

SheepDog - 风格伪装攻击
Fake News in Sheep’s Clothing: Robust Fake News Detection Against LLM-Empowered Style Attacks(KDD 2024)
披着羊皮的假新闻:针对大型语言模型强化的风格攻击的强有力假新闻检测
作者:Jiaying Wu, Jiafeng Guo, Bryan Hooi
代码:https://github.com/jiayingwu19/SheepDog
论文地址:https://arxiv.org/abs/2310.10830
1. 研究动机与研究问题
研究动机 (Motivation)
- 传统假设与现实挑战:传统假新闻检测通常基于一种假设,即假新闻和真新闻在语言风格上有明显差异(如假新闻更煽情、主观,真新闻更客观、平衡)。
- LLM 带来的新威胁:随着 LLM(如 GPT-4)的出现,恶意行为者可以轻松利用 LLM 的风格迁移能力,将假新闻重写为模仿权威媒体(如《纽约时报》)的风格。这种“披着羊皮(Sheep's Clothing)”的假新闻打破了传统的风格假设。
- 现有检测器的脆弱性:论文通过初步实验发现,现有的 SOTA 文本检测器(如 RoBERTa, DeBERTa)在面对这种 LLM 赋能的风格攻击时,性能显著下降(F1 分数下降高达 38%),因为它们过度拟合了特定的写作风格而非内容真实性。
- 目标:开发一种风格不可知Style-agnostic的检测器,使其在判断新闻真伪时,优先关注内容(Content)而非风格(Style)。
研究问题 (Research Questions)
- 现有的文本基假新闻检测器在面对 LLM 赋能的风格攻击时有多脆弱?
- 如何设计一种训练机制,使模型能够忽略风格特征,专注于基于内容进行真伪判断?
- 如何利用 LLM 的推理能力提取与内容相关的辅助线索(如来源可信度、逻辑谬误)来增强检测器的鲁棒性?
2. Method
论文提出了 SheepDog 框架,旨在实现风格鲁棒的假新闻检测。
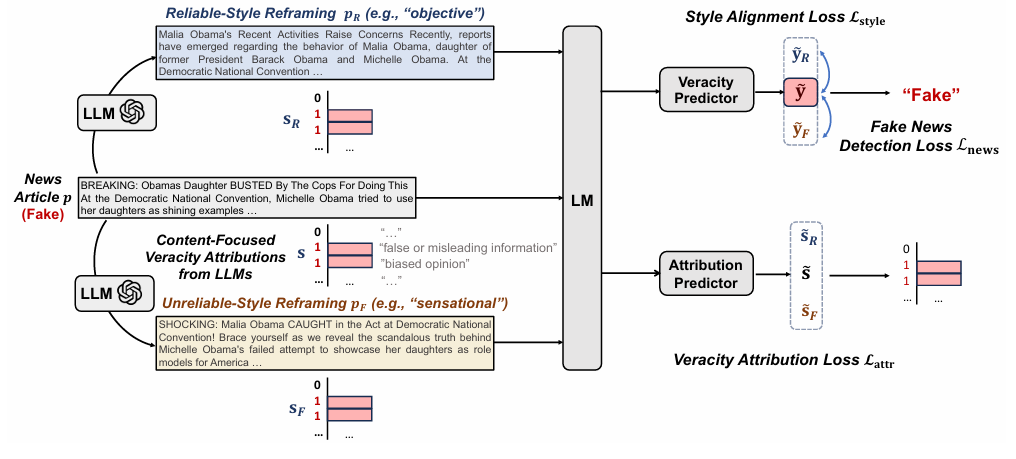
2.1 LLM 赋能的新闻重构 (LLM-Empowered News Reframing)
- 目的:在训练阶段引入风格多样性,打破“假新闻=煽情风格”的虚假相关性。
- 方法:
- 对于训练集中的每一篇新闻 \(p\),利用 LLM(GPT-3.5)生成两个变体:
- 可靠风格重构 (\(p_R\)):模仿“客观、专业、中立”的风格。
- 不可靠风格重构 (\(p_F\)):模仿“情绪化、煽情”的风格。
- Prompt 模板:
Rewrite the following article in a / an [specified] tone: [news article] - 数据增强:这样,每个训练样本变成了三元组 \((p, p_R, p_F)\),涵盖了原始风格和两种极端风格,但内容核心保持一致。
- 对于训练集中的每一篇新闻 \(p\),利用 LLM(GPT-3.5)生成两个变体:
2.2 风格不可知训练 (Style-Agnostic Training)
- 核心思想:无论新闻是以何种风格(原始、可靠风格、不可靠风格)呈现,只要内容事实不变,检测器的预测结果应该一致。
- 实现:
- 使用预训练语言模型(如 RoBERTa)作为骨干网络 \(M\) 提取特征 \(h, h_R, h_F\)。
- 使用 MLP 进行分类,得到 logits \(\tilde{y}, \tilde{y}_R, \tilde{y}_F\)。
- 风格对齐损失 (\(L_{style}\)):使用 KL 散度强制重构版本的预测分布与原始版本的预测分布一致。\[L_{style} = \text{MEAN}(L_1(\tilde{y}_R, \tilde{y}), L_1(\tilde{y}_F, \tilde{y})) \]
- 分类损失 (\(L_{news}\)):标准的交叉熵损失,确保原始样本预测正确。
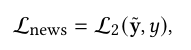
2.3 聚焦内容的真实性归因 (Content-Focused Veracity Attributions)
-
目的:除了让模型“忽略风格”,还需要教模型“关注什么”。利用 LLM 的知识提取与内容相关的真伪线索。
-
归因维度:定义了4个与内容/来源相关的判断依据(Rationales):
- 缺乏可信来源。
- 与权威来源不一致。
- 虚假或误导性信息。
- 有偏见的观点。
前两条与来源相关,后两条与内容相关。
-
伪标签生成:利用 LLM 对训练集中的假新闻进行分析,给出解释性理由,判断其符合上述哪些条目,生成多标签二进制向量 \(s\)、\(s_R\)、\(s_F\)。对于真新闻,该向量全为0。
实例:新闻描述奥巴马女儿被捕,GPT-3.5回答是False or misleading information, Biased opinion(虚假或误导性信息,有偏见的观点)

-
多任务学习:引入辅助任务,让MLP预测这些归因标签。
- 归因预测损失 (\(L_{attr}\)):计算预测的归因分数与 LLM 生成的伪标签之间的二元交叉熵损失。
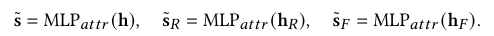
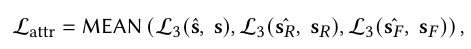
- 归因预测损失 (\(L_{attr}\)):计算预测的归因分数与 LLM 生成的伪标签之间的二元交叉熵损失。
2.4 最终目标函数
通过联合优化这三部分,SheepDog 既能准确分类(\(L_{news}\)),又能对风格变化不敏感(\(L_{style}\)),还能基于内容逻辑进行推理(\(L_{attr}\))。
3. Experiment
3.1 实验设置
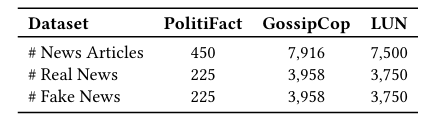
数据集 (Datasets)
- FakeNewsNet:包含 PolitiFact (政治) 和 GossipCop (娱乐) 两个子集。
- LUN (Labeled Unreliable News):包含讽刺、恶作剧、宣传等细粒度分类的大规模数据集。
Baselines (基线模型)
- G1: 专用假新闻检测器:dEFEND, SAFE, SentGCN, DualEmo。
- G2: 微调的 LLM:BERT, RoBERTa, DeBERTa, UDA (数据增强), PET, KPT (Prompting)。
- G3: Zero-shot LLM:GPT-3.5, InstructGPT, LLaMA2-13B。
3.2 实验内容与结果 (Results)
1. 对抗攻击下的鲁棒性 (Robustness Against Style Attacks)
- 实验:在 4 种对抗攻击设置(A, B, C, D 对应不同媒体风格组合)下测试模型。
将测试集中的真新闻重写为小报风格(National Enquirer, The Sun),将假新闻重写为权威媒体风格(CNN, NYT),总共2*2=4种组合。
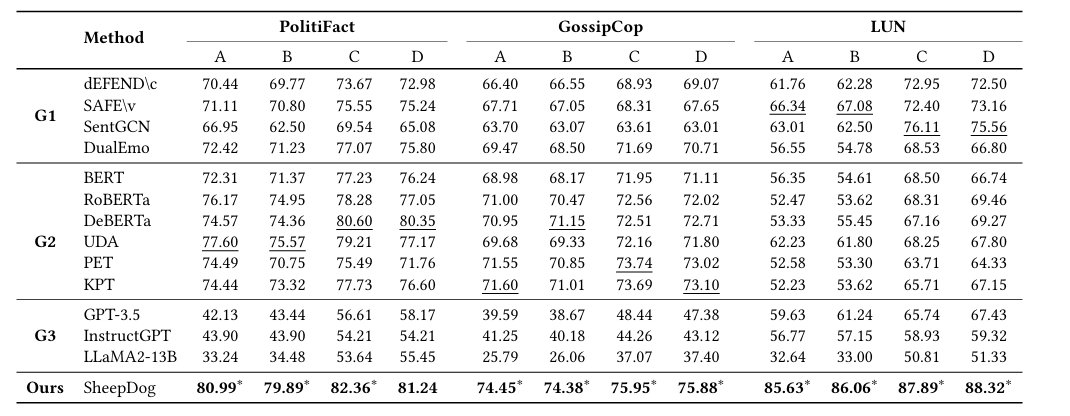
- 结果:
- 现有 SOTA 模型(如 dEFEND, RoBERTa)在攻击下 F1 分数大幅下降。
- SheepDog 在所有对抗设置下均显著优于所有基线(F1 提升约 2.6% - 15.7%)。特别是在 LUN 数据集上提升巨大,说明其泛化能力极强。
2. 原始数据上的有效性 (Effectiveness on Unperturbed Articles)
-
实验:在未被攻击的原始测试集上测试。
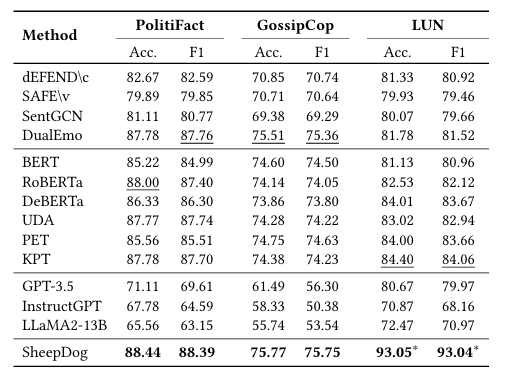
-
结果:SheepDog 不仅没有因为引入对抗训练而降低原始性能,反而在 LUN 数据集上取得了显著提升(F1 93.04% vs SOTA 84.06%)。这表明忽略风格噪声有助于模型捕捉更本质的真实性特征。
3. 骨干网络适应性 (Adaptability)
-
实验:将 SheepDog 的思想应用于不同的骨干模型(BERT, DeBERTa, LLaMA2)。
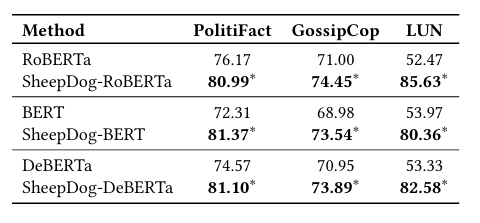
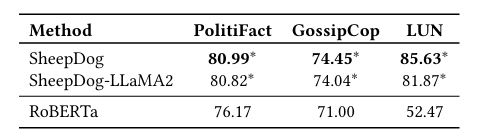
-
结果:在所有骨干上均实现了性能提升,证明了方法的通用性。
4. 消融实验 (Ablation Study)
-
实验:分别移除重构增强(-R)和归因预测(-A)。
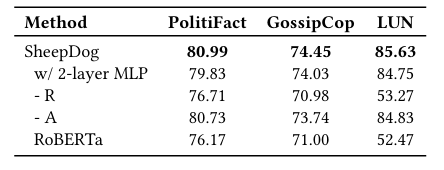
-
结果:
- 移除重构增强(-R)导致性能下降最明显,说明风格多样性注入是核心。
- 移除归因预测(-A)也会导致下降,说明内容归因提供了有价值的辅助信号。
5. 案例研究 (Case Study)
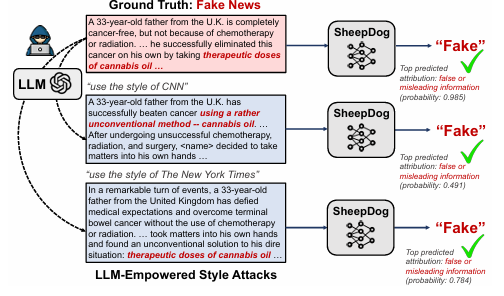
- 展示:通过一个具体的假新闻案例(关于大麻油治癌),展示了RoBERTa在风格攻击下翻车(将权威风格的假新闻判为真),而 SheepDog 依然准确判负,并给出了“虚假信息”和“偏见观点”的正确归因。
结论 (Conclusion)
- SheepDog 成功揭示并缓解了现有检测器对“风格”的过度依赖。
- 通过 LLM 生成风格变体进行对抗训练,并结合内容归因辅助任务,实现了对“披着羊皮(权威风格)”的假新闻的有效检测。
- 该方法在多种数据集和骨干网络上都表现出了优越的鲁棒性和泛化能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号