通过百度AI识别简单的验证码
为什么要使用百度AI的:
百度AI这个我之前用到的是语音识别,想着肯定也有图片识别成文字的,所以找了一下果然找了,而且可以免费使用一点。
![]()
注:调用的这个百度AI识别不是专门识别验证码图片的(它可以识别图片中的所有文字,包括空格),所以只能识别一些简单的验证码,专业的使用超级鹰(收费)
使用到的场景:
(1) 最近再写一个web自动化测试项目,在里面有一个selenium功能就是需要识别验证码。
(2) 在用爬虫爬取登陆后的页面内容时候,也需要识别验证码
百度AI找的地方:
支持识别的图片格式: # 以官方文档去查

# 仅jpg/png/bmp格式
使用如下代码需要先申请一个AI的应用:
当图片格式不是这三种格式时候,需要转换图片格式才能识别:
# 我用的是python3的pillow模块进行图片格式转换
# python2是pil模块
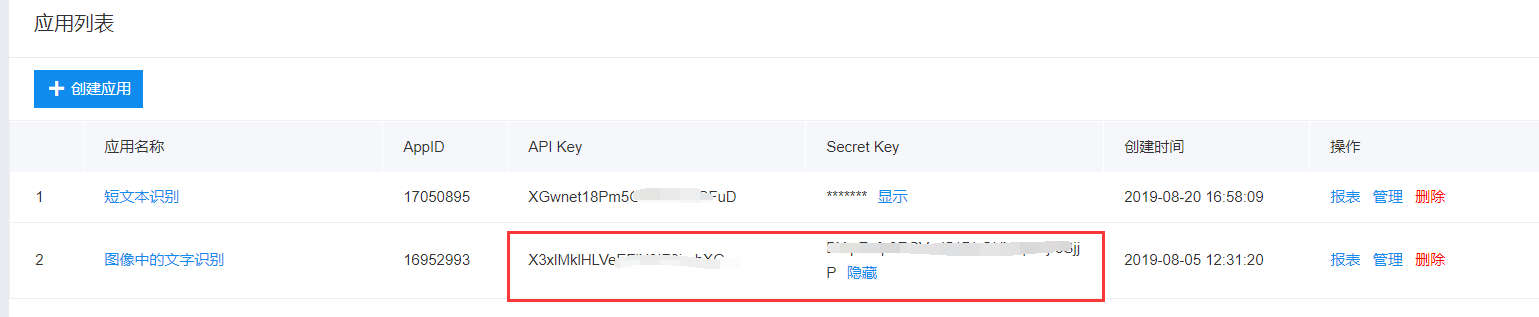
# 注意:记得填上自己应用id和secret
import requests import base64 import requests def get_token():
# 需要填上自己应用得 client_id = 'xxx' client_secret = 'xxxxx' # client_id 为官网获取的AK, client_secret 为官网获取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s' %(client_id, client_secret) response = requests.get(host) if response: # print(response.json()) return response.json()["access_token"] return "" # 以官方文档为主去写 def shibie_img(file_value, access_token=get_token()): request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" img = base64.b64encode(file_value) params = {"image": img} request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) if response: # print(response.json()) return response.json()["words_result"][0]["words"] return "" if __name__ == '__main__': # 转换图片得写法 from PIL import Image from io import BytesIO output = BytesIO() img = Image.open("./code.gif") # 转成jpeg,保存到内存 img.convert('RGB').save(output, "JPEG", quality=95) words = shibie_img(output.getvalue()) print(words) # 如果不需要转换图片格式得写法 # words = shibie_img(open(file="图片路径", mode="rb").read()) # print(words)
官方文档:
https://cloud.baidu.com/doc/OCR/s/zk3h7xz52
使用效果:
# 以古诗文网的验证码为例
https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx


# 用selenium执行的话,使用的时候需要截图下来


 浙公网安备 33010602011771号
浙公网安备 33010602011771号