redis介绍和安装
# 1 redis 什么
-数据库就是个存数据的地方:只是不同数据库数据组织,存放形式不一样
-mysql 关系型数据库(oracle,sqlserver,postgrasql)
-非关系型数据(no sql):redis,mongodb,clickhouse,infludb,elasticsearch,hadoop。。。
-没有sql:没有sql语句
-not olny sql 不仅仅是sql
-redis:一款纯内存存储的非关系型数据库(数据都在内存),速度非常快
# 2 redis特点:https://www.cnblogs.com/liuqingzheng/articles/9833534.html
-redis是一个key-value存储系统
-数据类型丰富,支持5大数据类型:字符串,列表,hash(字典),集合,有序集合
-纯内存操作
-可以持久化:能都把内存数据,保存到硬盘上永久存储
# 3 redis为什么这快
-1 纯内存,减少io
-2 使用了 io多路复用的 epoll 网络模型
-3 数据操作是单线程,避免了线程间切换
-多个客户端同时操作,不会存在并发安全问题
# 4 安装
-redis:最新是7, 公司里5,6比较多
-redis:开源软件,免费的,他们不支持win
-epoll模型不支持win
-微软官方:基于源码修改---》编译成可执行文件
-第三方:https://github.com/tporadowski/redis/releases/
-win:下载安装包,一路下一步
-安装目录在环境变量中:任意路径敲 redis-server redis-cli 都能找到
-把redis做成了服务,以后通过服务启动即可
-mac:官网下载,解压即可
-win,mac:两个可执行文件:
redis-server :等同于 mysqld
reidis-cli :等同于mysql
# 5 启动,连接
# 5.1 启动方式
-使用服务启动
redis-server redis.windows-service.conf
-使用命令启动
redis-server
# 5.2 连接
redis-cli
redis-cli -h 地址 -p 端口(默认端口6379)
# 5.3 图形化客户端(Navicate)
-resp:后来收费了
-连接上发现有16个库
# 6 放值
使用resp放入值
# 7 取值
cmd中 连接:get key
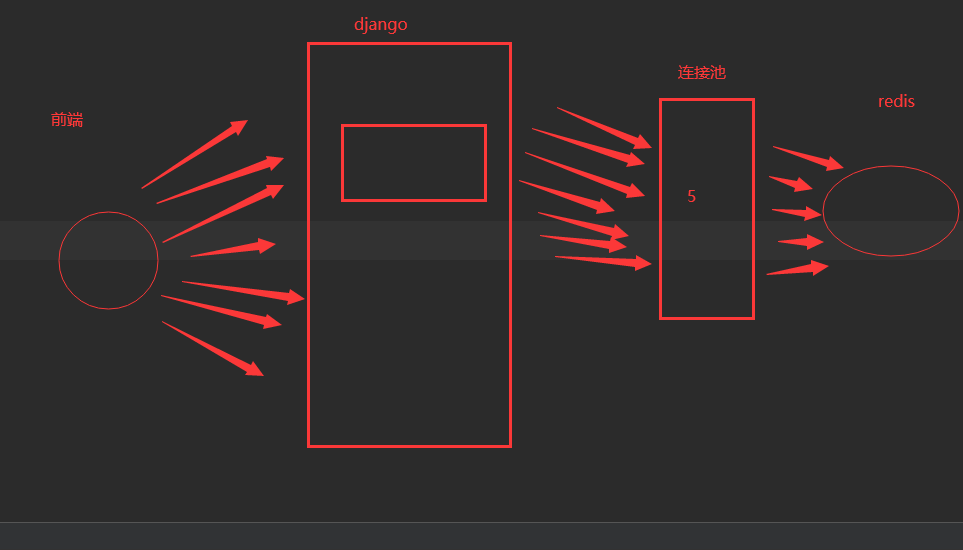
redis普通连接和连接池
#1 python 代码作为客户端---》连接
# 2 安装模块:pip install redis
![]()
普通连接
from redis import Redis
conn = Redis(host="localhost",port=6379,db=0,decode_responses=True)
res=conn.get('name')
print(res)
conn.close()
连接池
import redis
# 把池写成单例----》整个项目中,只有这一个实例(对象)---》python 中实现单例的5种方式---》模块导入的方式
POOL = redis.ConnectionPool(host='127.0.0.1', port=6379, max_connections=50)
######
import redis
from threading import Thread
from pool import POOL
def task():
conn = redis.Redis(connection_pool=POOL)
print(conn.get('name'))
conn.close()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task)
t.start()
redis字符串类型
'''
1 set(name, value, ex=None, px=None, nx=False, xx=False)
2 setnx(name, value)
3 setex(name, value, time)
4 psetex(name, time_ms, value)
5 mset(*args, **kwargs)
6 get(name)
7 mget(keys, *args)
8 getset(name, value)
9 getrange(key, start, end)
10 setrange(name, offset, value)
11 setbit(name, offset, value)
12 getbit(name, offset)
13 bitcount(key, start=None, end=None)
14 bitop(operation, dest, *keys)
15 strlen(name)
16 incr(self, name, amount=1)
# incrby
17 incrbyfloat(self, name, amount=1.0)
18 decr(self, name, amount=1)
19 append(key, value)
'''
import redis
conn = redis.Redis(decode_responses=True)
# 1 set(name, value, ex=None, px=None, nx=False, xx=False)
# conn.set('age','19') # 没有就新增,有值就修改
# conn.set('hobby','篮球',ex=5) # ex:过期时间单位为秒
# conn.set('hobby','篮球',px=5000) # px:过期时间单位为毫秒
# conn.set('name1', 'zfq', nx=True) # nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果(只能新增)
# conn.set('nam e', 'zfq', xx=True) # 如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值(只能修改)
# 2 setnx(name, value)
# conn.setnx('name2','彭于晏') # 等同于nx=True
# 3 setex(name, value, time)
# conn.setex('name2',5,'彭于晏') # 等同于加了ex参数,过期时间
# 4 psetex(name, time_ms, value)
# conn.psetex('name1',5000,'胡歌') # 等同于加了px参数,过期时间
# 5 mset(*args, **kwargs) # 批量设置
# conn.mset({'name':'zfq','age':'18','hobby':'洗脚'})
# 6 get(name)
# print(conn.get('name')) # 取出对应的键值
# 7 mget(keys, *args)
# print(conn.mget(['name','age'])) # 批量取值,没有的取None
# 8 getset(name, value)
# print(conn.getset('name', 'zjz')) # 取出旧值,设置成新值
# 9 getrange(key, start, end)
# print(conn.getrange('name', 0, 1)) # 取出一定范围内的字符,前闭后闭区间
# 10 setrange(name, offset, value)
# conn.setrange('name',3,'sb') # 在原值指定位置修改或添加,包括选定的索引位置
# 先不聊---》操作比特位---》后面聊
# 11 setbit(name, offset, value)
# conn.setbit('name',7,0) # l=[1 1 0 0 0 1 0 0 ]
# 12 getbit(name, offset)
# 13 bitcount(key, start=None, end=None)
# 14 bitop(operation, dest, *keys)
# 15 strlen(name)
# print(conn.strlen('name')) # 计算字节长度
# 16 incr(self, name, amount=1)
# conn.incr('age',2) # 自加,默认自加1,可选定加多少;单线程,没有并发安全,数据不会错乱,天然适合计数器 计数器---》日活(日活跃用户数,只要有用户登录,就+1)
# # incrby
# conn.incrby('age',2)
# 17 incrbyfloat(self, name, amount=1.0)
# conn.incrbyfloat('age',1.1) # 可以加小数,但是有精度误差
# 18 decr(self, name, amount=1)
# conn.decr('age') # 自减,默认自减1,可选定减多少
# 19 append(key, value)
# conn.append('name','gdx') # 在末尾追加
conn.close()
'''
set
get
getrange
strlen
'''
redis hash类型
'''
1 hset(name, key, value)
2 hmset(name, mapping)
3 hget(name,key)
4 hmget(name, keys, *args)
5 hgetall(name)
6 hlen(name)
7 hkeys(name)
8 hvals(name)
9 hexists(name, key)
10 hdel(name,*keys)
11 hincrby(name, key, amount=1)
12 hincrbyfloat(name, key, amount=1.0)
13 hscan(name, cursor=0, match=None, count=None)
14 hscan_iter(name, match=None, count=None)
'''
''' hash 类型,就是咱们python中的字典类型, 数据结构:数据的组织形式 底层存储 数组---》根据key值使用hash函数得到结构,存到数组中
字典的key值必须可hash
字典的key值必须是不可变数据类型
hash 类型无序,跟放的先后顺序无关的
python 的字典是 有序的 字典+列表
1 hset(name, key, value)
2 hmset(name, mapping)
3 hget(name,key)
4 hmget(name, keys, *args)
5 hgetall(name)
6 hlen(name)
7 hkeys(name)
8 hvals(name)
9 hexists(name, key)
10 hdel(name,*keys)
11 hincrby(name, key, amount=1)
12 hincrbyfloat(name, key, amount=1.0)
13 hscan(name, cursor=0, match=None, count=None)
14 hscan_iter(name, match=None, count=None)
'''
import redis
conn = redis.Redis(decode_responses=True)
# 1 hset(name, key, value)
# conn.hset('userinfo','name','zjz') # 有则添加无则修改
# conn.hset('userinfo','age','20')
# 2 hmset(name, mapping) # 已弃用,统一用hset
# conn.hmset('userinfo1',{'name':'zjz','age':'19'})
# 3 hget(name,key)
# print(conn.hget('userinfo', 'name')) # 取出指定key值对应的value
# 4 hmget(name, keys, *args)
# print(conn.hmget('userinfo',['name','age'])) # 一次取出多个值
# print(conn.hmget('userinfo','name','age')) # 一次取出多个值
# 5 hgetall(name)
# print(conn.hgetall('userinfo')) # 以hash形式一次性取出所有值,慎用==》userinfo 对应的value值非常多,一次性拿出来,很耗时
# 6 hlen(name)
# print(conn.hlen('userinfo')) # 计算键值对长度
# 7 hkeys(name)
# print(conn.hkeys('userinfo')) # 取出所有key值
# 8 hvals(name)
# print(conn.hvals('userinfo')) # 取出所有value值
# 9 hexists(name, key)
# print(conn.hexists('userinfo','name')) # 判断某个key值是否存在,返回布尔值
# 10 hdel(name,*keys)
# conn.hdel('userinfo', 'hanpi') # 根据key值删除
# 11 hincrby(name, key, amount=1)
# conn.hincrby('userinfo1','age') # 数字value值默认加1,可选择加几
# 12 hincrbyfloat(name, key, amount=1.0)
# conn.hincrbyfloat('userinfo1','age',1.2) # 数字value值默认加1,可选择加几,适用小数,但是有误差
# 13 hscan(name, cursor=0, match=None, count=None)
# 造数据
# for i in range(1000):
# conn.hset('hash1', 'egg_%s' % i, '鸡蛋%s号' % i)
# # count 数字是大致的 大小,如果拿了10 ,可能是9 可能是11
# res = conn.hscan('hash1',cursor=0,count=10)
# print(len(res[1]))
# print(res)
# 14 hscan_iter(name, match=None, count=None)# 替代hgetall,一次性全取出值,如果占内存很大,会有风险 , 使用hscan_iter 分批获取值,内存占用很小
for item in conn.hscan_iter('hash1', count=10):
print(item)
# 分批获取数据
conn.close()
'''
hset
hget
hlen
hexists
hincrby
hscan_iter
'''
redis列表类型
'''
1 lpush(name, values)
2 rpush(name, values) 表示从右向左操作
3 lpushx(name, value)
4 rpushx(name, value) 表示从右向左操作
5 llen(name)
6 linsert(name, where, refvalue, value))
7 r.lset(name, index, value)
8 r.lrem(name, value, num)
9 lpop(name)
10 rpop(name) 表示从右向左操作
11 lindex(name, index)
12 lrange(name, start, end)
13 ltrim(name, start, end)
14 rpoplpush(src, dst)
15 blpop(keys, timeout)
16 r.brpop(keys, timeout),从右向左获取数据
17 brpoplpush(src, dst, timeout=0)
'''
'''
1 lpush(name, values)
2 rpush(name, values) 表示从右向左操作
3 lpushx(name, value)
4 rpushx(name, value) 表示从右向左操作
5 llen(name)
6 linsert(name, where, refvalue, value))
7 r.lset(name, index, value)
8 r.lrem(name, value, num)
9 lpop(name)
10 rpop(name) 表示从右向左操作
11 lindex(name, index)
12 lrange(name, start, end)
13 ltrim(name, start, end)
14 rpoplpush(src, dst)
15 blpop(keys, timeout)
16 r.brpop(keys, timeout),从右向左获取数据
17 brpoplpush(src, dst, timeout=0)
'''
import redis
conn = redis.Redis(decode_responses=True)
# 1 lpush(name, values)
conn.lpush('girls', '刘亦菲', '迪丽热巴') # 从左往右加值,先进去的在右边或下边
# 2 rpush(name, values) 表示从右向左操作
# conn.rpush('girls','杨幂')
# 3 lpushx(name, value)
# conn.lpushx('girls','杨幂') # 只有key存在,才能追加
# 4 rpushx(name, value) 表示从右向左操作
# conn.rpushx('girls','zjz')
# 5 llen(name)
# print(conn.llen('girls')) # 计算列表长度
# 6 linsert(name, where, refvalue, value)) # 在指定值之前或之后添加值
# conn.linsert('girls',where='before',refvalue='zjz',value='ccy')
# conn.linsert('girls',where='after',refvalue='zjz',value='ccy')
# 7 r.lset(name, index, value)
# conn.lset('girls',0,'dad') # 修改指定索引位置的值
# 8 r.lrem(name, value, num)
# conn.lrem('girls',1,'刘亦菲') # 从左侧删一个
# conn.lrem('girls',-1,'刘亦菲') # 从右侧删一个
# conn.lrem('girls',0,'刘亦菲') # 全删除
# 9 lpop(name)
# print(conn.lpop('girls')) # 左侧弹出一个
# 10 rpop(name) 表示从右向左操作
# print(conn.rpop('girls')) # 右侧弹出
# 11 lindex(name, index)
# print(conn.lindex('girls',1)) # 查找指定索引位置的值
# 12 lrange(name, start, end)
# print(conn.lrange('girls',1,10)) # 查找指定索引范围的值,前闭后闭区间,取完为止
# 一次性把列表中数据都取出来
# print(conn.lrange('girls',0,-1)) # 可以用-1
# print(conn.lrange('girls',0,conn.llen('girls')))
# 13 ltrim(name, start, end)
# conn.ltrim('girls',3,4) # 保留指定索引范围的值,其余值删除
# 14 rpoplpush(src, dst)
# conn.rpoplpush('girls','girls') # 弹出某个列表再加入另一个列表,弹出和加入可以是同一个
# 15 blpop(keys, timeout) # block:阻塞 实现分布式的系统 消息队列
# res = conn.blpop('girls',timeout=5) # 从左开始弹出数据,没有数据弹出就会等在这,再往列表里加数据就能弹出了
# print(res)
# 16 r.brpop(keys, timeout),从右向左获取数据
# print(conn.blpop('girls',timeout=10))
# 17 brpoplpush(src, dst, timeout=0)
'''
lpush
rpush
llen
lrange
lpop
'''




 浙公网安备 33010602011771号
浙公网安备 33010602011771号