超分辨综述
常用数据集
BSDS300、BSDS500、DIV2K、General-100、L20、Manage109、OutdoorScene、PIRM、Set5、Set14、T91、Urban100
图像评价
- PSNR:逐一像素比较
- SSIM:注重整体比较,从对比度、亮度、结构独立比较
- MOS:平均主观意见分
操作通道
- RGB
- YCBCr
有监督学习的超分辨方法
Pre-upsampling SR
-
原因:直接学习低分辨率图像和高分辨图像之间的映射比较困难
-
模型:SRCNN、VDSR、DRRN
-
创新:首次使用
pre-upsampling SR操作,先对LR做上采样,使得上采样后的图像尺寸与HR相同,然后再学习他们的映射关系,极大降低学习难度 -
缺点:预先上采样会带来噪声放大和模糊,计算在高维度空间进行,要更多的时间和空间成本
-
结构:

Post-upsampling SR
-
原因:在低维度进行计算可以提高计算效率,所以先在低维度进行计算,在网络的末端进行上采样操作
-
模型:FSRCNN、ESPCN
-
创新:由于具有巨大计算成本的特征提取过程仅发生在低维空间中,大大降低了计算量和空间复杂度,该框架也已成为最主流的框架之一
-
缺点:在超分比例因子Scale较大的情况下,有较大的学习难度
-
结构:

Progressive upsampling SR 渐进式上采样超分辨
-
原因:在放大因子较大时,使用上述b的方法有很大困难;且对于不同的放大因子,需要分别训练一个单独的SR网络模型,无法满足对多尺度SR的需求
-
模型:LapSRN
-
创新:基于级联的CNN结构,逐步重建高分辨率图像。把困难的任务分解,降低学习难度。如要进行4倍SR,则先进行2倍SR,在X2_SR的基础上进行4倍SR
-
缺点:模型设计复杂、训练稳定性差、要更多的建模指导和先进的训练策略
-
结构:

Iterative up-and-down sampling SR 上下采样迭代超分辨
-
原因:为了更好地捕捉LR-HR直接的相互依赖关系,引入了反投影
-
模型:DBPN
-
创新:交替连接上采样层和下采样层,并使用所有中间过程来重建最终的HR结果,可以很好地挖掘LR-HR图像对之间的深层关系,从而提高更好的重建效果
-
缺点:反投影设计标准不清楚,有很大的探索潜力
-
结构:

上采样方法
-
-
最近邻插值法:每个待插值的位置选择最相邻的像素值,而不考虑其他像素,这种策略很直觉,它的优势是:处理速度快。但缺点是:生成图片质量低、块状化。
-
双线性插值法
-
双三次插值法
-
-
基于学习的上采样:
- 转置卷积
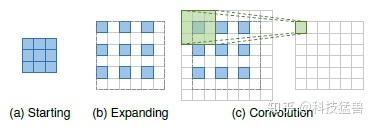
- 亚像素卷积
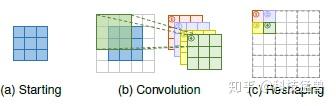
网络设计
残差学习
| 全局残差学习 | 输入图像与目标图像高度相关,因此可以只学习它们之间的残差,这就是全局残差学习 | (a) 可以避免学习从一个完整图像到另一个图像的复杂变换,而只需要学习一个残差图来恢复丢失的高频细节 (b) 由于大部分区域的残差接近于零,模型的复杂度和学习难度大大降低 |
|---|---|---|
| 局部残差学习 | 类似于ResNet中的残差学习,shortcut连接可以用于缓解网络深度不断增加所带来的模型退化问题,降低了训练难度 |  如 SRGAN、RCAN等网络模型 如 SRGAN、RCAN等网络模型 |
递归学习
-
原因:为了不引入过多参数的情况下学习到更高级的特征,以递归方式多次应用相同的模块来实现超分辨任务
-
缺点:无法避免较高的计算成本,存在梯度消失或爆炸问题,常与残差学习和多重监督学习结合
-
模型:DRCN、MEMNet、CARN、DSRN
-
结构:

多路径学习
- 概念:指通过多条路径传递特征,每条路径执行不同的操作,将他们的操作结果融合以提供更好的建模能力
| 全局多路径学习 | 利用多条路径来提取图像不同方面的特征,这些路径在传播过程中可以相互交叉,从而大大提高学习能力 |  |
LapSRN、DSPN |
|---|---|---|---|
| 局部多路径学习 | 对输入进行不同路径的特征提取后进行融合 |  |
CSNLN |
| 特定尺度的多路径学习 | 不同尺度的SR模型需要经过相似的特征提取,所以它们共享模型用于特征提取的网络层,并分别在网络的开始和结束处附加特定比例的预处理结构和上采样结构。训练期间仅启用和更新与选定比例相对应的模块 |  |
MDSR、CARN、ProSR |
稠密连接
-
原理:对于稠密块体中的每一层,将所有前一层的特征图作为输入,并将其自身的特征图作为输入传递到所有后续层
-
优点:稠密连接不仅有助于减轻梯度消失、增强信号传播和鼓励特征重用,而且还通过采用小增长率(即密集块中的信道数)和在连接所有输入特征映射后压缩通道数来显著减小模型尺寸。
-
模型:
-
结构:

注意力机制
- 原理:考虑到不同通道之间特征的相互依赖关系来提高网络的学习能力
- 模型:
高级卷积Advanced Convolution
- 扩张卷积(空洞卷积)Dilated Convolution:增大感受野,有助于生成逼真的细节
- 分组卷积Group Convolution:可以在little performance loss的情况下减少大量的参数和运算,而CARN-M在性能损失很小的情况下将参数数量减少了5倍,运算减少了4倍。
- 深度分离卷积
金字塔池Pyramid Pooling
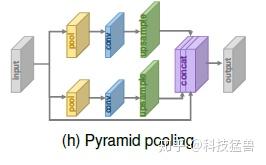
受空间金字塔池层的激励,提出了金字塔池模块,以更好地利用全局和局部上下文信息。
Pyramid的思路就是把不同 size 的 feature concat 在一起。对于尺寸是 h×w×c的feature map,每个channel被划分成M×M块并通过GAP全局池化,生成M×M×c的结果。再通过 1×1 卷积把输出压缩为single channel。之后,再经过双线性插值把结果进行上采样到原来feature map的维度。当 M 变化时,模块结合全局和局部的上下文信息以提升性能。
损失函数
像素级损失pixel Loss

内容损失Content Loss
希望生成的图片从视觉上看更像是真实的图片
衡量不同图像通过预训练的模型后得到的特征图之间的差异,计算图像之间的感知相似性

其中,φ是利用Vgg、ResNet等预先训练好的图像分类网络
纹理损失Texture Loss
希望重构的图片与原图有相同的风格
考虑到重建图像应具有与目标图像相同的风格(如颜色、纹理、对比度),将图像纹理视为不同特征通道之间的相关性,将图像的纹理视为不同特征通道之间的相关性(利用矩阵点乘来表示相关性)

最终损失函数是要求相关性相同:

需要一定的调参经验,patch太小会造成纹理部分重影,太大会整张图像重影
对抗损失Adversarial Loss
希望重构的图片与原图有相同的风格
在生成对抗网络中,判别器被用来判断当前输入信号的真伪,生成器则尽可能产生“真”的信号,以骗过判别器

循环一致性损失Cycle Consistency Loss
受到启发,将HR图像通过另一个CNN网络缩小为I',然后跟要处理的小图片做相似性度量

总变化损失Total Variation Loss
希望生成的图片更平滑
用于抑制噪声,提升图像的空间平滑性

基于先验的损失Prior-Based Loss
聚焦于人脸图像的超分辨,引入人脸比对网络FAN来约束从原始和生成的图像中检测到的人脸的一致性,经常要和多个Loss组合使用,需要一定的调参经验
本文学习参考:2020 图像超分最新综述及上采样技术一览
Write by Gqq

 浙公网安备 33010602011771号
浙公网安备 33010602011771号