)和\(E_{sem}^s\);
- 风格嵌入:使用 StyleEmb 模型(Wegmann et al., 2022)提取文本写作风格特征,生成\(E_{sty}^t\)和\(E_{sty}^s\);
- 选择依据:通过统计分析(t 检验)验证,基于这三种特征检索的源域样本与目标域样本标签一致性更高(p<0.05),且优于其他嵌入模型(如 all-mpnet-base-v2、Sentibert)。
- 相似性计算与样本检索:
- 对每个目标域样本的情感 / 语义 / 风格嵌入,计算其与所有源域样本对应嵌入的余弦相似度;
- 为每个目标域样本选择Top-k 个最相似源域样本(最终实验选择 k=2,平衡性能与模型理解难度),构建检索增强数据\(x_{ra}\):\( x_{ra} = \{x_t, (x_{sen}^s, y_{sen}^s), (x_{sem}^s, y_{sem}^s), (x_{sty}^s, y_{sty}^s)\} \)
其中\(x_t\)为目标域样本,\((x_{sen}^s, y_{sen}^s)\)等为源域中情感 / 语义 / 风格相似的样本及标签。
- 数据拆分:
- 将检索增强数据集\(D_{ra} = \{(x_{ra}, y^*)\}\)平均拆分为两部分:
- \(D_{search}\):用于第 2 阶段 “多智能体协作推理路径构建”;
- \(D_{RL}\):用于第 3 阶段 “强化学习(RL)优化”。
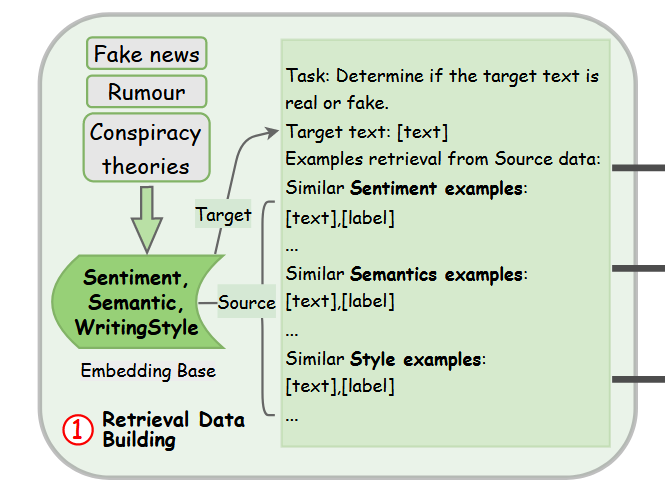
2.3 Stage 2: Multi-Agent Collaborated Reasoning Path Building(多智能体协作推理路径构建)
核心目标
通过专业子智能体与总结智能体协作,构建多视角、可验证的推理链(Chain of Thought, CoT),解决单视角推理的局限性。
关键组件与流程
- 智能体设计:
- 3 个专业子智能体:
- 情感智能体(\(A_{sen}\)):基于检索到的情感相似源域样本,分析目标域文本的情感倾向与虚假信息的关联;
- 语义智能体(\(A_{sem}\)):基于语义相似源域样本,解析文本语义逻辑、事实一致性与虚假信息的关系;
- 风格智能体(\(A_{sty}\)):基于风格相似源域样本,识别写作风格(如耸人听闻、正式报道)与虚假信息的特征关联;
- 1 个总结智能体(\(A_{sum}\)):整合 3 个子智能体的分析结果,构建统一推理路径,并在验证器(Verifier)指导下修正错误。
- 推理路径生成步骤:
- 步骤 1:子智能体初步分析:
子智能体分别对\(D_{search}\)中的样本进行分析,输出维度特定的推理片段(\(CoT^{sub}\))和初步预测(\(y^{sub}\)):\( CoT^{sub}, y^{sub} = \{A_{sen}(x_t, (x_{sen}^s, y_{sen}^s)), A_{sem}(x_t, (x_{sem}^s, y_{sem}^s)), A_{sty}(x_t, (x_{sty}^s, y_{sty}^s))\} \)
其中\(CoT^{sub} = \{CoT_{sen}, CoT_{sem}, CoT_{sty}\}\),\(y^{sub} = \{y_{sen}, y_{sem}, y_{sty}\}\)。
- 步骤 2:总结智能体初步推理:
总结智能体整合\(CoT^{sub}\)和\(y^{sub}\),生成初始推理链\(CoT_0\)和预测\(y_0\):\( CoT_0, y_0 = A_{sum}(CoT^{sub}, y^{sub}) \)
- 步骤 3:验证与推理修正:
- 验证器(基于 DeepSeek-v3.2-chat)判断\(y_0\)是否与真实标签\(y^*\)一致(\(Verifier(y_0, y^*) \in \{True, False\}\));
- 若\(y_0\)错误,智能体采用修正策略迭代优化:
- 子智能体策略:
- 双重检查(DC):告知子智能体总结结果错误,要求其自我验证并修正或补充理由;
- 跨智能体沟通(Communication):向子智能体共享其他智能体的分析,要求其结合他人观点修正;
- 总结智能体策略(5 种,基于子智能体输出优化):
- 跨智能体整合(Cross-agent consolidation):聚合子智能体输出生成统一答案;
- 跨智能体重审(Cross-agent reconsideration):交叉检查子智能体理由以重新评估推理;
- 跨智能体多样化(Cross-agent diversification):基于子智能体信号探索替代推理路径;
- 跨智能体验证(Cross-agent verification):评估推理在子智能体视角下的一致性;
- 跨智能体修正(Cross-agent rectification):利用子智能体内容修正推理缺陷;
- 迭代终止条件:最多迭代 3 轮(平衡效率与性能),若仍未找到正确推理路径,提供提示强制智能体重审历史步骤。
- 步骤 4:推理链与最终答案优化:
- 对迭代得到的正确推理链(\(CoT_0, CoT_1, ..., CoT_N\)),使用 LLM 重写为更符合人类直觉的推理过程(\(\hat{CoT}\));
- 基于\(\hat{CoT}\)生成最终答案\(\hat{y}\)(格式要求:首段明确标签,第二段总结推理理由):\( \hat{CoT} = LLM_{rephrase}(CoT_0, ..., CoT_N, x_{ra}), \quad \hat{y} = LLM_{refine}(\hat{CoT}, x_{ra}) \)
- 最终构建监督微调数据集\(D_{SFT} = \{(x_{ra}, \hat{CoT}, \hat{y})\}\)。
2.4 Stage 3: Model Optimization(模型优化)

通过 “监督微调(SFT)+ 强化学习(RL)” 两阶段优化,提升模型的跨领域推理能力和预测准确性。
2.4.1 Retrieval Augmented SFT(检索增强监督微调)
- 核心目标:引导模型在输出最终答案前先构建系统性推理链,强化多视角分析能力;
- 训练数据:使用\(D_{SFT} = \{(x_{ra}, \hat{CoT}, \hat{y})\}\),构造SFT模板;

- 损失函数:交叉熵损失,最小化模型预测与目标输出(\(\hat{CoT}, \hat{y}\))的对数损失:
\( L_{SFT}(\theta) = -\log \pi_{\theta}(\hat{CoT}, \hat{y} | x_{ra}) \)
其中\(\pi_{\theta}\)为初始 LLM(基于 Qwen3-8b/14b),通过梯度下降更新参数\(\theta\),得到微调后模型\(\pi_{\theta}^{sft}\);
- 训练细节:学习率 1e-5,预热比例 0.1,训练 3 轮,批大小 128,输入序列最大长度 24k tokens。
2.4.2 Reinforcement Learning(强化学习)
- 核心目标:进一步优化模型的推理可靠性和输出格式规范性,采用Group Relative Policy Optimization(GRPO)算法(Shao et al., 2024),相比传统 PPO 更节省内存且支持组级优化;
- 训练数据:使用\(D_{RL} = \{(x_{ra}, y^*)\}\),输入为\(x_{ra}\),模型输出为推理链\(CoT_{RL}\)和预测\(\hat{y}_{RL}\);
- 奖励机制:
- 格式奖励(Format Reward):若输出符合指定格式(“<think>\n[reasoning]\n</think>\n\n<answer> \n[firstsentence]\n\n[response]</answer>”),奖励 1,否则 0;
- 准确性奖励(Accuracy Reward):预测标签与\(y^*\)一致奖励 1,错误奖励 0.1,无输出奖励 0;
- 训练细节:每个样本滚动 8 次,批大小 1024,训练 5 轮,学习率 1e-6,采样温度 1,采用 DeepSpeed ZeRO-3 优化将参数卸载到 CPU 以节省 GPU 内存。
四、Experiment
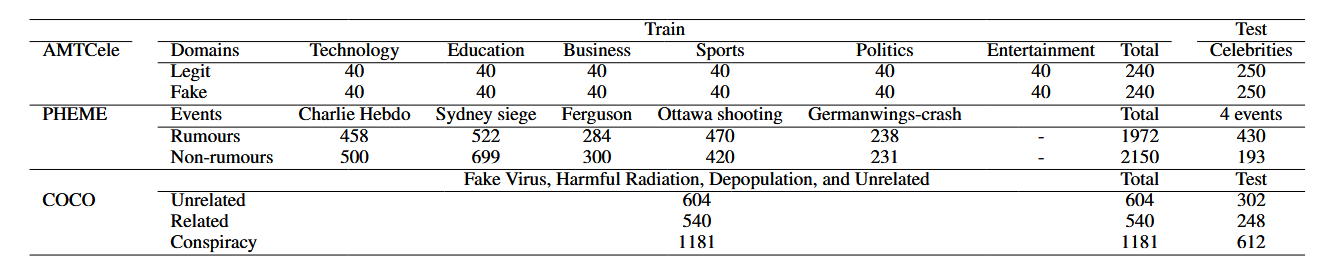
3.1 Datasets(数据集)
实验选择 3 个跨领域虚假信息检测数据集,均筛选出挑战性目标域(通过 GPT-4.1 和 DeepSeek-Chat 评估难度),具体信息如下:
3.2 Baselines(基准模型)
实验设置三类基准模型,全面对比 RAAR 的性能:
|
基准类别
|
具体模型 / 方法
|
说明
|
|
主流 LLMs
|
1. 推理导向 LLMs:GPT-5-mini(OpenAI, 2025)、DeepSeek-v3.2-Reasoner(Liu et al., 2025a)、Qwen3(8B/14B/32B,Yang et al., 2025);
2. 通用先进 LLMs:GPT-4.1(OpenAI, 2025)、DeepSeek-v3.2-Chat(Liu et al., 2025a)、Llama3.1-8b-instruct(Dubey et al., 2024)
|
分为 “零样本(ZS,无检索增强)” 和 “少样本(RA,基于 RAAR 检索的源域样本)” 两种设置
|
|
跨领域方法
|
MOSE(Qin et al., 2020)、EDDFN(Silva et al., 2021)、MDFEND(Nan et al., 2021)、CANMD(Yue et al., 2022)、MetaAdapt(Yue et al., 2023)
|
传统跨领域虚假信息检测方法,依赖领域自适应、对比学习等技术
|
|
LLM 适配方法
|
1. 指令微调(IT_zs:零样本微调;IT_ra:检索增强少样本微调);
2. RAEmoLLM(Liu et al., 2025c):基于情感检索的 RAG 框架;
3. MARO(Li et al., 2025):多智能体框架
|
基于 LLM 的跨领域适配方法,验证 RAAR 在 “检索 + 多智能体 + 优化” 组合上的优势
|
3.3 Settings and Evaluation(实验设置与评估指标)
- RAAR 模型构建:基于 Qwen3-8b 和 Qwen3-14b 分别训练 RAAR-8B 和 RAAR-14B;
- 评估指标:采用宏平均(macro)的准确率(ACC)、精确率(Pre)、召回率(Recall)和 F1 分数(核心对比指标);
- 硬件与优化:4 张 NVIDIA A100(80GB)GPU,全参数训练,采用 DeepSpeed ZeRO-3 优化。
3.4 Main Results(主要实验结果)
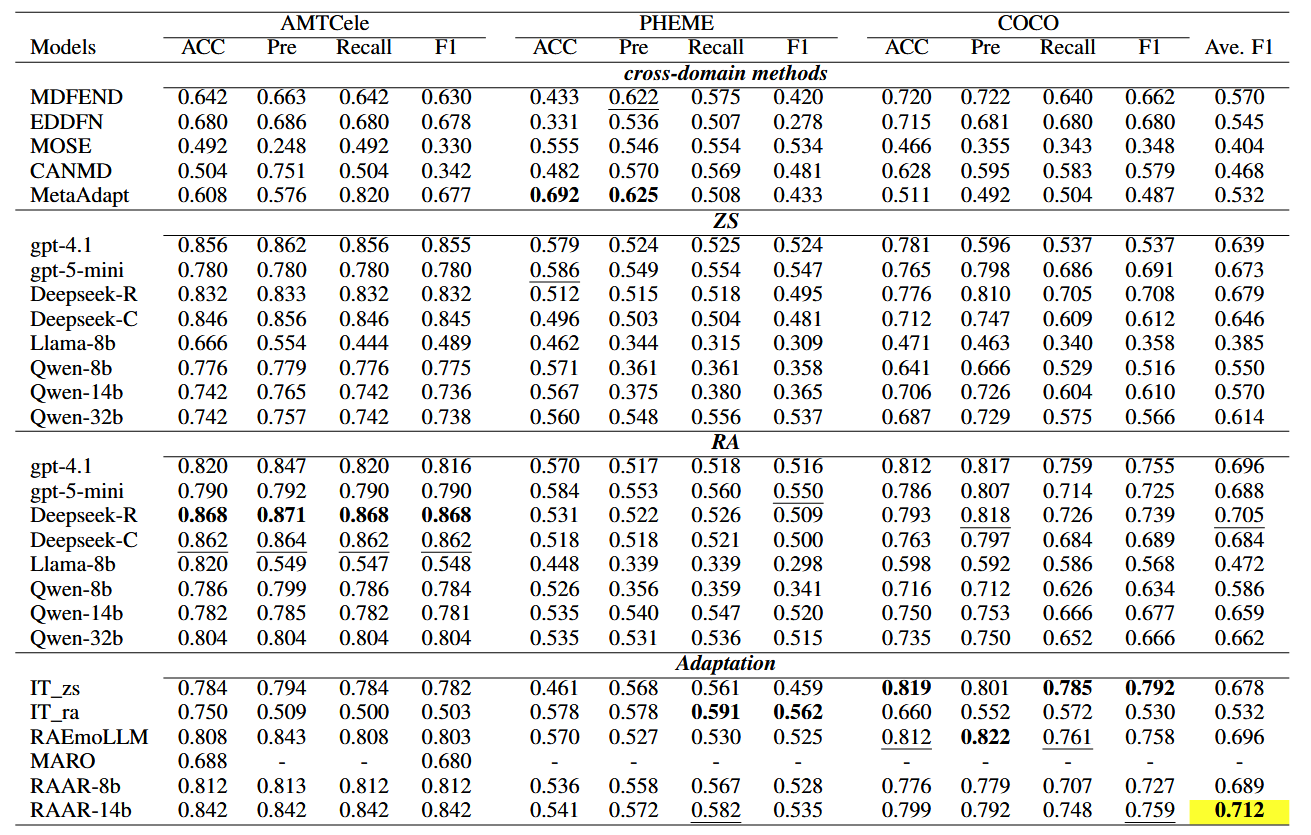
核心结论:RAAR 显著优于所有基准模型,且大幅提升基础模型性能
- 与跨领域方法对比:
- RAAR-14B 在 3 个数据集上的平均 F1 为 0.712,远超传统跨领域方法(如 MDFEND 的 0.570、MetaAdapt 的 0.532);
- 传统方法性能不稳定(如 MDFEND 在 AMTCele 上 F1=0.630,但在 PHEME 上仅 0.420),而 RAAR 在复杂目标域(如 PHEME 的 4 个事件)中仍保持稳定性能。
- 与 LLMs 对比:
- 基础模型优化:Qwen3-8b→RAAR-8B,平均 F1 从 0.550 提升至 0.689;Qwen3-14b→RAAR-14B,平均 F1 从 0.570 提升至 0.712;
- 超越先进 LLMs:RAAR-14B 平均 F1(0.712)高于 GPT-4.1(零样本 0.639、少样本 0.696)、DeepSeek-v3.2-Reasoner(0.679)和 Qwen3-32B(0.614);
- 少样本优势:所有 LLM 在 “少样本(RA)” 设置下性能均高于 “零样本(ZS)”,验证 RAAR 检索增强的有效性。
- 与 LLM 适配方法对比:
- RAAR-14B 平均 F1(0.712)高于 RAEmoLLM(0.696)、IT_zs(0.678)和 MARO(仅 AMTCele 上 F1=0.680);
- 传统适配方法局限性:IT_zs 在 COCO 上表现好(F1=0.792)但在 PHEME 上差(F1=0.459),RAEmoLLM 仅依赖情感检索,缺乏多视角推理,泛化能力弱。
3.5 Ablation Study(消融实验)
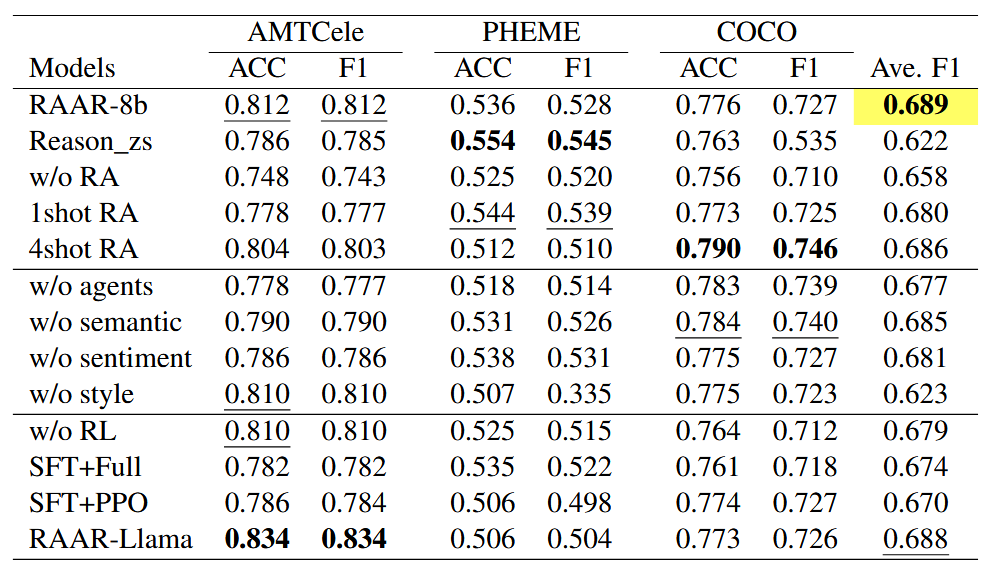
通过移除 RAAR 的关键组件,验证各模块的必要性(基于 Qwen3-8B,结果见表 ):
|
变体名称
|
核心修改
|
关键结论
|
|
Reason_zs
|
完全移除检索增强,仅基于目标域文本直接推理
|
1. 无检索时,模型缺乏源域知识参考,无法应对目标域与源域的分布差异;
2. 证明检索增强是实现跨领域知识迁移的核心前提,直接影响模型泛化能力。
|
|
w/o RA
|
保留 “少样本提示” 形式,但随机选择源域样本(替换基于语义 / 情感 / 风格的精准检索)
|
1. 随机选择的样本与目标域关联性低,无法提供有效辅助证据;
2. 验证 “基于多维度特征的精准检索” 比 “单纯增加样本量” 更重要。
|
|
1shot RA
|
每维度(语义 / 情感 / 风格)仅检索 1 个源域样本(原设置为 2 个)
|
1. 样本数量不足导致多视角证据覆盖不全,推理链缺乏足够支撑;
2. 少量样本难以平衡不同维度的特征互补性。
|
|
4shot RA
|
每维度检索 4 个源域样本(原设置为 2 个)
|
1. 过多样本增加模型理解负担,导致推理焦点分散;
2. 验证 “k=2” 是性能与模型效率的最优平衡点。
|
|
w/o agents
|
移除所有智能体,直接基于检索到的多维度样本推理
|
无智能体时,模型无法系统整合语义、情感、风格的分散信息;
证明多智能体协作能有效避免 “单视角偏差”,提升推理完整性。
|
|
w/o semantic
|
移除语义智能体,仅保留情感 + 风格智能体
|
1. 语义特征(事实逻辑)对长文本(如 AMTCele 假新闻)影响显著;
2. 但短期缺失可通过其他维度部分弥补,故性能下降较小。
|
|
w/o sentiment
|
移除情感智能体,仅保留语义 + 风格智能体
|
1. 情感倾向(如煽动性、焦虑感)是虚假信息的重要信号;
2. 对情感密集型文本(如 COCO 阴谋论)的识别精度下降明显。
|
|
w/o style
|
移除风格智能体,仅保留语义 + 情感智能体
|
1. 写作风格(如耸人听闻、匿名来源表述)是短文本(如 PHEME 谣言)的核心识别依据;
2风格特征的缺失导致模型无法区分 “真实新闻的客观表述” 与 “虚假信息的夸张风格”,是影响最大的单维度消融。
|
|
w/o RL
|
仅进行监督微调(SFT),移除强化学习(RL)阶段
|
1. RL 的奖励机制(格式 + 准确性)能进一步优化模型输出规范性;
2. 验证 “两阶段优化(SFT+RL)” 比单一微调更能提升推理可靠性。
|
|
SFT+PPO
|
RL 阶段用传统 PPO 算法替代 GRPO 算法
|
1. GRPO 的组级优化能力更适配多视角推理任务,能同时优化多个智能体的输出一致性;
2. GRPO 在内存效率上更优(支持更大批处理量),符合 RAAR 的长序列输入需求。
|
|
RAAR-Llama
|
将基础模型从 Qwen3-8B 替换为 Llama3.1-8B
|
1. RAAR 的框架设计(检索 + 智能体 + 优化)不依赖特定基础模型;
2. 证明其具有跨 LLM 架构的通用性,可适配不同开源 / 闭源模型。
|
3.6 Error Analysis(错误分析)
RAAR-14B 的错误主要源于对特定特征的过度依赖和语境理解偏差:
- 假新闻域:将耸人听闻的名人报道误判为虚假,将传统风格的虚假新闻误判为真实(过度依赖风格特征);
- 谣言域:将自信表述的未验证信息误判为非谣言,将讽刺性文本误判为谣言(缺乏语用理解);
- 阴谋论域:对含 “阴谋论关键词” 的文本过度标注为 “阴谋论”,对中性技术表述标注不足(过度依赖词汇线索)。
五、论文核心观点 / 贡献
1. 核心观点
跨领域虚假信息检测的关键在于 **“多视角证据互补”+“可验证多步推理”+“两阶段模型优化”**:通过检索源域多维度证据打破同分布限制,通过多智能体协作构建系统性推理链避免单视角偏差,通过 SFT+RL 强化模型的跨领域泛化能力和推理可靠性。
2. 三大核心贡献
- 创新性框架:提出首个用于跨领域虚假信息检测的 “检索增强智能体推理框架(RAAR)”,首次整合检索增强、多智能体协作、SFT 和 RL,实现跨领域知识迁移和多步推理;
- 多智能体设计:设计专业子智能体(语义 / 情感 / 风格)与总结智能体协作机制,通过动态修正策略构建多视角推理路径,显著提升跨领域推理能力;
- 实验验证:在 3 个数据集上验证 RAAR 的优越性,其训练的 RAAR-8B/14B 模型大幅超越传统跨领域方法、先进 LLMs 和 LLM 适配方法,为跨领域虚假信息检测提供新范式。
3. 局限性与未来方向
- 局限性:仅训练 8B/14B 模型,未探索更大模型或不同架构的影响;未纳入立场、论证结构等其他特征;COCO 数据集存在多主题交叉导致检索噪声;
- 未来方向:整合更多视角(如主题、立场);扩展至多语言和多模态跨领域检测;优化检索策略以减少噪声样本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号