
Task-Local Recovery
Motivation
In Flink’s checkpointing, each task produces a snapshot of its state that is then written to a distributed store. Each task acknowledges a successful write of the state to the job manager by sending a handle that describes the location of the state in the distributed store. The job manager, in turn, collects the handles from all tasks and bundles them into a checkpoint object.
In case of recovery, the job manager opens the latest checkpoint object and sends the handles back to the corresponding tasks, which can then restore their state from the distributed storage. Using a distributed storage to store state has two important advantages. First, the storage is fault tolerant and second, all state in the distributed store is accessible to all nodes and can be easily redistributed (e.g. for rescaling).
However, using a remote distributed store has also one big disadvantage: all tasks must read their state from a remote location, over the network. In many scenarios, recovery could reschedule failed tasks to the same task manager as in the previous run (of course there are exceptions like machine failures), but we still have to read remote state. This can result in long recovery time for large states, even if there was only a small failure on a single machine.
Approach
Task-local state recovery targets exactly this problem of long recovery time and the main idea is the following: for every checkpoint, each task does not only write task states to the distributed storage, but also keep a secondary copy of the state snapshot in a storage that is local to the task (e.g. on local disk or in memory). Notice that the primary store for snapshots must still be the distributed store, because local storage does not ensure durability under node failures and also does not provide access for other nodes to redistribute state, this functionality still requires the primary copy.
However, for each task that can be rescheduled to the previous location for recovery, we can restore state from the secondary, local copy and avoid the costs of reading the state remotely. Given that many failures are not node failures and node failures typically only affect one or very few nodes at a time, it is very likely that in a recovery most tasks can return to their previous location and find their local state intact. This is what makes local recovery effective in reducing recovery time.
Please note that this can come at some additional costs per checkpoint for creating and storing the secondary local state copy, depending on the chosen state backend and checkpointing strategy. For example, in most cases the implementation will simply duplicate the writes to the distributed store to a local file.
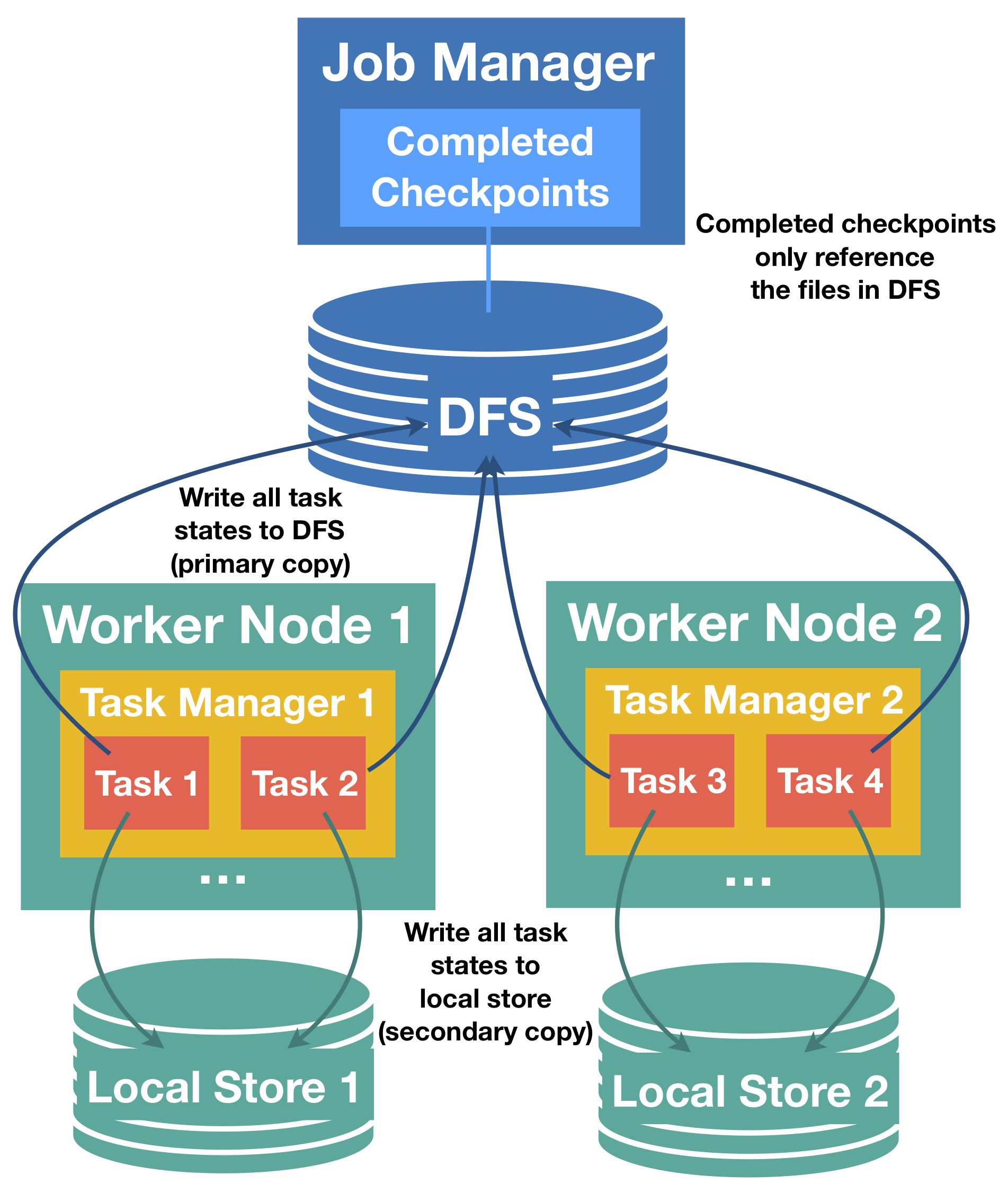
Relationship of primary (distributed store) and secondary (task-local) state snapshots
Task-local state is always considered a secondary copy, the ground truth of the checkpoint state is the primary copy in the distributed store. This has implications for problems with local state during checkpointing and recovery:
-
For checkpointing, the primary copy must be successful and a failure to produce the secondary, local copy will not fail the checkpoint. A checkpoint will fail if the primary copy could not be created, even if the secondary copy was successfully created.
-
Only the primary copy is acknowledged and managed by the job manager, secondary copies are owned by task managers and their life cycles can be independent from their primary copies. For example, it is possible to retain a history of the 3 latest checkpoints as primary copies and only keep the task-local state of the latest checkpoint.
-
For recovery, Flink will always attempt to restore from task-local state first, if a matching secondary copy is available. If any problem occurs during the recovery from the secondary copy, Flink will transparently retry to recover the task from the primary copy. Recovery only fails, if primary and the (optional) secondary copy failed. In this case, depending on the configuration Flink could still fall back to an older checkpoint.
-
It is possible that the task-local copy contains only parts of the full task state (e.g. exception while writing one local file). In this case, Flink will first try to recover local parts locally, non-local state is restored from the primary copy. Primary state must always be complete and is a superset of the task-local state.
-
Task-local state can have a different format than the primary state, they are not required to be byte identical. For example, it could be even possible that the task-local state is an in-memory consisting of heap objects, and not stored in any files.
-
If a task manager is lost, the local state from all its task is lost.
Configuring task-local recovery
Task-local recovery is deactivated by default and can be activated through Flink’s configuration with the key state.backend.local-recovery as specified in CheckpointingOptions.LOCAL_RECOVERY. The value for this setting can either be true to enable or false (default) to disable local recovery.
Details on task-local recovery for different state backends
Limitation: Currently, task-local recovery only covers keyed state backends. Keyed state is typically by far the largest part of the state. In the near future, we will also cover operator state and timers.
The following state backends can support task-local recovery.
-
FsStateBackend: task-local recovery is supported for keyed state. The implementation will duplicate the state to a local file. This can introduce additional write costs and occupy local disk space. In the future, we might also offer an implementation that keeps task-local state in memory.
-
RocksDBStateBackend: task-local recovery is supported for keyed state. For full checkpoints, state is duplicated to a local file. This can introduce additional write costs and occupy local disk space. For incremental snapshots, the local state is based on RocksDB’s native checkpointing mechanism. This mechanism is also used as the first step to create the primary copy, which means that in this case no additional cost is introduced for creating the secondary copy. We simply keep the native checkpoint directory around instead of deleting it after uploading to the distributed store. This local copy can share active files with the working directory of RocksDB (via hard links), so for active files also no additional disk space is consumed for task-local recovery with incremental snapshots. Using hard links also means that the RocksDB directories must be on the same physical device as all the configure local recovery directories that can be used to store local state, or else establishing hard links can fail (see FLINK-10954). Currently, this also prevents using local recovery when RocksDB directories are configured to be located on more than one physical device.
Allocation-preserving scheduling
Task-local recovery assumes allocation-preserving task scheduling under failures, which works as follows. Each task remembers its previous allocation and requests the exact same slot to restart in recovery. If this slot is not available, the task will request a new, fresh slot from the resource manager. This way, if a task manager is no longer available, a task that cannot return to its previous location will not drive other recovering tasks out of their previous slots. Our reasoning is that the previous slot can only disappear when a task manager is no longer available, and in this case some tasks have to request a new slot anyways. With our scheduling strategy we give the maximum number of tasks a chance to recover from their local state and avoid the cascading effect of tasks stealing their previous slots from one another.
ref:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号