RADAR: Retrieval-Augmented Detector with Adversarial Refinement for Robust Fake News Detection
RADAR
一、基础信息
|
类别
|
详情
|
|
标题
|
RADAR: Retrieval-Augmented Detector with Adversarial Refinement for Robust Fake News Detection
RADAR:用于鲁棒假新闻检测的、带有对抗性优化的检索增强检测器
|
|
作者
|
Song-Duo Ma*、Yi-Hung Liu*、Hsin-Yu Lin*、Pin-Yu Chen*、Hong-Yan Huang*、Shau-Yung Hsu*、Yun-Nung Chen(* 表示同等贡献)
|
|
来源
|
未明确提及具体期刊或会议,仅标注 arXiv:2601.03981v1 [cs.CL]
|
|
发布时间
|
2026 年 1 月 7 日
|
二、研究背景与问题
1. 研究动机(现有不足)
- 假新闻传播现状严峻:研究表明,社交媒体上假新闻的传播范围更广、速度更快(Vosoughi et al., 2018);大型语言模型(LLMs)进一步降低了大规模生成流畅、有说服力的伪造内容的门槛(Zellers et al., 2019),对公共话语和民主进程构成重大威胁。
- 现有假新闻检测器存在缺陷:现代假新闻检测器通常是为追求效率和强辨别力而微调的基于编码器的分类器,但在对抗性扰动下表现脆弱 —— 微小的词汇修改或有针对性的事实修改会导致其性能急剧下降(Jin et al., 2020)。在实际应用中,攻击者会反复探测检测器并优化重写内容,使得检测器部署成为一个动态目标,因此需要检测器持续适应新的攻击模式。
- 传统对抗训练存在局限:传统文本生成对抗网络(GAN)如 SeqGAN(Yu et al., 2017)依赖强化学习解决不可微问题,常导致训练不稳定(高方差、模式崩溃)。更根本的是,检测器通常仅提供标量概率,无法为生成器提供关于 “为何样本被识别” 以及 “如何修改样本” 的指导,且语言 GAN 在质量 - 多样性权衡方面常不如简单的最大似然目标训练的语言模型(Caccia et al., 2020)。
- 现有相关工作的不足:在假新闻检测相关研究中,部分工作未充分结合检索增强;部分结合检索的工作,或仅在生成器侧使用检索提供真实感先验,或仅在检测器侧使用检索提供外部证据,缺乏双端检索结合的对抗性设计;同时,自然语言反馈相关工作多为合作框架,未应用于对抗性的假新闻检测场景。
2. 研究问题
设计一个鲁棒的假新闻检测框架,该框架需满足以下需求:
- 具备高效可更新的检测器,能够持续适应攻击者不断进化的攻击模式。
- 生成器能产生难度高、真实度高的对抗性样本,这些样本需超越表面的风格伪影,以有效暴露检测器弱点,辅助检测器优化。
- 解决传统标量奖励指导不足的问题,为生成器提供可解释、可操作的反馈信号,实现生成器与检测器的稳定协同进化,最终提升检测器在对抗性假新闻检测任务中的性能。
三、Methods
3.1 Task Definition(任务定义)
- 核心任务:给定新闻文章\(x\),预测二元标签\(y \in \{0,1\}\)(0 表示假新闻,1 表示真新闻),同时输出决策置信度\(P(real | x)\)。以 ROC-AUC 作为主要评估指标。
- 框架组成:
- 生成器(Generator, G):输入真实新闻文章,生成旨在规避检测的假新闻变体。
- 检测器(Detector, D):对文章进行真假分类,输出决策置信度和口头对抗反馈(Verbal Adversarial Feedback, VAF)。VAF 是结构化文本评论,包含通过注意力分析识别的可疑token、分类检测原因和改进建议,用于指导后续轮次中生成器的优化。
- 目标:通过生成器与检测器的迭代对抗协同进化,使生成器能生成更具迷惑性的假新闻,同时推动检测器提升检测能力。
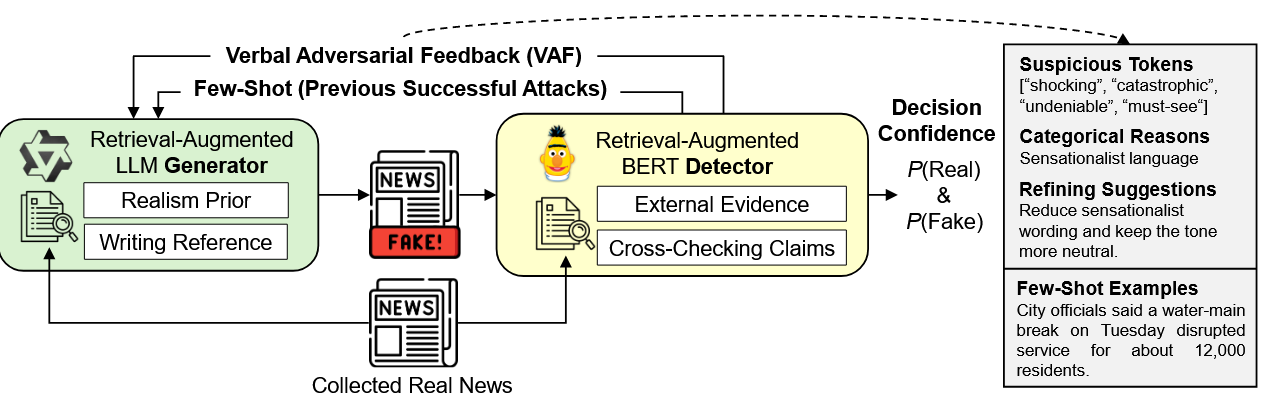
3.2 RADAR Framework(RADAR 框架)
- 训练流程:训练以轮次进行,生成器与检测器在每轮中迭代协同进化,具体流程如下:
- 从训练语料库中采样真实新闻文章。
- 若启用检索,通过密集段落检索(DPR)(Karpukhin et al., 2020)从外部新闻语料库中检索相关段落作为辅助上下文:对生成器而言,检索片段提供真实感先验;对检测器而言,检索片段提供用于验证的证据线索。
- 生成器将真实新闻文章\(x\)重写为假新闻变体\(\hat{x}\)。
- 检测器对真实新闻\(x\)和假新闻变体\(\hat{x}\)进行评分,除输出决策置信度\(P(real)\)外,还生成 VAF。
- 将 VAF 附加到下一轮生成器的提示中;同时,缓存少量成功的对抗性重写样本作为few-shot少样本示例,也添加到下一轮生成器的提示中。此外,定期使用低秩适应(LoRA)(Hu et al., 2022)在成功的对抗性示例上微调生成器,以实现持续适应。
- 检索配置:检索模块可独立为生成器或检测器启用,形成四种配置(G−/D−、G+/D−、G−/D+、G+/D+),可通过实验比较不同配置的性能。
3.2.1 Retrieval Module(检索模块)
- 核心技术:采用密集段落检索(DPR)模块,利用 DPR 上下文编码器对新闻语料库构建 FAISS 索引,获取每篇文章的密集嵌入。在推理时,使用 DPR 问题编码器对输入的完整文章进行编码,检索前\(k\)个最近邻。
- 检索内容作用:
- 生成器侧:检索到的段落提供风格和合理性线索(如新闻结构、典型细节范围),帮助生成更真实的假新闻文章。
- 检测器侧:检索到的段落提供外部证据,用于交叉验证输入文章中的主张。
- 灵活性:可独立为生成器或检测器启用 / 禁用检索,便于分离检索增强对生成和检测的影响。
3.2.2 Generator(生成器)
- 基础模型与优化:基于 Qwen3-4B-Instruct(Qwen Team, 2025),使用 LoRA 进行微调,以生成能规避检测的假新闻文章。LoRA 配置为秩\(r=16\)、alpha\(\alpha=32\)、 dropout=0.05,实现参数高效微调。
- 输入与输出:给定真实新闻文章\(x\)、启用检索时的检索上下文\(c\)以及前一轮的信号(VAF 和少样本示例),生成假新闻变体\(\hat{x}=G(x, c, VAF_{t-1}, E_{t-1})\),其中\(VAF_{t-1}\)为前一轮的口头对抗反馈,\(E_{t-1}\)为缓存的少量少样本示例,二者均为可选输入,独立融入提示中。
- 提示结构:
- 系统指令:明确对抗目标,要求在保留新闻风格、避免耸人听闻语言的同时,引入 1-2 处事实修改(修改实体、地点、日期、关键数字或结果)。
- 用户提示:包含五个部分:待重写的原始真实新闻文章、为真实新闻写作提供风格参考的检索上下文、前一轮标识需避免模式的 VAF、前一轮缓存的少样本示例(成功规避检测的对抗性重写,满足\(P(real | \hat{x})>0.6\))、指定所需事实编辑和格式约束的任务指令。
- 生成约束:生成过程中需保留原始段落结构和近似长度,避免 Markdown 格式,全程使用中立专业的语气。
3.2.3 Detector(检测器)
- 基础模型与任务:基于 DeBERTa-v3-base(He et al., 2021)编码器,微调用于二元分类(真 / 假新闻)。训练使用 AdamW 优化器,批大小为 2,处理输入序列长度最多为 512 个令牌。
- 输出:给定输入文章\(x\)(启用检索时附加证据),输出决策置信度\(P(real | x)\)(表示文章为真的可能性),同时生成 VAF,为生成器的进化提供可解释、可操作的指导,弥补标量决策置信度在指导生成器优化方面的不足。
3.2.4 Verbal Adversarial Feedback(口头对抗反馈,VAF)
- 核心作用:作为结构化评论,替代传统标量奖励,为生成器提供类似梯度的优化信号(包含强度、空间位置、错误类型和更新方向),基于注意力启发式而非精确梯度计算,优势在于可解释性,使生成器能进行语义层面的更新而非随机更新。
- 组成部分:
- 可疑令牌识别(Suspicious Token Identification):通过检测器最终 Transformer 层的注意力权重提取可疑token。计算 [CLS] 令牌(聚合序列表示)到其他所有位置的注意力向量(平均所有注意力头),屏蔽特殊令牌并过滤标准停用词后,选择注意力权重最高的前\(k\)个token作为最显著的人工伪影指标。
- 检测原因(Detection Reasons):基于识别的令牌和分类置信度,分配一个或多个分类检测原因,包括:耸人听闻的语言(存在 “shocking”“unbelievable” 等词)、模糊归因(使用 “sources say”“reportedly” 等短语)、事实不一致(假新闻概率高但无其他检测模式)、风格不匹配(偏离典型新闻语气)。
- 改进建议(Improvement Suggestions):针对每个检测原因,检测器基于置信度和令牌显著性信号,通过基于模板的语言化生成 VAF,将其映射为少量分类原因和相应建议。例如,针对耸人听闻的语言,建议使用中性替代词;针对模糊归因,建议使用特定的命名来源。这些建议与标记的令牌共同构成下一轮注入生成器提示的 VAF。此外,决策置信度作为标量信号单独提供,用于选择成功的对抗性示例和监控攻击进展。
3.3 Training Strategy(训练策略)
- 训练模式:训练以轮次进行,交替更新生成器和检测器(完整流程见附录 B 中的算法 1)。
- 检测器训练:每轮构建由真实文章和生成的假新闻组成的平衡批次,使用交叉熵损失训练检测器,损失函数为:
\(\mathcal{L}_{D}=-\sum_{i}\left[y_{i} \log p_{i}+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right]\)
其中\(y_{i} \in \{0,1\}\)为真实标签,\(p_{i}=P(real | x_{i})\)为检测器预测文章为真的概率。
- 生成器训练:完全避免策略梯度方法,通过三种独立机制实现生成器优化:
- 基于 VAF 的提示调整:通过 VAF 条件提示实现生成器行为的即时调整。
- 少样本示例引导:在提示前附加少样本示例,为生成器提供具体的规避检测的重写案例。
- 基于 LoRA 的监督微调:每轮收集成功的对抗性示例(生成的假新闻\(\hat{x}\)满足\(P(real | \hat{x})>0.6\),即能欺骗检测器),选择前\(m\)个作为 LoRA 微调的训练目标,最小化以下目标函数:
\(\mathcal{L}_{G}=\mathcal{L}_{CE}+\lambda_{KL} \cdot D_{KL}\left(\pi_{\theta} \| \pi_{ref }\right)\)
其中\(\mathcal{L}_{CE}\)为所选示例的语言建模损失,KL 项用于将 LoRA 适配的策略与冻结的基础模型进行正则化,防止分布偏移。训练使用 AdamW 优化器,KL 散度惩罚系数\(\lambda=0.01\),并应用梯度裁剪以稳定更新。
四、Experiment
4.1 Experimental Setup(实验设置)
数据集与检索索引
- 实验数据集:使用 Chen 等人(2025)发布的 AdvFake-News-Please 数据集,该数据集包含来自 NewsPlease 存储库的真实新闻文章及其对应的对抗性假新闻(402条)。
- 检索语料库:使用与数据集配套的公共新闻数据库作为检索语料库,包含约 81.1 万篇来自多个新闻来源、同一日期范围的新闻文章。为减少检索污染和数据泄露,从检索语料库中移除了确切的种子真实新闻文章,并进行去重过滤(移除完全重复和高度重叠的文章),但保留语义相似的跨媒体报道以用于交叉验证。
- 检索索引构建:使用预训练的 DPR 模型进行段落索引和查询编码,通过 FAISS 构建密集向量索引。在对抗性轮次中,根据输入新闻内容的语义相似性检索前\(k\)个相关段落,生成器和检测器的\(k\)值均设为 3。
Baselines(基准模型)
选择多个通用 LLM 作为基准模型,包括 Mistral-7B-Instruct-v0.3(Mistral AI, 2023)、Llama-3.1-8B-Instruct(Meta AI, 2024)、Qwen2.5-7B-Instruct(Qwen Team, 2024)。在两种设置下评估这些基准模型的 ROC-AUC 得分:无检索(No Retrieval)和新闻数据库检索(News Database Retrieval,检测器通过检索语料库获取证据进行增强)。
模型实现细节
- 生成器实现:初始模型为 Qwen3-4B-Instruct,使用 LoRA 进行参数高效微调(秩\(r=16\)、alpha\(\alpha=32\)、dropout=0.05)。生成器在成功的对抗性示例(满足\(P(real)>0.6\)的假新闻)上通过监督微调更新,使用 AdamW 优化器(学习率\(1Ã10^{-4}\)),并施加 KL 散度惩罚(\(\lambda=0.01\))以防止模型偏离基础分布。
- 检测器实现:基于 DeBERTa-v3-base 架构,微调用于二元分类(真 / 假新闻)。训练使用 AdamW 优化器(学习率\(5Ã10^{-6}\)),批大小为 2,处理输入序列长度最多为 512 个令牌。
4.2 Main Results(主要结果)
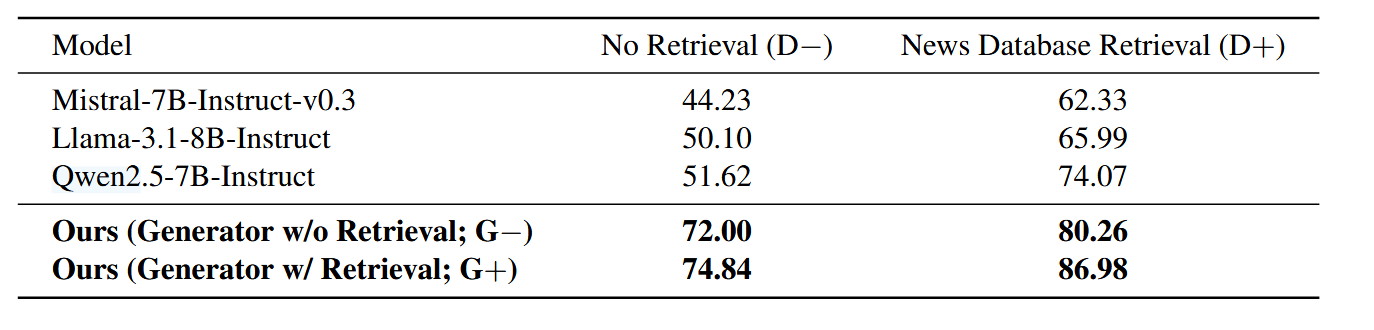
- 核心对比:在 AdvFake-News-Please 评估集上比较 RADAR 与基准 LLM 的 ROC-AUC 得分。
- 关键发现:
- 基准模型性能局限:当检测器侧检索禁用(D−)时,基准模型性能接近随机猜测,表明在无证据设置下,对抗性假新闻在风格上可与真实新闻区分度极低。
- 检索对基准模型的提升:启用检测器侧检索(D+)后,基准模型性能显著提升(ROC-AUC 达 62.33%-74.07%),说明外部证据有助于假新闻验证,但即便如此,其性能仍落后于 RADAR 的协同进化框架。
- RADAR 的优势:RADAR 在(G−/D+)配置下 ROC-AUC 达 80.26%,在完整(G+/D+)配置下进一步提升至 86.98%,表明仅靠检索不足以实现高精度的自适应对抗性假新闻检测,而专门的、可训练的检测器与强生成器协同进化是提升性能的关键。
4.3 Impact of RAG Components(检索增强生成(RAG)组件的影响)

- 实验设计:通过比较四种检索配置(G−/D−、G+/D−、G−/D+、G+/D+)的性能,分离检索在生成器侧和检测器侧的作用。
- 结果分析:
- 检测器侧检索的显著作用:启用检测器侧检索(G−/D+)时,ROC-AUC 从 70.91% 提升至 80.26%,提升幅度达 9.35%,是单一组件中提升最显著且稳定的。
- 生成器侧检索的作用:仅启用生成器侧检索(G+/D−)时,ROC-AUC 从 68.74% 提升至 74.84%,提升幅度为 6.10%,小于检测器侧检索的提升。
- 双端检索的协同效应:同时启用生成器和检测器侧检索(G+/D+)时,性能提升最大,ROC-AUC 从 72.32% 提升至 86.98%,提升幅度达 14.66%。这表明检索引导的更强对抗性重写,能反过来推动基于证据的检测器学习更鲁棒的验证方法,二者存在互补效应。
4.4 Training Dynamics and Stability(训练动态与稳定性)
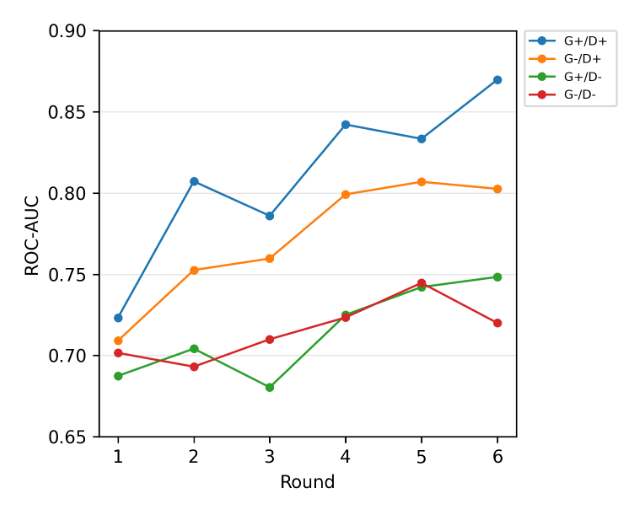
- 实验设计:分析 6 轮训练中各配置模型的 ROC-AUC 变化轨迹。
- 关键观察:
- 双端检索的优越性:完整(G+/D+)配置在所有轮次中始终保持最强的 ROC-AUC 性能,验证了双端检索增强能为协同进化训练提供最有效的信号,最终得到性能最优的检测器。
- 对抗性适应现象:训练过程中观察到性能轻微波动,这可能是因为生成器发现了暂时有效的扰动策略,暂时挑战了检测器当前的决策边界。
- 鲁棒恢复与持续提升:在性能波动后,尤其是启用检索的检测器,在后续轮次中性能能回升并持续提升,表明检测器能将新暴露的攻击模式融入决策规则,最终形成更强的模型。
- 检测器侧证据的关键作用:启用检测器侧检索(D+)的配置相比 D−配置,呈现明显的上升趋势且最终性能更高,说明证据基础对事实验证至关重要 —— 若无外部上下文,检测器易依赖表面线索,性能提升有限。
4.5 Qualitative Analysis of Token Salience(令牌显著性的定性分析)
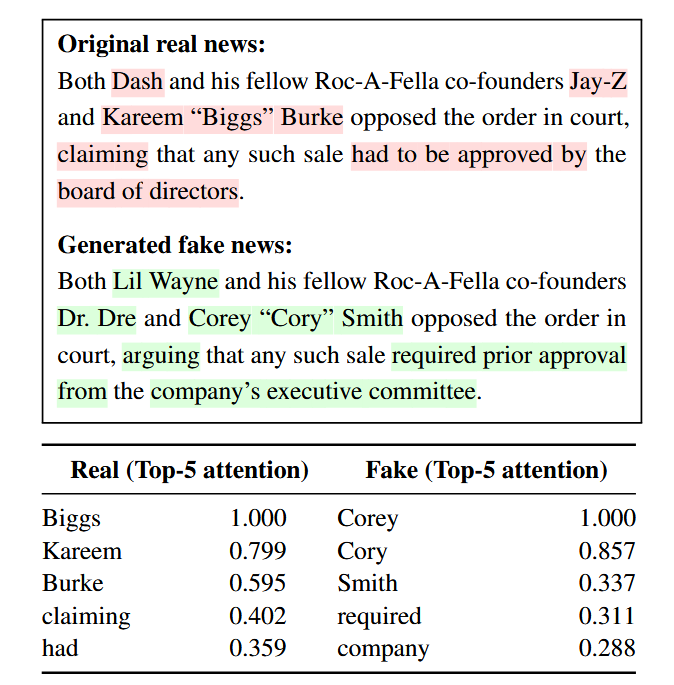
- 实验设计:通过可视化真实新闻与假新闻句子对的令牌级显著性(基于 [CLS] 注意力启发式),分析检测器对可疑片段的关注情况。
- 结果发现:高显著性令牌集中在命名实体和关键主张词上,与生成器引入的事实扰动高度一致,表明检测器能有效关注假新闻中被修改的关键事实部分,验证了基于注意力的可疑令牌识别方法的有效性。
4.6 Analysis & Discussion(分析与讨论)
反馈机制的消融实验
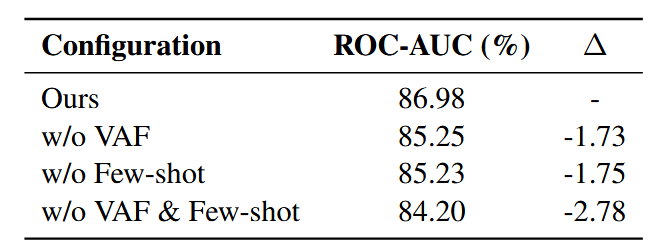
- 实验设计:在新闻数据库检索设置(G+/D+)下,研究 VAF 和少样本示例两种反馈通道的影响,通过移除其中一个或两个组件,观察检测器 ROC-AUC 的变化(结果见表 5)。
- 结果分析:
- 单一反馈组件的作用:移除 VAF 或少样本示例均会导致检测器 ROC-AUC 下降(移除 VAF 下降 1.73%,移除少样本示例下降 1.75%),表明两种反馈通道提供的训练信号具有可比性且各有侧重 ——VAF 通过突出可疑片段和可操作的重写方向提供实例特定指导,鼓励生成器探索更难的规避尝试;少样本示例提供基于示例的指导,减少提示模糊性,稳定重写行为。
- 反馈组件的互补性:同时移除 VAF 和少样本示例时,性能下降幅度最大(2.78%),证明二者具有互补性 —— 少样本示例稳定攻击空间,VAF 引导攻击朝向检测器当前的失效模式,共同为鲁棒检测生成更强的难负样本。
4.7 实验结论
- 检索的关键作用:在假新闻检测中,检测器侧检索对性能提升最为关键,生成器侧检索虽提升较小,但与检测器侧检索结合能产生协同效应,显著提升整体性能。
- 反馈机制的必要性:VAF 和少样本示例作为反馈机制,能为生成器提供有效指导,二者互补,共同推动生成器生成更高质量的对抗性样本,进而辅助检测器优化。
- 协同进化的优势:RADAR 的生成器 - 检测器协同进化框架,结合双端检索增强和有效的反馈机制,相比通用 LLM 基准模型,在对抗性假新闻检测任务中表现出显著的性能优势,能生成更难检测的假新闻并训练出更鲁棒的检测器。
五、论文核心观点 / 贡献
1. 核心观点
- 双端检索增强是鲁棒检测的关键支撑:生成器侧检索提供真实新闻的风格和合理性先验,帮助生成难度高、真实度高的对抗性假新闻;检测器侧检索提供外部证据,支持基于证据的事实验证,二者结合能实现生成器与检测器的有效协同进化,大幅提升检测性能。
- 结构化反馈优于标量奖励:传统标量奖励无法为生成器提供充分指导,而 VAF 作为结构化反馈,包含可疑令牌、检测原因和改进建议,能为生成器提供可解释、可操作的优化信号,避免了策略梯度估计,实现生成器与检测器的稳定协同进化。
- 任务专用的可训练检测器更具优势:相比依赖固定黑箱的提示型 LLM 判断器,基于编码器的可训练轻量级检测器,既能实现对新攻击模式的系统适应,又能降低推理成本(仅需轻量级检索和一次编码器前向传播,无需测试时昂贵的多步 LLM 提示),在对抗性假新闻检测中表现更优。
2. 核心贡献
- 提出双检索框架:设计生成器侧检索(创建真实的对抗性重写)和检测器侧检索(支持鲁棒的基于证据的验证)相结合的双检索框架,为假新闻检测的协同进化提供基础。
- 开发轻量级可训练检测器:提出基于 DeBERTa-v3-base 的轻量级可训练编码器检测器,该检测器在适应性和推理效率上均优于仅基于提示的 LLM 判断器,能有效降低推理成本并实现对新攻击模式的适应。
- 引入口头对抗反馈(VAF):用结构化评论(VAF)替代传统标量奖励,明确解释文章被标记为假新闻的原因及修改方向,无需策略梯度估计即可实现生成器与检测器的稳定协同进化,显著提升检测器的鲁棒性。









 浙公网安备 33010602011771号
浙公网安备 33010602011771号