深度学习系列笔记——贰 (基于Tensorflow2 Keras搭建的猫狗大战模型 三)
深度学习系列笔记——贰 (基于Tensorflow Keras搭建的猫狗大战模型 一)
深度学习系列笔记——贰 (基于Tensorflow Keras搭建的猫狗大战模型 二)
前面两篇博文已经介绍了如何利用keras搭建出简单的模型,接下来,在前面训练好的基础上,进行模型的使用。即调用训练好的模型对图片进行预测。
1、调用模型进行图片预测
需要注意的是,前面为了快速训练模型,并未开启save功能,此处需要开启之。以便保存模型,保存模型的方法还有很多,读者可以自行百度之,此处提供一种帮助大家学习。
下面直接给出demo代码
import matplotlib.pyplot as plt
import pathlib #本例中用于对输入输出的路径进行管理的包,直接pip即可安装
import tensorflow as tf
IMG_HEIGHT = 200
IMG_WIDTH = 200
"""
博主之前跑过好几个不同的模型,因此在前面保存模型时,命名为model_9,
读者也可以根据实际情况设置模型的名称
定位模型的位置后,利用tf.keras.models.load_model()导入模型
"""
model = tf.keras.models.load_model('D:/Desktop/catVSdog/model_9')
#设置测试集的图片来源
data_root = pathlib.Path('D:/Desktop/catVSdog/data/test')
all_image_paths = list(data_root.glob('*/'))
all_image_paths = [str(path) for path in all_image_paths]
#由于网络结构已经训练好,且已经固定,因此对喂入的图片需要经过预处理操作
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMG_HEIGHT, IMG_WIDTH])
image /= 255.0 #与之前一样,进行归一化操作
return image
#加载图片
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
i = 1
while i > 0:
i = int(input("请输入你想要检测的图片序号(1-12500):"))
if i > 12500:
print("超出列表索引范围,请重新输入")
continue
else:
pass
image = load_and_preprocess_image(all_image_paths[i])
image_array = tf.keras.preprocessing.image.img_to_array(image)
"""
之前喂入的是以(batchsize,200,200,3)的格式喂入,再次预测时,也需要使之符合前面的结构,
此处预测,我们用到的batchsize为1,此处仅作为测试案例,真实预测时,可以一次性喂入更多的图片,充分利用GPU减少I/O的损耗
此处的输入需要增加一个维度,因此需要变为(1,200,200,3)
"""
image_array = tf.expand_dims(image_array, 0)
"""
利用predict(),喂入图片,模型将返回预测结果,根据前面模型的定义,当输出的值<0时为猫,当输出的值 >0时为狗
"""
prediction = int(model.predict(image_array))
plt.imshow(image)
if prediction > 0:
title = "Dog"
else:
title = "Cat"
plt.title(("This is a " + title))#在其标题上显示预测结果
plt.show() #缺少这一句将无法正常显示图片
下面时运行结果,可以看出,模型能够很好的分辨出猫和狗的图片
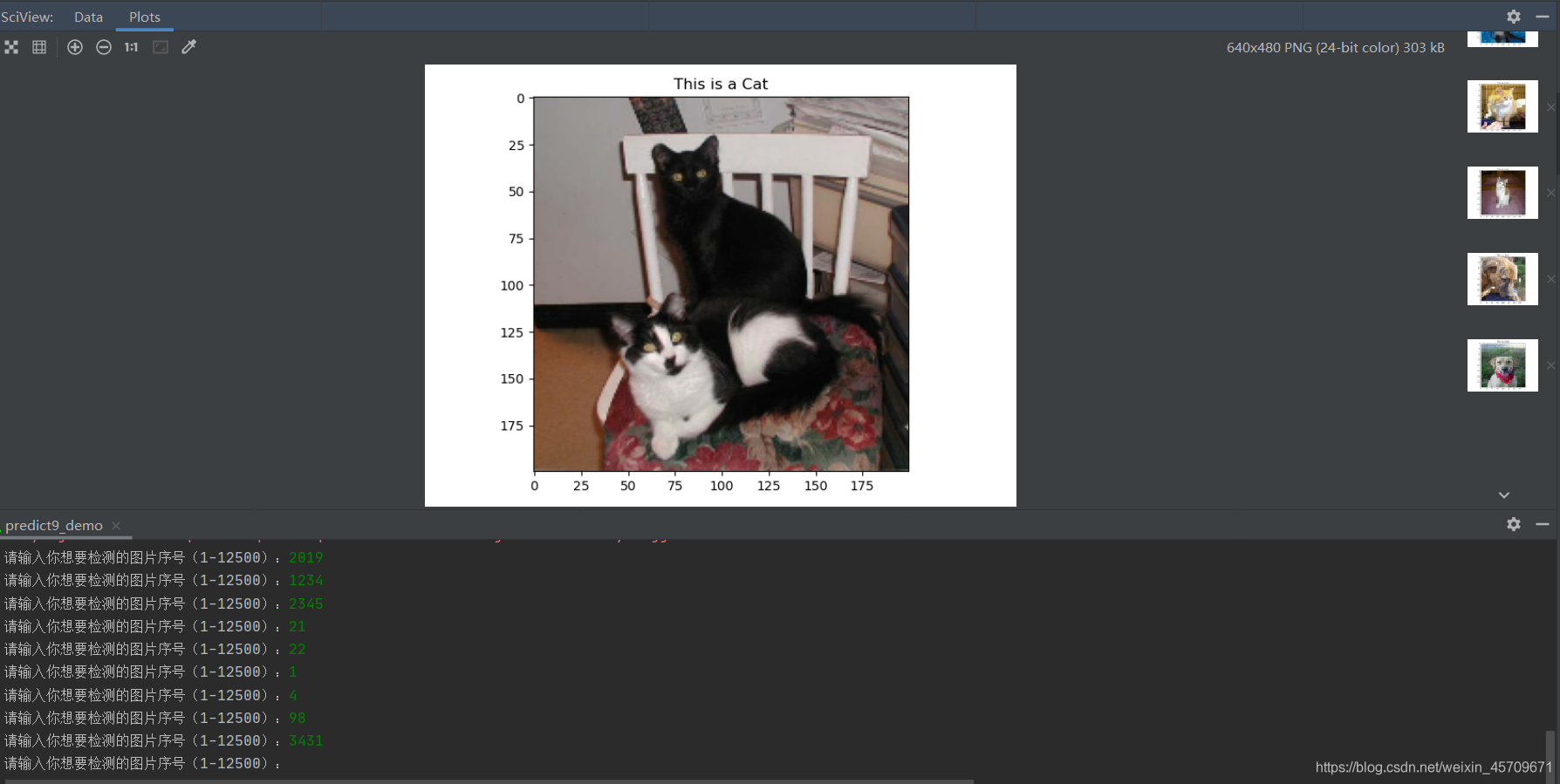
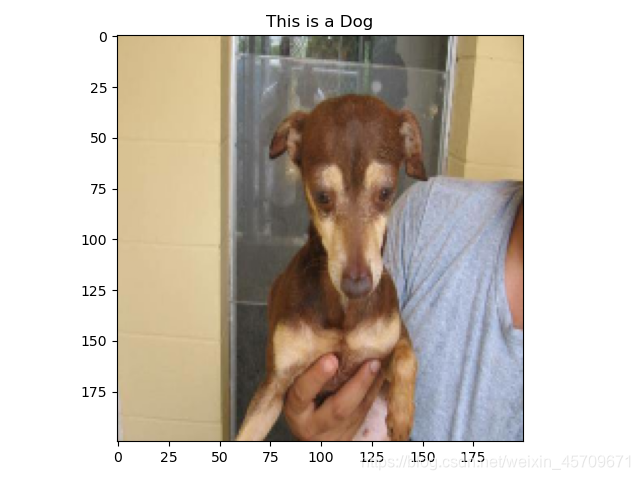
再贴出几张预测的图片,看看效果


对上面的代码稍加更改,即可获得下面一段利用模型进行预测并将预测结果写入csv文件的代码,运行后得到submission文件(这个文件是前面下载数据集时一同下载的,提交需要按照官方给出的格式,0代表猫,1代表狗,这里需要和上段代码中的逻辑输出值进行区分)

代码执行成功后,即可提交到kaggle网站
import numpy as np
import pathlib
import tensorflow as tf
IMG_HEIGHT = 200
IMG_WIDTH = 200
model = tf.keras.models.load_model('D:/Desktop/catVSdog/model_9')
data_root = pathlib.Path('D:/Desktop/catVSdog/data/test')
all_image_paths = list(data_root.glob('*/'))
all_image_paths = [str(path) for path in all_image_paths]
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMG_HEIGHT, IMG_WIDTH])
image /= 255.0
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
import re
import pandas as pd
label = np.zeros(12501, dtype=int)
"""
博主这里用的方法效率很低,但是非常简单易懂,
事实上,如果按照batch来喂入,GPU将会得到更好的利用,加快预测的时间,
后期博主还会添加利用dataset方法喂入图片,使得推理过程更加高效
"""
for i in range(12500):
image = load_and_preprocess_image(all_image_paths[i])
id = int(re.sub("\D", "", all_image_paths[i]))
image_array = tf.keras.preprocessing.image.img_to_array(image)
image_array = tf.expand_dims(image_array, 0)
prediction = int(model.predict(image_array))
if i % 100 == 0:
print("Predict the %d photo" % (i))
if prediction > 0:
label[id] = 1
else:
label[id] = 0
label = label.tolist()
dataframe = pd.DataFrame({'label': label})
dataframe.to_csv('model_9_submission.csv', sep=',')
#此处的输出可以根据自己的实际情况决定
下面是博主提交时得到的分数
kaggle上面还有各路大神,这个分数越低越好,具体的计算方法可以百度一下kaggle比赛分数计算的方法。
博主这个分数还是不太够看,但是作为刚入门的选手,这个猫狗大战更多的是让我们在实战中学会如何使用已有的知识和便捷的框架,搭建出一个还算不错的模型。

2、项目小结
1)项目总结
整个项目完成下来,给我的感觉就是keras使用还是非常方便的,利用Sequential结构,我们可以像搭建积木一样,将每一层堆叠到一起,快速的实现整个模型,特别是对于像vgg架构的网络,诸如vgg11,16,19等,都是可以很好的复现出来。再者,猫狗大战这个项目,也使得我们可以快速入门CNN的学习,其中出现的各类细节问题,也是我们完成整个项目下来最大的收获,例如利用管道的方式实现数据的实时增强,并喂入神经网络,使得我们的模型能够具有非常好的泛化能力,减少过拟合现象的发生。
值得注意的是,Sequential它有比较大的缺点,就是使得整个网络结构较为简单整齐,对于诸如InceptionNet,ResNet等复杂的架构,实现比较困难(可以通过嵌套Inecption块和resnet块的方式实现,但是比较麻烦,不如直接函数,利用函数的方式定义使整个模型简单易懂便于调试,后期还会有补充)。
因此,后续博主还会补充关于利用函数的方式搭建模型,利用类的方式搭建模型的方法,有了这些方法,并且配合keras我们可以搭建出更多结构更复杂,表现力更强的网络。
另外,前述的predict还有很大的改进空间,改进后可以更方便且高效地利用GPU,减少I/O耗费的时间。而关于运行模型的过程,时间非常长,博主运行在笔记本电脑,主要用的是intel i5 9代的处理器,gtx1650的显卡(4g显存,这也导致batchsize比较小,训练稍慢),这个配置玩玩游戏还说得过去,在2020年属于中低端游戏本,平时写写代码也很好用,但是拿它跑神经网络,倒是确实有些吃不消。
博主是分段跑的,也建议这么做,因为分段跑,可以分段观察整个模型的运行情况,当出现过拟合现象时,通过调整dropout的值,对这种现象进行一定程度的缓解。
博主在训练过程中,注意到如果数据增强得太严重,也就是说旋转度数太大,或者进行竖直翻转,会使得整个模型变得极其难以收敛,或许是因为训练得程度还不够,优化还不太足,但是这确实是个比较大的问题,后期博主还会继续补充相关的解释和解决方法。
前前后后跑了100多个epochs(具体没统计),总共花了10-20个小时的时间,模型跑下来,训练集的准确率最高到98.0%,而最高的验证集准确率能够达到93.5%左右,略微出现了过拟合,这说明模型还有很大的改进空间,当然了,作为入门级的模型,这个精度还算可以。
也可以利用vgg模型,resnet,googlenet等预训练的模型,将输出层替换为自己的设计的输出层,利用其在imagenet1000分类的预训练权重,加快训练的速度,提升效果。
接下来的项目,将是利用模型实现对验证码的破解,这个项目中根据猫狗大战项目的经验,进行了一定的优化。后续将补充出链接。
2)最后给出整个项目用到的完整代码:
其实前面的内容以及把所有用到的代码给出来了,这里只是整合到一起,方便快速部署。
train.py (前面的博客已经分部分给出,此处只是整理到一起)
# 导入包
"""
python==3.7
Tensorflow-gpu==2.1
"""
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
import os
import time
import matplotlib.pyplot as plt
# 下面的代码用于设置指定的GPU,根据需求使用即可
# os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# devices = tf.config.experimental.list_physical_devices('GPU')
# 设置显存随用随涨,而不是全部一起被分配
# tf.config.experimental.set_memory_growth(devices[0], True)
start = time.time()
# 设置目录路径
PATH = os.path.join('D:/Desktop/catVSdog/data') # 图片数据集的根目录
# 将目录区分位猫狗训练集和验证集
train_dir = os.path.join(PATH, 'train') # train数据集 相对于根目录
validation_dir = os.path.join(PATH, 'validation') # validation数据集 相对于根目录
train_cats_dir = os.path.join(train_dir, 'cats') # train目录下的文件夹 每个会在之后分为一类
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats') # validation目录下的文件夹 每个会在之后分为一类
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr # 文件数量求和 方便 后续处理和代码复用
total_val = num_cats_val + num_dogs_val
# current model accuracy: 0.9352 , val_accuracy: 0.9233
# 为方便起见,设置变量以在预处理数据集和训练网络时使用,参数根据自己的电脑配置设置
batch_size = 32
epochs = 8
# 建议每次训练,设置为8-16较为合理,这样也可以及时对模型进行更改
IMG_HEIGHT = 200
IMG_WIDTH = 200
# 使用实时数据增强生成一批张量图像数据。 通过通道方式获取图片
train_image_generator = ImageDataGenerator(rescale=1. / 255, rotation_range=5,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size, directory=train_dir, shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size, directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
model = tf.keras.models.Sequential([
# 第一层,padding设置为SAME,则说明输入图片大小和输出图片大小是一致的
layers.Conv2D(filters=32, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.32),
input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
# 第二层
layers.Conv2D(filters=32, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.32)),
# 连续利用两层3x3通道的卷积操作,可以实现5x5的卷积效果,还可以有效降低运算量,增大感受野
# 第三层
layers.Conv2D(filters=64, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.64)),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第四层
layers.Conv2D(filters=64, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.64)),
layers.MaxPooling2D(pool_size=2, strides=2),
# 第五层
layers.Conv2D(filters=128, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.128)),
# 第六层
layers.Conv2D(filters=128, kernel_size=3, strides=1, padding='same',
activation=tf.keras.layers.LeakyReLU(alpha=0.128)),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(), # 拉直
# 第七层
layers.Dense(1024, activation=tf.keras.layers.LeakyReLU(alpha=0.1024)),
layers.Dropout(rate=0.5),
# 第八层
layers.Dense(512, activation=tf.keras.layers.LeakyReLU(alpha=0.512)),
layers.Dropout(rate=0.4),
# 第九层
layers.Dense(128, activation=tf.keras.layers.LeakyReLU(alpha=0.128)),
layers.Dropout(rate=0.2),
# 第十层
layers.Dense(1, activation=tf.keras.layers.LeakyReLU(alpha=0.1))
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.0001, momentum=0.0001),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
checkpoint_save_path = "./checkpoint/demo_function_model.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(
train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[cp_callback],
)
# 输出模型信息
model.summary()
end = time.time()
print("This %d epochs cost time: %f s , average %f s per epoch" % (epochs, (end - start), (end - start) / epochs))
# 保存模型,训练到模型收敛时,打开即可
# model.save('model',save_format='tf')
# 可视化培训结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 记录模型优化过程及准确率
logFilePath = './/checkpoint//model_log.txt'
if os.path.isfile(logFilePath):
print("Log file exists.")
logWriter = open(logFilePath, 'a')
else:
print("Log file does not exists. Make it .")
logWriter = open(logFilePath, 'w')
logWriter.write('Training finish at : ' + str(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) + '\n')
logWriter.write('model id : ' + str(model.name) + '\n')
logWriter.write('Total epoch : ' + str(epochs) + '\n')
logWriter.write('These epochs cost time (second) : ' + str((end - start)) + '\n')
logWriter.write('Training accuracy : ' + '\n ' + str(history.history['accuracy']) + '\n')
logWriter.write('Validation accuracy: ' + '\n ' + str(history.history['val_accuracy']) + '\n')
logWriter.write('---------------------------------------------------------------------------\n')
logWriter.write('\n')
print("Log file has successfully written down.")
logWriter.close()
predict_demo.py (前面已给出,此处只是整理到一起)
import matplotlib.pyplot as plt
import pathlib
import tensorflow as tf
IMG_HEIGHT = 200
IMG_WIDTH = 200
model = tf.keras.models.load_model('D:/Desktop/catVSdog/model')
data_root = pathlib.Path('D:/Desktop/catVSdog/data/test')
all_image_paths = list(data_root.glob('*/'))
all_image_paths = [str(path) for path in all_image_paths]
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMG_HEIGHT, IMG_WIDTH])
image /= 255.0
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
i = 1
while i > 0:
i = int(input("请输入你想要检测的图片序号(1-12500):"))
if i > 12500:
print("超出列表索引范围,请重新输入")
continue
else:
pass
image = load_and_preprocess_image(all_image_paths[i])
image_array = tf.keras.preprocessing.image.img_to_array(image)
image_array = tf.expand_dims(image_array, 0)
prediction = int(model.predict(image_array))
plt.imshow(image)
if prediction > 0:
title = "Dog"
else:
title = "Cat"
plt.title(("This is a " + title))
plt.show()
predict_to_csv.py (前面已给出,此处只是整理到一起)
import numpy as np
import pathlib
import tensorflow as tf
IMG_HEIGHT = 200
IMG_WIDTH = 200
model = tf.keras.models.load_model('D:/Desktop/catVSdog/model_9')
data_root = pathlib.Path('D:/Desktop/catVSdog/data/test')
all_image_paths = list(data_root.glob('*/'))
all_image_paths = [str(path) for path in all_image_paths]
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMG_HEIGHT, IMG_WIDTH])
image /= 255.0
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
import re
import pandas as pd
label = np.zeros(12501, dtype=int)
"""
博主这里用的方法效率很低,但是非常简单易懂,
事实上,如果按照batch来喂入,GPU将会得到更好的利用,加快预测的时间,
后期博主还会添加利用dataset方法喂入图片,使得推理过程更加高效
"""
for i in range(12500):
image = load_and_preprocess_image(all_image_paths[i])
id = int(re.sub("\D", "", all_image_paths[i]))
image_array = tf.keras.preprocessing.image.img_to_array(image)
image_array = tf.expand_dims(image_array, 0)
prediction = int(model.predict(image_array))
if i % 100 == 0:
print("Predict the %d photo" % (i))
if prediction > 0:
label[id] = 1
else:
label[id] = 0
label = label.tolist()
dataframe = pd.DataFrame({'label': label})
dataframe.to_csv('model_9_submission.csv', sep=',')
#此处的输出可以根据自己的实际情况决定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号