TREPAT:LLM重写对抗训练
Attacking Misinformation Detection Using Adversarial Examples Generated by Language Models (EMNLP 2025)
使用语言模型生成的对抗样本攻击虚假信息检测
作者:Piotr Przybyła, Euan McGill, Horacio Saggion
代码:https://github.com/piotrmp/trepat
论文地址:https://arxiv.org/abs/2410.20940
1. 研究动机与研究问题
研究动机 (Motivation)
- 现实威胁与鲁棒性评估需求:现代社交媒体平台广泛使用机器学习(ML)分类器作为内容审核系统的一部分,用于检测虚假信息(如宣传、假新闻、谣言等)。恶意行为者可能会通过修改输入文本来绕过这些检测。因此,评估这些模型的鲁棒性(即面对对抗性样本时的稳定性)至关重要。
- 现有对抗攻击方法的局限性:
- 查询次数过多:现有的基于单词替换(Word-replacement)的方法(如 BERT-ATTACK)通常需要向受害者模型发送数千次查询才能生成一个对抗样本。在现实世界中,API通常有速率限制(如每天限制50次),这种攻击会被拦截。
- 语义保持差:词替换策略往往导致句子含义改变或语法不通顺,使得生成的对抗样本在人工审核下无法通过,或者失去了原文本的误导意图。
- LLM 的潜力:大型语言模型(LLMs)在文本重写、风格迁移和释义生成方面表现出色。利用 LLM 的重写能力,可能在有限查询次数下生成语义保留更好、更自然的对抗样本。
研究问题 (Research Questions)
- 可行性:能否利用生成式 LLM 构建一种有效的方法,生成用于攻击虚假信息检测系统的对抗样本(Adversarial Examples, AEs)?
- 约束适应性:在严格限制查询次数(模拟真实 API 限制,如 50 次查询)的场景下,该方法是否优于现有的基线方法?
- 质量评估:LLM 生成的对抗样本在语义保留(Meaning Preservation)和语言自然度(Language Naturalness)方面是否优于传统的词替换方法?
2. Method
论文提出的核心方法名为 TREPAT (Tracing REcursive Paraphrasing for Adversarial examples from Transformers)。该方法不直接使用 LLM 生成最终结果,而是利用 LLM 生成候选重写,再将其拆解为原子操作进行搜索。
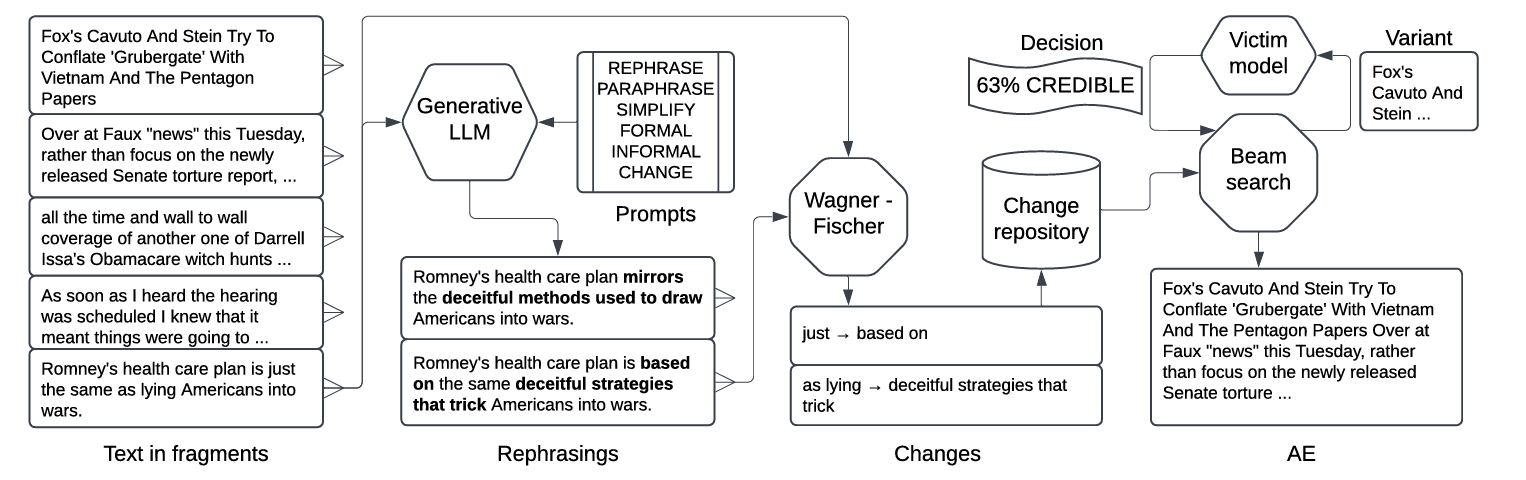
2.1 分割 (Splitting)

- 问题:LLMs(尤其是较小的模型)在重写长文本时往往会丢失重要信息或遗漏部分句子。
- 策略:将输入文本分割成较小的片段(Fragments)进行处理。
- 分割规则:
- 输入类型分割:针对事实核查任务,将“证据”和“声明”分开处理。
- 换行符分割:按换行符切分。
- 句子分割:使用 LAMBO 工具将文本切分为句子。
- 短语边界分割:利用破折号、引号、逗号、冒号进行切分,但限制切分后的片段长度至少为 60个字符(过短的片段缺乏上下文,导致 LLM 重写质量下降)。
- 位置保持:记录每个片段的偏移量(Offset),以便后续将其重组回完整文本。
2.2 重写 (Rephrasing)
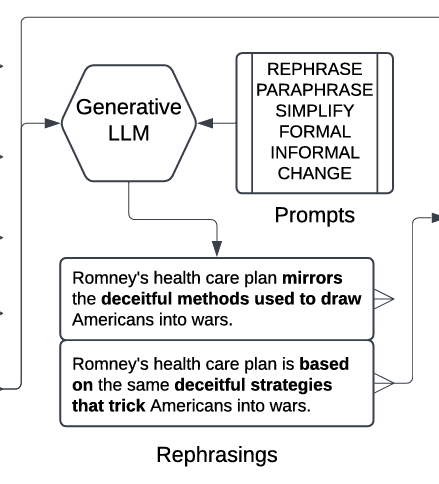
- 目标:改变文本的表层形式,但保留其核心语义。
- 工具:使用预训练的指令微调 LLM(实验中比较了 Llama 3、Gemma 2、OLMo 等)。
- 提示词策略 (Prompts):设计了6种不同意图的提示词来引导 LLM:
- REPHRASE:基础重写。
- PARAPHRASE:强调语义保留的释义。
- SIMPLIFY:简化文本(受文本简化任务启发)。
- FORMAL:改写为更正式的风格。
- INFORMAL:改写为非正式风格。
- CHANGE:明确要求做出改变(较为激进)。
- 输出:LLM 对每个片段生成重写后的文本。
2.3 获取变更 (Obtaining Changes)
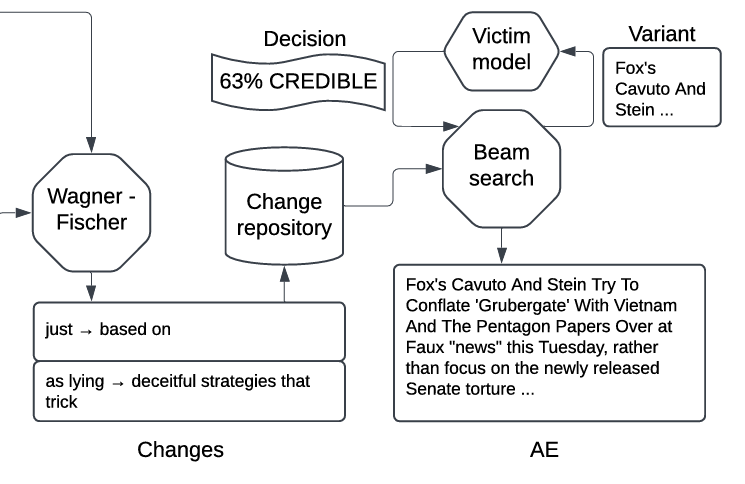
- 核心思想:LLM 的重写通常包含多处修改。直接使用 LLM 的输出可能改动过大。作者希望将重写分解为独立的、细粒度的“原子变更”。
- 算法:
- Token化:将原片段和 LLM 重写片段转换为 Token 序列。
- 编辑距离计算:使用 Wagner-Fischer 算法计算编辑距离,识别出 ADD(添加)、DELETE(删除)、REPLACE(替换)操作。
- 聚合:将相邻的操作聚合为“多 Token 变更”(Multi-token changes),形成连续的替换序列(例如:
rise of->surge in)。
以下是一个例子:
INPUT: The recent rise of food prices is re sulting in widespread discontent.
LLM OUTPUT: The recent surge in food prices has caused widespread unease.
共有三处变化
• rise of-> surge in
• is resulting in-> has caused
• discontent-> unease
- 过滤机制:
- 丢弃纯 ADD 或 pure DELETE 操作(通常会破坏语义)。
- 丢弃修改量超过片段 2/3 或全文 1/3 的操作(防止语义漂移过大)。
2.4 应用变更 (Applying Changes)
- 流程:将所有片段生成的所有“原子变更”收集到一个库中,通过搜索算法应用到原始文本上。
- 搜索算法:束搜索 (Beam Search)。
- 目标:翻转受害者模型(Victim Classifier)的预测结果(即找到对抗样本)。
- 引导指标:受害者模型返回的置信度分数(Credibility Score)。优先选择能最大程度降低原始类别概率的变更。
- 参数:Beam Size \(k=5\)(为了减少查询次数)。
- 迭代过程:每次应用一个最有希望的变更,查询受害者模型。如果预测翻转,则成功;否则继续在当前基础上应用下一个变更,直到达到查询次数限制。
3. Experiment
3.1 实验设置
数据集 (Datasets)
使用 BODEGA 框架中的四个虚假信息检测任务,涵盖不同长度和类型:
- PR (Propaganda Recognition):宣传识别(句子级,短文本)。
- FC (Fact-Checking):事实核查(声明+证据,中等长度)。
- RD (Rumour Detection):谣言检测(Twitter 帖子串,长文本)。
- HN (Hyperpartisan News):极端党派新闻检测(新闻文章,非常长的文本)。
受害者模型 (Victim Models)
针对上述任务训练了四种架构的分类器作为攻击对象:
- BiLSTM
- BERT (Fine-tuned)
- GEMMA-2B (LLM-based classifier)
- GEMMA-7B (LLM-based classifier)
基线方法 (Baselines)
- BERT-ATTACK (Li et al., 2020):经典的基于词替换的攻击方法,在原始 BODEGA 评估中表现最好。
- F-BERT-ATTACK (Filtered BERT-ATTACK):作者修改版。原版第一步需大量查询来确定脆弱词,修改版改为随机选择词以适应“有限查询”场景。
- BeamAttack (Guzman Piedrahita et al., 2024):InCrediblAE 比赛中的优秀方案,基于字符级修改和搜索。
- TREPAT-simple :TREPAT 的简化版本,直接使用由大语言模型生成的改写,不将其拆分并通过束搜索
评估指标
- Confusion (混淆率):攻击成功率。
- Semantic Score:语义相似度 (使用 BLEURT)。
- Character Score:字符级相似度 (Levenshtein distance)。
- BODEGA Score:综合指标 = Confusion × Semantic × Character。
- Queries:消耗的查询次数。
限制条件
- 查询限制 (Query Limit):默认为 50次,用于模拟真实社交媒体API限制。实验4中测试了 10, 50, 100, 250 次。
3.2 实验内容与结果 (Results)
实验 1: LLM 选择 (LLM Selection)
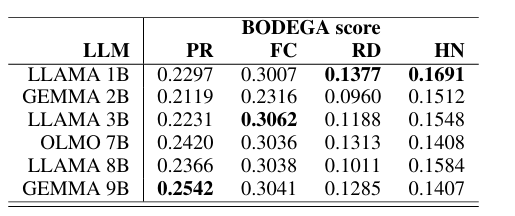
- 内容:比较 Llama (1B, 3B, 8B), Gemma (2B, 9B), OLMo (7B) 作为重写生成器的效果。
- 结果:不同任务中最佳模型不同,差异不大。
- 决策:最终选择 OLMo-7B,因为它完全开源透明,且性能稳定。
实验 2: 提示词策略 (Prompt Strategy)
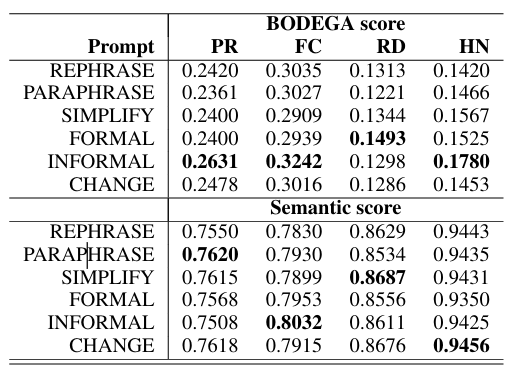
- 内容:比较 6 种提示词(REPHRASE, SIMPLIFY 等)的效果。
- 结果:
- 风格迁移有效:将文本风格向原风格相反的方向转换效果最好。
- PR/HN (新闻类) -> 使用 INFORMAL 提示词效果最好。
- RD (社交媒体类) -> 使用 FORMAL 提示词效果最好。
- FC (百科类) -> 使用 INFORMAL 提示词。
- 结论:风格转换能有效生成对抗样本且保持语义。
实验 3: 主要评估 (Main Evaluation)
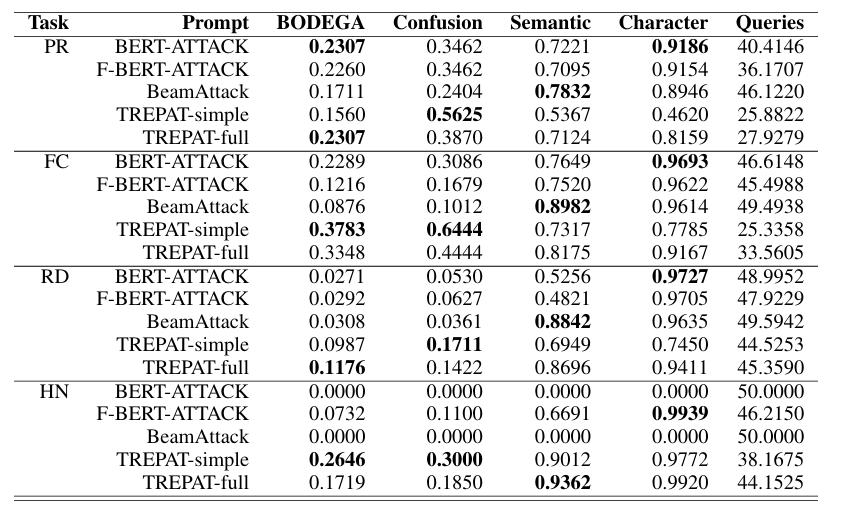
- 内容:对比 TREPAT(及其变体 TREPAT-simple 和 TREPAT-full)与基线方法在 50 次查询限制下的表现。
- 结果 (以 BERT 受害者模型为例):
- TREPAT-simple (直接使用整句重写,不拆解):攻击成功率高,但语义保留稍差。
- TREPAT-full (拆解为原子操作+Beam Search):在大多数任务中取得了最高的 BODEGA Score。
- PR 任务(短文本):BERT-ATTACK 和 TREPAT 表现相当。
- RD / HN 任务(长文本):TREPAT 表现显著优于 BERT-ATTACK。
- 原因:BERT-ATTACK 在长文本上搜索空间太大,50 次查询还没找到关键脆弱词就耗尽了;TREPAT 通过 LLM 直接生成高质量候选,效率更高。
实验 4: 查询次数限制的影响
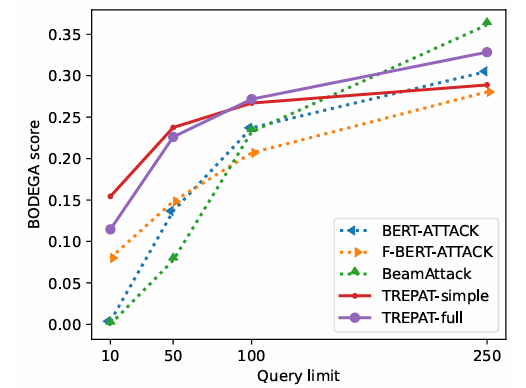
- 内容:测试查询限制从 10 到 250 次对性能的影响。
- 结果:
- 在 10-100 次(现实限制范围)内,TREPAT 明显优于基线。
- 只有当查询次数放宽到 250 次以上时,针对无限查询设计的 BeamAttack 等方法才开始展现优势。
5.2 人工评估 (Manual Evaluation)
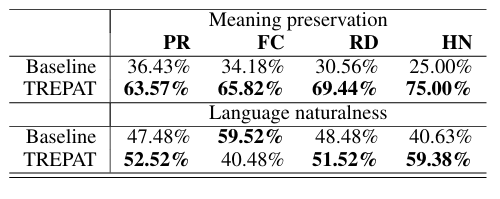
- 设置:两位语言学家对生成的对抗样本进行盲测。
- 指标:语义保留 (Meaning Preservation)、语言自然度 (Language Naturalness)。
- 结果:
- 语义保留:TREPAT 显著优于基线(例如在 HN 任务中 75% vs 25%)。
- 自然度:TREPAT 生成的文本更流畅、更符合语法,尤其是在事实核查(FC)任务中,BERT-ATTACK 经常生成不通顺的句子。
5.3 语言学分析
- TREPAT 的策略:使用了更高级的修改策略,如:
- 短语替换:
verified facts->confirmed data(语义漂白)。 - 风格转换:增加口语化表达或正式表达。
- 句法调整:而不只是简单的同义词替换。
- 短语替换:
- 基线的问题:BERT-ATTACK 经常破坏专有名词(如将报纸名
Guardian改为forward),导致句子不仅语法错误,而且丢失关键信息。

结论 (Conclusions)
- SOTA 表现:TREPAT 在有限查询次数的 BODEGA 基准测试中建立了新的 State-Of-The-Art (SOTA)。
- 方法创新:首次提出将 LLM 的重写拆解为“编辑操作”并结合搜索算法,有效平衡了语义保留和攻击成功率。
- 长文本优势:在长文本(如新闻文章)场景下,该方法远优于传统的词替换方法。
- 模型鲁棒性:即便是基于 LLM 的大型分类器(如 GEMMA-7B),在面对这种攻击时也表现出脆弱性,并未比 BERT 更鲁棒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号