AdSent 在对抗性情感攻击下使用大型语言模型进行鲁棒假新闻检测
论文信息
论文标题:Robust Fake News Detection using Large Language Models under Adversarial Sentiment Attacks
论文翻译:在对抗性情感攻击下使用大型语言模型进行鲁棒假新闻检测
论文作者:Sahar Tahmasebi、Eric Müller-Budack、Ralph Ewerth
论文来源:arXiv 2026
发布时间:2026 年 1 月 21 日
论文地址:
二、研究背景与问题
1. 研究动机(现有不足)
- 假新闻的社会危害与检测需求:虚假信息和假新闻(包含故意欺骗读者的虚假信息)已成为紧迫的社会挑战,导致人们难以在网络上识别和获取可靠信息,因此亟需可靠的自动化假新闻检测方法。
- 情感在假新闻检测中的双重性:已有研究证实情感是假新闻检测的重要信号,部分研究分析假新闻相关的情感类型,部分利用情感和情绪特征进行分类。但情感也成为攻击者的可乘之机 —— 攻击者可操纵情感以规避检测,尤其在大型语言模型(LLMs)出现后,LLMs 能轻松生成或重写具有可控情感的文本,加剧了区分真实与欺骗性内容的难度。
- 现有对抗性攻击研究的局限:少数研究探索了 LLMs 生成的对抗性样本,但主要聚焦于新闻出版商写作风格等文体特征,而情感操纵这一关键漏洞尚未得到充分研究,基于 LLMs 的情感对抗性攻击在假新闻检测领域仍处于未被深入探索的状态。
- 现有假新闻检测模型的缺陷:现有最先进的假新闻检测器在面对情感操纵时存在显著性能下降,且存在明显偏见 —— 倾向于将中性文章分类为真实新闻,将非中性文章分类为假新闻,缺乏对情感扰动的鲁棒性。
2. 研究问题
- 核心问题:设计一个对情感扰动鲁棒的假新闻检测框架,解决现有检测器在情感对抗性攻击下的脆弱性问题,确保模型对原始新闻和情感修改后新闻的真实性预测保持一致。
- 具体子问题:
- 基于文本的假新闻检测器能在多大程度上抵御 LLM 驱动的情感攻击?(RQ1)
- 哪种情感类型会使假新闻检测更具挑战性?(RQ2)
- 如何设计情感无关的训练策略,提升假新闻检测器对情感扰动的鲁棒性,并使其在未见过的数据集和对抗性场景中有效泛化?
三、Methods
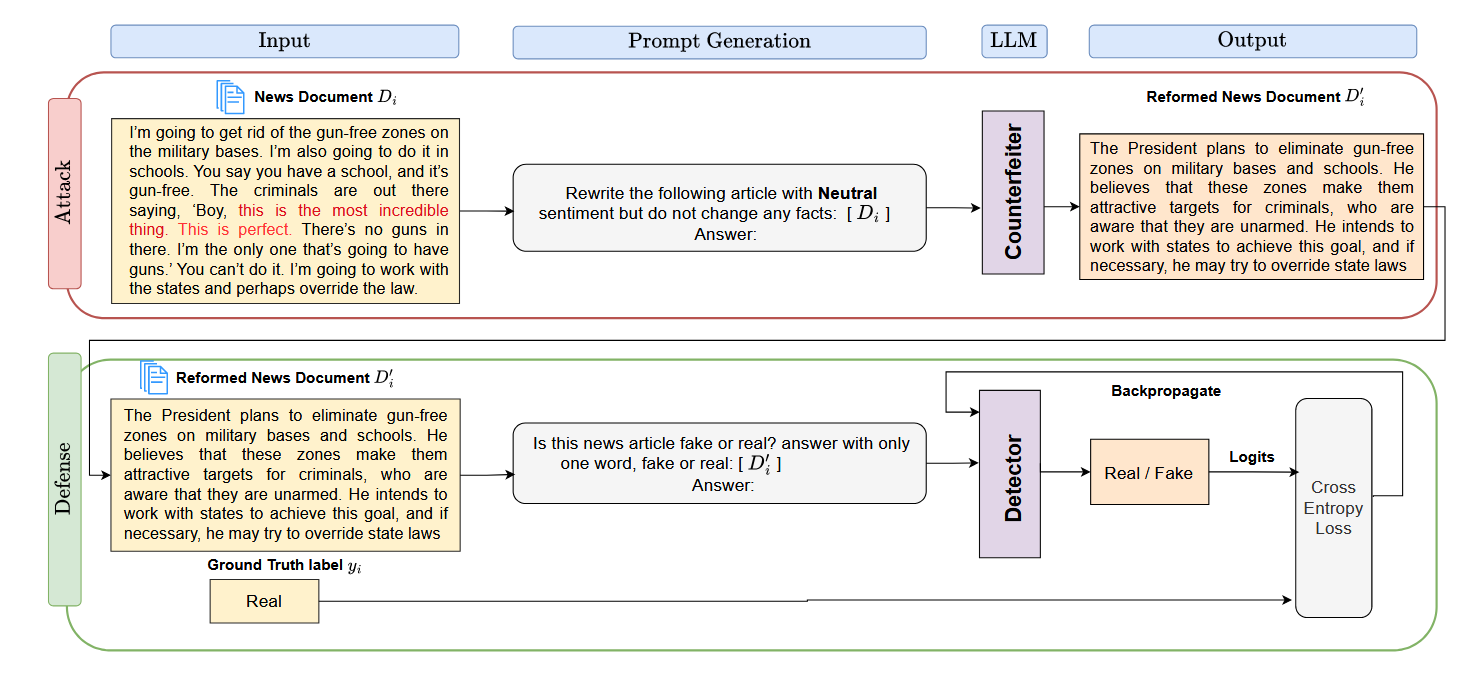
3.1 Sentiment Attack using LLMs(基于 LLM 的情感攻击)
核心目标
通过 LLMs 操纵新闻文档的情感,生成仅情感框架不同但事实内容和连贯性与原始文档一致的情感偏移变体,模拟攻击者在不改变新闻真实性的前提下,通过修改情感规避检测的对抗性场景,为后续评估检测器鲁棒性和设计防御策略提供数据支持。
情感变体生成方法
- 生成任务定义:给定包含\(m\)个新闻文档的语料库\(\mathbb{C}=\{D_{1}, D_{2}, ..., D_{m}\}\)(每个文档对应真实性标签\(y \in \{0,1\}\),0 为真实,1 为虚假),为每个文档\(D_{i}\)生成三个受控重构版本:积极情感变体\(\tilde{D}_{i}^{pos}\)、消极情感变体\(\tilde{D}_{i}^{neg}\)、中性情感变体\(\tilde{D}_{i}^{neu}\)。
- LLM 选择依据:LLMs 具备流畅重写文档且可控调整情感基调的能力,适合作为 “伪造器”(Counterfeiter)执行情感操纵任务。
- 生成约束条件:
- 事实保留:重写过程中必须保持所有事实细节不变,不引入新主张。
- 连贯性与真实性:生成的文本需连贯、真实,符合实际中虚假信息可能被操纵的方式。
- 格式要求:不包含提示文本,不总结或扩展原始文章,仅调整情感。
- 提示词设计:采用结构化提示词明确指导 LLM 生成目标情感变体,通用格式如下:
“Rewrite the following article with {positive, negative, neutral} sentiment but do not change any facts! Also, do not include the prompt in the response and do not summarize or expand the original article!”“用 {积极、消极、中性} 的情感重写下面这篇文章,但不要改变任何事实!另外,不要在回复中包含提示内容,也不要对原文进行总结或扩展!”
鲁棒性评估框架(针对 RQ1)
- 评估思路:将生成的情感偏移变体\(\tilde{D}_{i}^{pos}\)、\(\tilde{D}_{i}^{neg}\)、\(\tilde{D}_{i}^{neu}\)和原始文档\(D_{i}\)输入待评估的检测器(可视为黑箱分类器),在相同预处理和推理设置下,通过比较检测器在原始输入和情感操纵输入上的性能差异,量化检测器对情感对抗性攻击的鲁棒性,该框架具有模型无关性和可复现性。
情感挑战类型分析方法(针对 RQ2)
- 分析思路:从实例层面追踪文档在不同情感极性重写下检测器输出的变化,识别对假新闻检测最具挑战性的情感类型。
- 标记方案:记录每个新闻文档\(D_{i}\)的真实标签\(y_{gt}\)、原始文本上的预测结果\(y_{orig}\)、对抗性操纵后的预测结果\(y_{adv}\),用\(y_{gt}y_{orig} \to y_{adv}\)表示对抗性攻击下的预测变化;用 “R” 表示真实新闻(\(y=0\)),“F” 表示假新闻(\(y=1\)),例如 “RR→F” 表示原始被正确分类为 “真实” 的真实新闻,在情感操纵后被误分类为 “虚假”。
- 场景覆盖:通过上述标记方案,可覆盖 8 种可能的预测场景,从而独立于模型架构,分析情感偏移(积极、消极、中性)对分类可靠性的影响,挖掘模型偏见并确定最具挑战性的情感极性。
3.2 Sentiment-Agnostic Fake News Detection(情感无关的假新闻检测)
核心思想
通过 “伪造器” 生成中性情感的输入文档,训练仅依赖事实内容而非情感线索的假新闻检测模型,消除检测器对情感的偏见,提升其对情感扰动的鲁棒性。
具体步骤
- 中性情感文档生成:针对每个原始新闻文档\(D_{i}\),使用 LLM 作为 “伪造器”,按照 3.1 节中的方法生成中性情感版本\(\tilde{D}_{i}\)。选择中性情感的原因是,中性风格符合新闻机构客观报道事件的特点,能最大程度剥离情感干扰,聚焦事实内容。
- 模型选择与训练任务定义:
- 基础模型:采用 LLM(如 LLaMA [33])作为检测器模型,因其具备丰富的世界知识,且在虚假信息检测任务中已被证明有效([29, 31, 44])。
- 任务类型:将假新闻检测定义为有监督二元分类任务(真实 / 虚假)。
- 检测器提示词设计:指导 LLM 检测器输出明确的二元分类结果,提示词格式如下:
“Is this news article fake or real? Answer only with one word, fake or real : [news article] Answer:”
- 模型优化:
- 输出处理:对输入提示词编码后,提取 LLM(记为\(\theta\))对应 “fake” 和 “real” 令牌的对数概率(logits),通过 softmax 激活函数生成二维输出向量\(\hat{y}(\theta) \in [0,1]^2\)(对应两类的概率)。
- 损失函数:使用交叉熵损失函数优化模型,损失计算基于输出向量\(\hat{y}(\theta)\)与真实标签的独热编码向量\(y\)。
- 推理流程:推理时,首先使用 “伪造器” 将输入新闻文档转换为中性情感版本\(\bar{D}_{i}\),再将其输入训练好的假新闻检测模型,最终根据模型输出(“real” 或 “fake”)预测新闻的真实性\(y\)。
四、Experiment
4.1 Experimental Setup(实验设置)
4.1.1 Datasets(数据集)
- 选用数据集:采用三个广泛使用的真实世界基准数据集,分别为 FakeNewsNet 公共基准的 PolitiFact 和 GossipCop 数据集([28]),以及 Labeled Unreliable News(LUN)数据集([23]),数据集统计信息如下表:
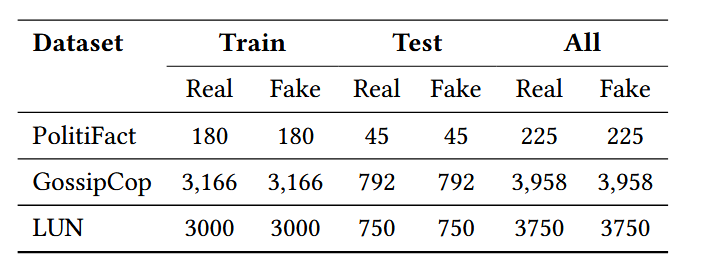
- 数据集特点:
- PolitiFact:以政治内容为主,文本声明直接从 PolitiFact 网站抓取。
- GossipCop:聚焦名人相关的八卦新闻。
- LUN:包含政治内容,原始将不可靠新闻分为讽刺、恶作剧、宣传三类,实验中统一视为虚假新闻,进行真实 / 虚假二元分类,并保证两类样本数量相等。
- 数据划分:
- PolitiFact 与 GossipCop:采用 Wu 等人([37])的时间划分策略(基于时间戳信息),最新 20% 的新闻文章(真实与虚假样本平衡)作为测试集,其余 80% 作为训练集。
- LUN:采用 Wang 等人([37])的随机 80/20 划分,80% 为训练集,20% 为测试集,确保与基线结果的可比性。
4.1.2 Baselines(基准模型)
将 AdSent 与三类代表性基准模型进行比较,覆盖不同技术路线的假新闻检测方法:
|
类别
|
模型
|
特点与说明
|
|
微调语言模型(G1)
|
RoBERTa [14]
|
将预训练语言模型适配假新闻检测任务,在虚假信息场景中表现出强有效性([21]);选用基础版本,与 AdSent 的检测思路保持可比性,是相关文献中表现突出的方法([37])
|
|
微调对抗性模型(G2)
|
SheepDog [37]
|
在对抗性数据变体上显式微调,以提升虚假信息检测的鲁棒性;聚焦新闻出版商风格扰动,设计风格鲁棒的假新闻检测器,优先基于内容而非风格判断新闻真实性
|
|
零样本 LLM(G3)
|
LLaMA-3.1-8B-Instruct [33]、Qwen2.5-7B-Instruct [40]
|
无需任务特定微调,直接利用 LLM 的预训练知识,通过精心设计的提示词泛化到假新闻检测任务;代表当前最先进的指令微调 LLM 家族
|
4.1.3 Implementation Details(实现细节)
- 开发环境:使用 PyTorch 2.4.1(搭配 CUDA 12.1),基于 Hugging Face Transformers 4.46.3 加载预训练的 LLaMA-3.1-8B-Instruct 权重。
- 训练参数:
- 优化器:AdamW 优化器。
- 批大小:PolitiFact 数据集为 1,GossipCop 数据集为 5。
- 训练轮次:5 个 epoch。
- 基线模型设置:遵循各基线作者提出的原始架构和超参数设置([14, 37]);零样本 LLM 预测采用贪心解码,每个实验运行 1 次。
- 模型量化与提示词:所有 LLM 采用 8 位量化加载;实验中使用 3 节描述的最优提示词(开发阶段探索多种提示词后选择效果最佳者,为简洁未展开细节)。
- 硬件配置:所有实验在两台配备 80GB 内存的 NVIDIA H100 GPU 上进行。
4.1.4 Metrics(评估指标)
- 核心指标:准确率(Accuracy, %)、精确率(Precision, %)、召回率(Recall, %)、宏 F1 分数(macro F1-score, %)。
- 结果稳定性:为确保鲁棒性,所有实验均报告 10 次独立运行的平均指标;但 LLM 情感操纵实验因生成长文本耗时且需人工验证事实保留情况,仅报告 1 次运行结果(见 4.2.3 节)。
4.2 Impact of Sentiment Manipulation(情感操纵的影响)
4.2.1 Robustness Against Sentiment Attacks(对情感攻击的鲁棒性,针对 RQ1)
- 实验设计:
- 假设验证:基于 Zaeem 等人([41])的研究假设 —— 真实新闻通常传达更积极的情感,而假新闻倾向于更消极的情感,通过情感操纵构建更具挑战性的测试集:将 PolitiFact 和 GossipCop 测试集中真实新闻的情感改为消极,假新闻的情感改为积极,同时保证事实内容不变(事实保留验证见 4.2.3 节)。
- 评估方式:在原始测试集和上述对抗性测试集上评估所有模型的性能,比较性能差异。
- 实验结果:如下表(展示宏 F1 分数及性能下降幅度):
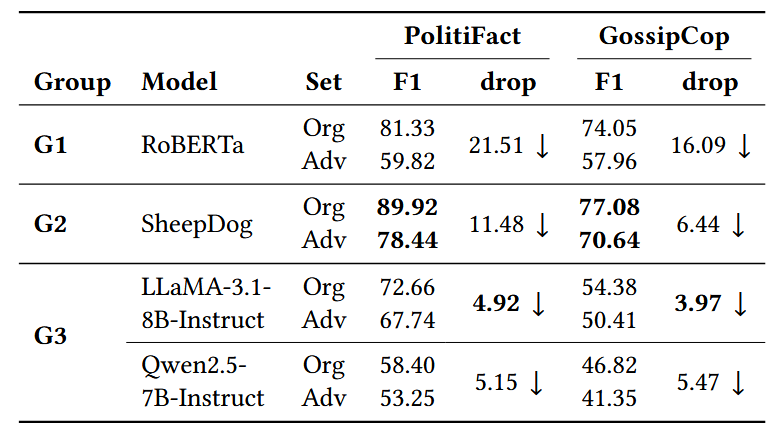
- 结果分析:
- 普遍脆弱性:所有最先进的假新闻检测器均易受 LLM 驱动的情感攻击,在 PolitiFact 对抗性测试集上性能下降最高达 21.51%,证明情感操纵是现有检测器的关键漏洞。
- 模型性能差异:有监督方法(G1、G2)尤其是 SheepDog 在原始测试集上表现优于零样本 LLM(G3),但在对抗性数据上性能下降更显著,说明其鲁棒性更弱,决策中存在更强的情感偏见。
- 零样本 LLM 的相对优势:零样本 LLM(如 LLaMA-3.1-8B-Instruct)性能下降幅度最小,可能因其预训练知识更丰富,对单一情感线索的依赖程度较低。
4.2.2 Impact of Sentiments Variations(情感变化的影响,针对 RQ2)
- 实验设计:
- 模型选择:选用 4.2.1 节中表现最佳且鲁棒性最强的 LLaMA-3.1-8B-Instruct 模型,分析其在 PolitiFact 原始测试集及情感修改变体(积极、消极、中性)上的性能。
- 评估指标:计算宏 F1 分数,并统计预测翻转次数(遵循 3.1 节的标记方案)。
- 实验结果:如下表(以 PolitiFact 和 GossipCop 数据集为例):
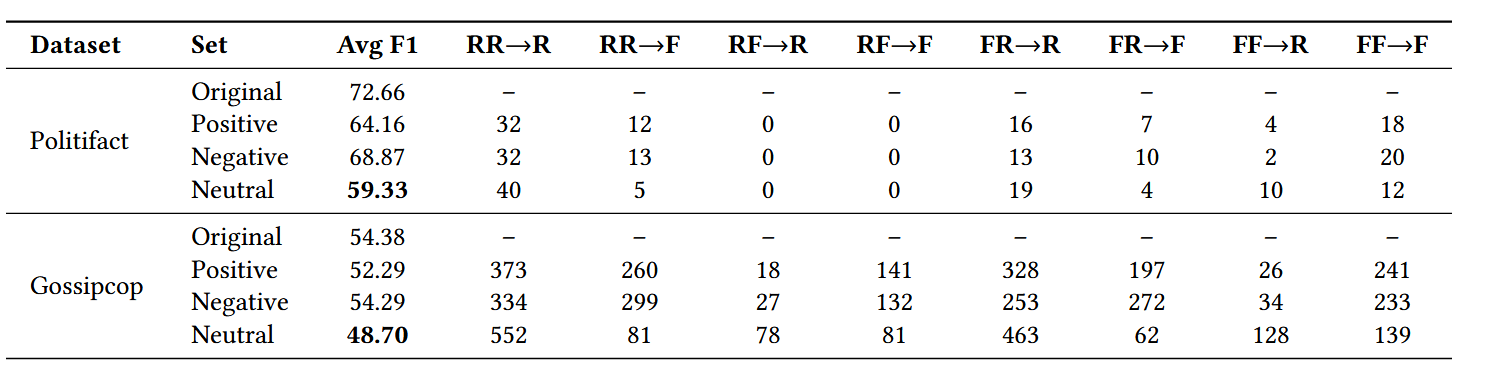
- 结果分析:
- 情感偏见揭示:与初始假设(积极情感与真实新闻相关、消极情感与假新闻相关)相反,模型更倾向于将中性文章分类为真实,非中性文章分类为虚假。原因可能是合法新闻机构通常追求客观报道,采用中性语气;而假新闻常依赖过度情绪化内容(积极或消极)说服读者。
- 最具挑战性的情感类型:中性情感对假新闻检测最具挑战性 —— 中性测试集的宏 F1 分数最低(PolitiFact 为 59.33,GossipCop 为 48.70);且假新闻在原始测试集中被正确分类为虚假,改为中性后被误分类为真实(FF→R)的案例数,显著高于积极或消极变体,该模式在两个数据集上均一致。
- 真实新闻的情感影响:原始被正确分类为真实的真实新闻(RR),改为中性后被误分类为虚假(RR→F)的案例数,低于改为积极或消极的情况,进一步验证中性情感对假新闻检测的独特挑战。因此,后续实验将中性测试集作为对抗性场景。
4.2.3 Consistency Check(一致性检查)
为确保情感操纵过程中事实内容保留,且原始新闻与修改变体一致,进行两项互补实验:
(1)事实保留验证(Fact Preservation)
- 实验设计:通过 LLM 检查和人类专家标注两种方式,直接评估情感操纵下的事实保留情况。
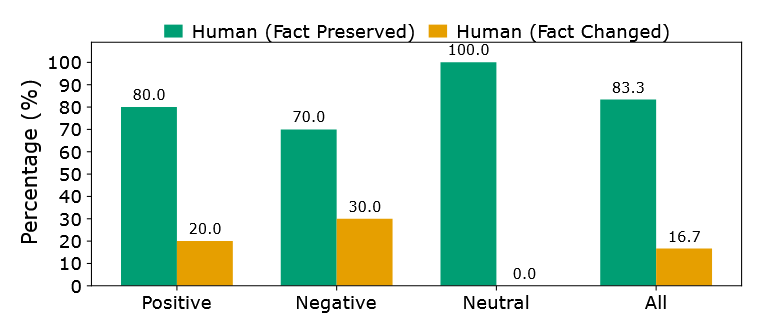
- 人类标注:由虚假信息分析专家从 PolitiFact 测试集中随机选择 30 篇文章(积极、消极、中性变体各 10 篇),手动比较原始文章与情感修改变体,标注事实是否保留(“flip=1” 表示事实改变,“flip=0” 表示事实保留)。
- LLM 作为判断器(LLM-as-a-Judge):以人类标注为真实标签,将相同的原始 / 修改文章对输入 LLM(LLaMA-3.1-8B-Instruct),通过提示词判断事实是否一致,计算人类与 LLM 标注的 Cohen’s Kappa 系数(衡量一致性)。LLM 提示词如下:
“Do the two documents present the same factual information regardless of sentiment? Answer with only one word: yes or no. Document A: [original article] Document B: [manipulated article] Answer:”“无论情感如何,这两份文件呈现的是相同的事实信息吗?仅用一个词回答:是或否。文件 A:[原文] 文件 B:[经过篡改的文章] 答案:”
- 实验结果:
- 人类标注结果:如图所示,原始新闻与情感修改变体的核心事实主张一致性较高,事实保留准确率在 70%-100% 之间;后续实验使用的中性情感变体准确率最高,标注子集中未发现事实扰动;消极情感变体准确率最低,主要因强制改为消极情感时,部分引语的事实内容发生偏移。
- LLM 判断结果:所有标注集的 Cohen’s Kappa 系数为 0.66,表明 LLM 在判断情感操纵下核心内容是否保留方面具有潜力,但仍需通过微调等方式进一步改进,以成为人类标注的可靠、低成本替代方案。
(2)LLM 一致性验证(LLM Consistency)
- 实验目的:验证 LLM 对新闻文章情感中性化的可靠性,确认 4.2.2 节的发现。
- 实验设计:
- 按 3.1 节的情感攻击方法,将 PolitiFact 测试集中所有文章的情感改为积极、消极或中性。
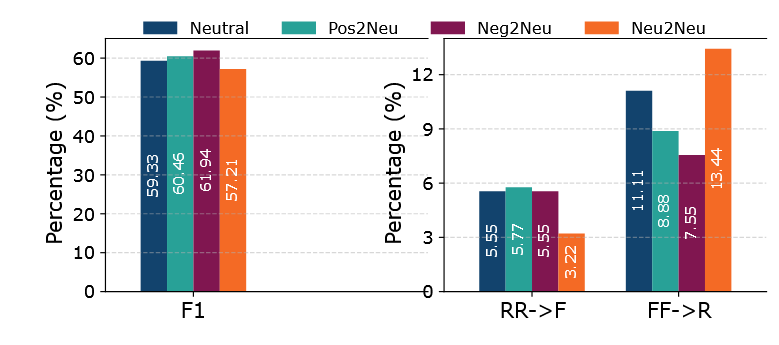
- 再次使用 “伪造器” 模型,将上述变体的情感改为中性,得到三个子集:积极→中性(Pos2Neu)、消极→中性(Neg2Neu)、中性→中性(Neu2Neu)。
- 计算各子集的宏 F1 分数和预测翻转次数(RR→F、FF→R),与原始中性测试集比较。
- 实验结果:
- 宏 F1 一致性:二级情感攻击(将已修改情感的文章再次改为中性)的结果与一级情感攻击(直接改为中性)相近,Pos2Neu、Neg2Neu、Neu2Neu 子集的宏 F1 分数与原始中性集差异不超过 ±2%。
- 预测翻转一致性:各子集的 RR→F(真实新闻被误分为虚假)和 FF→R(假新闻被误分为真实)比例,与原始中性集基本一致,最大偏差为 2.33%;其中 Neu2Neu 子集的 FF→R 翻转增加 2.3%,表明二级中性化可能使假新闻更难被检测。
- 结论:情感中性化直接影响假新闻检测结果,且 LLM 的情感中性化过程可靠。
4.3 Impact of Sentiment-Agnostic Training(情感无关训练的影响)
- 实验设计:在中性化测试集上评估 AdSent 与各基线模型的性能,消除情感特征对真实性检测的影响。各模型训练数据差异如下:
- 微调语言模型(G1):在原始训练集上训练。
- SheepDog(G2):在原始训练集 + 风格修改变体上训练(按其官方论文描述)。
- AdSent:在训练集的中性化变体上训练。
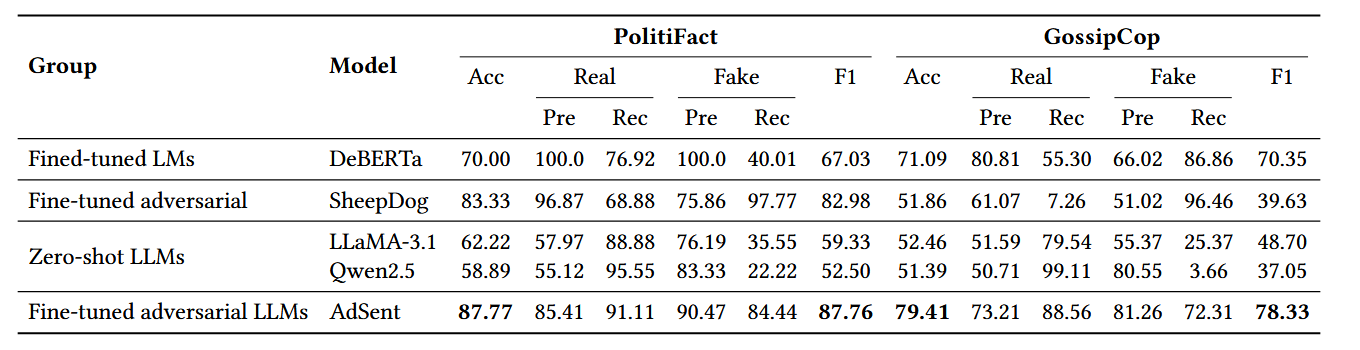
- 实验结果:如下表(以 PolitiFact 和 GossipCop 数据集为例,展示核心指标):
- 结果分析:
- AdSent 的优越性:AdSent 在两个数据集的中性化测试集上均显著优于所有基线,PolitiFact 宏 F1 达 87.76,GossipCop 达 78.56,证明情感无关训练能有效提升模型在无情感干扰下的检测性能。
- 各基线的缺陷:
- 零样本 LLM(G3):对中性样本存在强烈的 “真实” 预测偏见,假新闻召回率极低,表明无情感线索时,其更像粗粒度的语气判别器,而非鲁棒的真实性检测器。
- SheepDog(G2):虽经对抗性训练,但针对的是风格扰动;情感线索被中性化后,其性能下降,说明对风格偏移的鲁棒性无法完全迁移到情感干扰场景。
- AdSent 的优势本质:AdSent 在中性化数据上训练,形成情感无关的决策边界,行为更均衡。
4.4 Generalization Study(泛化性研究)
为验证 AdSent 在真实场景中的实用性,从 “不同对抗性数据” 和 “不同内容” 两个维度评估其泛化能力:
4.4.1 Different Adversarial Data(不同对抗性数据)
- 实验设计:
- 对抗性数据来源:采用 SheepDog 论文([37])提出的 PolitiFact 测试集对抗性变体,该变体通过 LLM 进行风格迁移攻击:将真实新闻的风格改为《国家询问报》(National Enquirer,集 A)和《太阳报》(The Sun,集 B),将假新闻的风格改为《CNN》(集 C)和《纽约时报》(集 D),共 4 个对抗性测试集。
- 对比模型:SheepDog(专门针对该风格迁移攻击微调 RoBERTa,是强基线)与 AdSent。
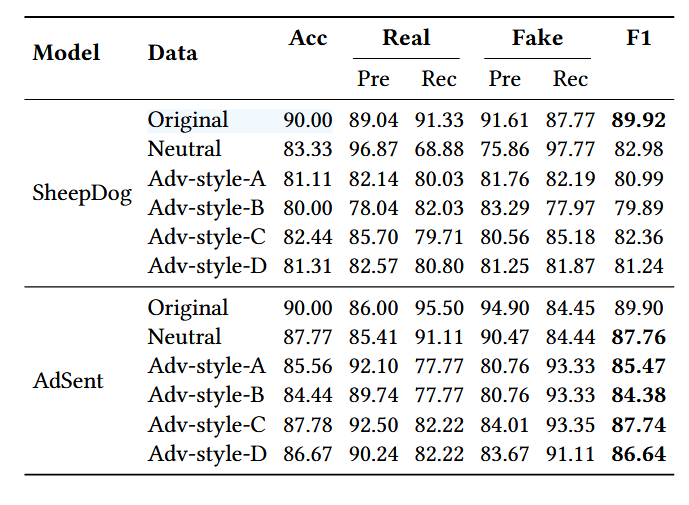
- 实验结果:如表所示,AdSent 在所有对抗性测试变体上均持续优于 SheepDog,准确率和宏 F1 分数更高。
- 结论:
- 尽管 SheepDog 为该风格攻击专门设计,但 AdSent 在相同场景下仍有效且性能更优,说明情感偏移对模型预测的影响可能强于文体变化。
- AdSent 通过对抗性情感训练获得的鲁棒性,可泛化到风格攻击场景,使其在不同类型扰动下均能保持强性能。
4.4.2 Different Content(不同内容)
- 实验设计:
- 跨数据集设置:在 PolitiFact 数据集上训练 AdSent 和 SheepDog,在 LUN 数据集上测试(两数据集均聚焦政治内容,但收集过程和标注方案不同,适合评估训练分布外的泛化能力)。
- 评估范围:同时评估模型在 LUN 原始测试集和中性化测试集上的性能。
- 实验结果:如下表所示:
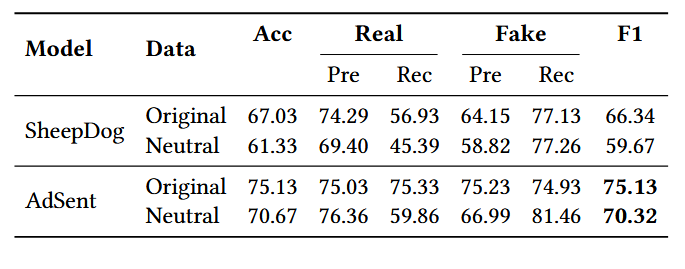
- 结果分析:
- AdSent 的泛化优势:在 LUN 原始和中性化测试集上,AdSent 均持续优于 SheepDog,证明其对情感扰动的鲁棒性可迁移到未见过的数据集。
- 性能下降对比:两模型在中性化测试集上均出现性能下降,但 AdSent 的下降幅度更小,表明对抗性情感训练结合 LLM 的表征能力,使 AdSent 获得了更具迁移性的特征,能泛化到训练分布外的场景;而 SheepDog 虽经对抗性训练,但过度拟合训练集特征,在新数据集上表现较差。
4.5 实验结论
- 情感攻击的危害性:现有最先进的假新闻检测器(包括微调语言模型、对抗性微调模型、零样本 LLM)均易受 LLM 驱动的情感攻击,性能显著下降,暴露了当前检测方法的关键漏洞。
- 中性情感的挑战性:中性语气的内容对假新闻检测最具挑战性,现有模型普遍存在 “中性 = 真实”“非中性 = 虚假” 的偏见,需通过情感无关训练消除该偏见。
- AdSent 的有效性:AdSent 通过情感无关训练策略,在三个基准数据集上的准确率和鲁棒性均显著优于基线模型,且能有效泛化到未见过的数据集和不同类型的对抗性场景(如风格攻击)。
- LLM 在情感操纵与判断中的作用:LLM 可可靠地生成情感修改且事实保留的新闻变体,也可作为事实一致性的初步判断器,但需进一步优化以替代人类标注。
五、论文核心观点 / 贡献
1. 核心观点
- 情感操纵是假新闻检测器的关键漏洞:现有假新闻检测模型过度依赖情感线索,攻击者可利用 LLM 轻松修改新闻情感以规避检测,导致模型性能大幅下降;且模型普遍存在 “中性 = 真实”“非中性 = 虚假” 的偏见,中性情感修改对检测的干扰最大。
- 情感无关训练是提升鲁棒性的有效途径:通过 LLM 将训练数据转换为中性情感版本,训练仅依赖事实内容的检测器,可消除模型对情感的依赖,构建情感无关的决策边界,显著提升对情感攻击的鲁棒性。
- 鲁棒性具有跨场景泛化性:针对情感攻击训练的鲁棒性,可迁移到其他类型的对抗性场景(如文体风格攻击)和未见过的数据集,说明情感无关训练能让模型学习到更本质的事实性特征,而非数据集或攻击类型特定的表面特征。
2. 核心贡献
- 提出情感定向的对抗性基准测试:设计基于 LLM 的受控情感攻击套件,在保留事实内容的前提下修改新闻情感(积极、消极、中性),评估最先进假新闻检测器的性能,揭示模型对情感操纵的脆弱性及 “中性 = 真实” 的偏见,明确中性情感是假新闻检测的最大挑战。
- 提出 AdSent 情感鲁棒检测框架:设计新颖的情感无关训练策略,通过 LLM 生成新闻的中性情感变体,微调 LLM 检测器,确保模型对同一新闻的不同情感变体保持一致的真实性预测,提升模型在真实对抗性场景中的可靠性。
- 全面的评估与泛化性研究:在三个基准数据集上进行广泛实验,证明 AdSent 在准确率和鲁棒性上显著优于现有基线;进一步通过跨对抗性场景(风格攻击)和跨数据集(PolitiFact→LUN)实验,验证 AdSent 的有效泛化能力,为真实场景应用提供支撑。
- 开源资源支持:公开代码和数据(GitHub:https://github.com/TIBHannover/AdSent),为后续假新闻检测鲁棒性研究提供可复现的实验基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号