第01章 绪论
1.1 引言

Q: 什么是模型? 什么是模式?
从学习过程看, 模式 是数据中「隐藏的重复性规律」; 模型 是试图通过训练过程学习并捕捉这些模式的工具.
1.2 基本术语
对象特征
(特征:特征值), 构建映射关系.

特征空间
三维特征组成的「蜂窝煤结构」.高维度进行类推.
每个点对应一个坐标向量, 构建起「特征向量」, 「特征向量」的集合形成特征空间.

样本数据
以下有10个样本数据构成一个数据集. 假设有10个不同的人获得各自的等量样本数据, 即可获得一个10个事例 的数据集.


预测模型
- 预测为「离散值」: 分类「二分类与多分类」, 天然与树数据结构一致
- 预测为「连续值」: 回归
上述样本数据集对每个样品进行了标签分类, 用于「分类」模型训练.
若标定的是西瓜成熟度, 如 0.98、0.95、0.37, 则属于回归.
- 训练数据拥有标记信息: 监督学习「分类/回归」
- 训练数据没有标记信息: 无监督学习「聚类」, 以下为通过
K-Means聚类算法进行的地震事件区域划分.

测试模型
机器学习的目标核心在于将学得的模型能很好地适用于「新样本」, 而不仅仅在训练样本上工作得很好. 即泛化能力
将未标签的样本数据集用于测试上述的预测模型, 来检验模型的能力.
1.3 假设空间
从样例中学习属于「归纳学习」
所有假设组成的空间中进行搜索的过程, 搜索目标是找到与训练集「匹配」的假设, 即能够将训练集中的瓜判断正确的假设.
假设的表示一旦确定, 假设空间及其规模大小就确定了.
在辨识西瓜的分类案例中, 所有假设组成的完整空间为上小节的特征空间, 受限于训练集数据量限制, 借由模型训练所得的假设空间可能是上述空间的子集.
1.4 归纳偏好
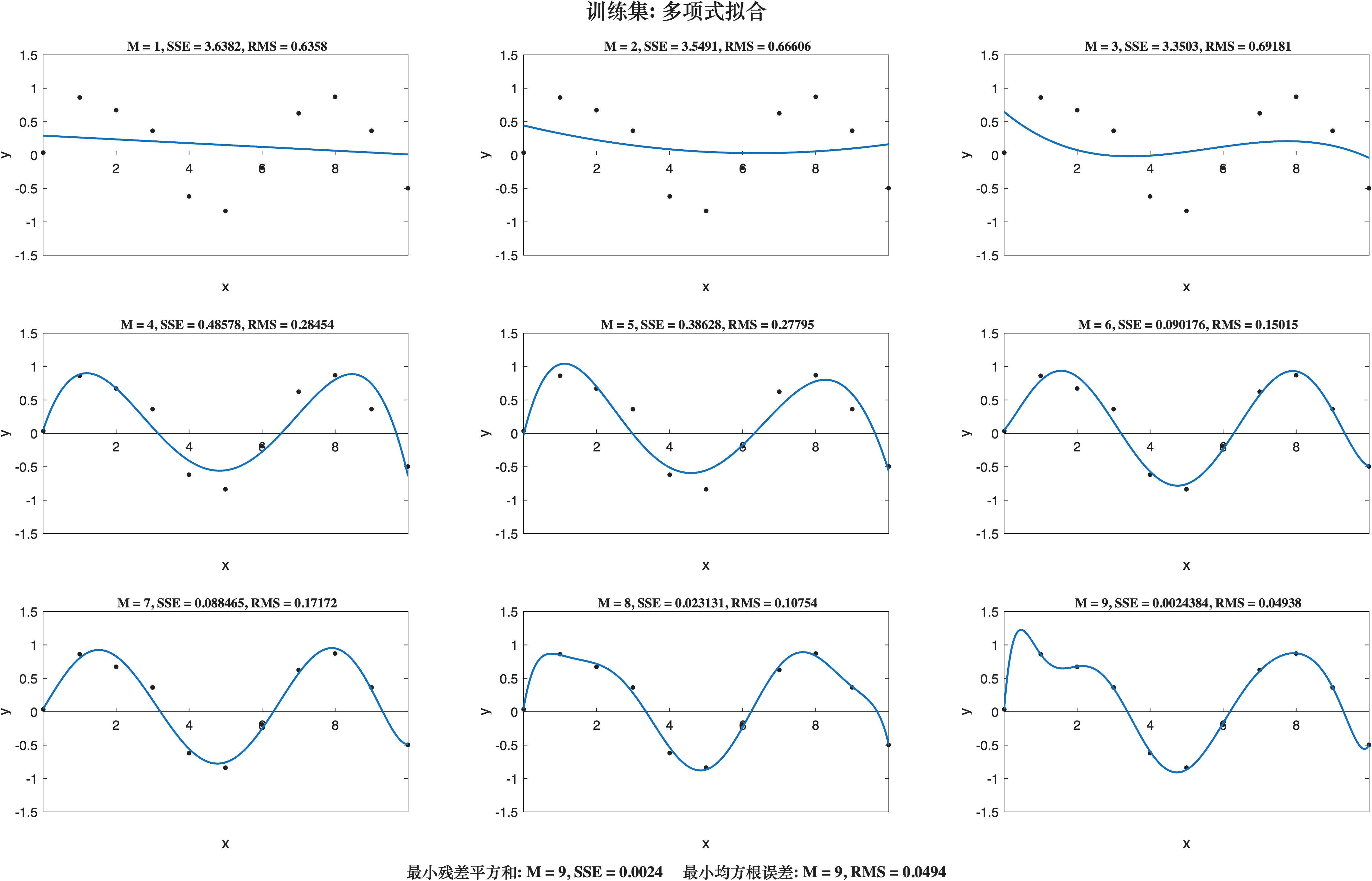
多项式拟合含有随机噪声的正弦曲线这个案例如果能够自己独立复现完成, 西瓜书上的这部分内容基本上能理解.
不同的阶数M对应不同的模型, 过高的阶数虽然能够贯穿整个数据集, 但是已经偏离了sin(x) 图的基本模式.
NFC:没有免费的午餐定理, 一定要关注其重要前提: 所有「问题」出现的机会相同、或所有的问题同等重要. 但是现实世界并非如此, 即脱离具体问题, 空泛地谈论「什么学习算法更好」毫无意义.
每种算法模型都有自己问题适配域, 算法自身的归纳偏好与问题是否相配, 往往起到决定性作用.
1.5 发展历程
发展历程部分整个时间顺序线需要单独厘清.
- 逻辑推理: 逻辑
- 知识工程: 符号
- 机器学习: 数据
- 机械学习:检索
- 示教学习: 从指令中学习
- 类比学习: 通过观察和发现学习
- 归纳学习: 从样例中学习, 统计学习和连接主义「深度学习—调参可提升性能, 大数据与强计算显著提升」
1.6 应用现状
现代科学研究: 理论 + 实验 + 计算
整合大数据时代的三大关键技术: 机器学习、云计算、众包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号