BUAA_OO_第三单元作业总结
第三单元作业总结
BUAA OO 2021面向对象作业
19373469 陈纪源
一、分析实现规格的设计策略
(一)第一次作业
在第一次作业中,由于刚开始遇到大量的JML规格约束,我选择的是先通读整个JML代码,了解每个函数、每个接口、每个异常类都在完成什么功能。在通读整个代码后发现整个社交网络的问题可以抽象成一个加边、加点、判断联通性的问题,对于不同的图操作对应使用不同的数据结构去维护它们。
下面举一个JML规格的例子,函数isCircle()如下:
/*@ public normal_behavior
@ requires contains(id1) && contains(id2);
@ ensures \result == (\exists Person[] array; array.length >= 2;
@ array[0].equals(getPerson(id1)) &&
@ array[array.length - 1].equals(getPerson(id2)) &&
@ (\forall int i; 0 <= i && i < array.length - 1;
@ array[i].isLinked(array[i + 1]) == true));
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(id1);
@ signals (PersonIdNotFoundException e) contains(id1) && !contains(id2);
@*/
public /*@pure@*/ boolean isCircle(int id1, int id2) throws PersonIdNotFoundException;
如果我们直接按照规格所说,寻找那个Person[]数组,我们可能就需要写dfs,这样的复杂度是O(n)的且有着爆栈的风险(在后面迭代的时候)。
在这里,我们在设计的时候可以想一想这个函数的本质,发现它其实相当于判断id1和id2的联通性,而我们的添加relation的操作是只有加边的没有删边的,因此我们在这里可以考虑使用并查集来维护这个联通性。
在每个Person类中,加入如下的内容:
private MyPerson root;
private int size;
分别表示这个并查集的根结点和所在并查集的大小(只有这个并查集的根结点的大小代表这个联通区域的大小)。
下面的函数是寻找一个Person的根结点:
public MyPerson getRoot() {
MyPerson tem = this;
while (!tem.root.equals(tem)) {
tem = tem.root;
}
return tem;
}
有了并查集,这样在完成isCircle()函数就可以使用快速的并查集了,时间复杂度O(log n)
public boolean isCircle(int id1, int id2) throws
PersonIdNotFoundException {
if (!contains(id1)) {
throw new MyPersonIdNotFoundException(id1);
} else if (!contains(id2)) {
throw new MyPersonIdNotFoundException(id2);
} else {
MyPerson p1 = (MyPerson) getPerson(id1);
MyPerson p2 = (MyPerson) getPerson(id2);
MyPerson r1 = p1.getRoot();
MyPerson r2 = p2.getRoot();
return r1.equals(r2);
}
}
总结一下,在实现规格时,要从规格的本质(即功能)出发,去设计相应的数据结构和算法去完成这个函数,切忌不可以完全照抄规格。
(二)第二次作业
第二次作业在第一次作业的基础上,数据范围有所扩大,增加了Group和Message类。
在迭代开发的时候,对于之前的JML规格,要十分小心,在设计时要保证之前的JML规格约束不受破坏,同时对于新的JML规格要通读了解和第一次作业之间的关系。
在设计时要善于使用容器来存储一些数据。
异常类由于数量较多,里面的计数功能我使用了一个计数器类存储异常次数。
public class Calculator {
private TreeMap<Integer, Integer> cal;
private int count;
这样对于一种异常类,如下记录:
public class MyEqualMessageIdException extends EqualMessageIdException {
private static Calculator calculator = new Calculator();
private int id;
通过一个静态类计数器来记录异常次数。
在设计时要抽象公共的功能,来使用一个特定的类去管理,类与类之间解耦度要高。
(三)第三次作业
第三次作业在第二次作业的基础上加入了不同类型的消息,在这次作业我采用了继承方式,对于消息类进行统一管理。
这样在写添加消息的时候就可以不使用那么多的instance of了。
同时最后一个sendIndirectMessage()函数需要把规格中对应的问题抽象出来,发现是一个单元最短路,可以使用dijkstra算法解决,进而避免过大的复杂度。
二、基于JML规格的测试的方法和策略
基于JML规格进行测试,主要有如下的方法和策略:
- 构造repOK函数方法,验证JML的前置条件和后置条件是否满足。
- 使用一些开源软件(TestNG)方法来进行测试。
- 通过理解JML规格,构造边界条件的数据(包括数据边界和时间边界)。
- 使用对拍的方式进行测试,和其余同学进行测试(这样就能看大家对于JML的理解是不是一样的了)。
三、容器选择和使用
本次作业中,我主要使用了TreeMap、HashMap、ArrayList还有静态数组四种容器,下面我来依次介绍这四种容器。
1. TreeMap
TreeMap是一种红黑树。
TreeMap支持插入某一元素、删除某一元素、整个key值的遍历。
TreeMap在使用时需要重载比较函数。
它的基本操作都是O(log n)的,遍历是O(nlog n)的。
一般如果需要快速查找某一键值对应的value,包括数据的动态插入删除,是可以使用TreeMap的,但是不建议在大规模需要遍历整个容器时使用TreeMap(毕竟复杂度高)
本次作业中我在计数器类、people类(记录id到人的映射)、消息类(记录id到消息的映射)、表情类使用了TreeMap。
基本上都是用来管理数据。
2. HashMap
HashMap是哈希表。
HashMap支持插入某一元素、删除某一元素、整个key值的遍历。
HashMap在使用时需要重载equal和hashcode函数。
它的基本操作是期望O(n/m),遍历是O(n)的。(m是映射范围)
和TreeMap一样,动态维护数据的插入和删除是可以使用HashMap的。
可能时由于对于HashMap的不信任(或许是期望的原因),我只在维护边集里面使用了HashMap。
其实从比较小的数据量来说,HashMap是会比TreeMap要更好的
3. ArrayList
ArrayList是动态数组。
ArrayList支持插入元素、删除元素、遍历整个数组。
不像HashMap和TreeMap,它的复杂度都是O(n)的。
但是它的常数会比TreeMap和HashMap要小(从Cache原理出发)
在本次作业中,我对于groups和emojiMessages这两种相对来说比较小的数据规模使用了ArrayList来管理。
4. 静态数组
静态数组相比于ArrayList,唯一的区别在于它的大小空间是开好的,因此常数会比ArrayList还要小。
在本次作业中,我创建的边类中,我给点与点之间创建了邻接矩阵,使用了静态数组。
四、性能问题分析
本单元最大的难点在于性能问题,但是我的代码并没有出现bug,下面我将来分析一下容易出现性能问题的函数。
(一)第一次作业
在第一次作业中,容易出现性能问题的函数就是第一部分所介绍的isCircle函数,这一部分可以使用并查集来解决。
(二)第二次作业
在第二次作业中,比较容易出现问题的是Group类中的getValueSum函数,这个函数在强测数据范围下如果每次都使用O(n^2)的算法是会TLE的。
因此在这里我们需要使用查询O(1)、修改O(n)的算法去完成这个函数。
首先我们先看这个value的JML:
/*@ ensures \result == (\sum int i; 0 <= i && i < people.length;
@ (\sum int j; 0 <= j && j < people.length &&
@ people[i].isLinked(people[j]); people[i].queryValue(people[j])));
@*/
public /*@pure@*/ int getValueSum();
我们考虑一下这个value在什么时候会发生变化。
当Group中的人没有发生改变时,这个value是不会发生改变的。
当一个人从一个Group中移出/加入时,和TA相连的人的value是需要加进来了的,因此有以下代码:
public void addPerson(Person person) {
for (int i = 0; i < personArrayList.size(); i++) {
valueSum = valueSum + 2 *
Relation.queryValue(((MyPerson) personArrayList.get(i)).getMapId(), currentId);
}
}
public void delPerson(Person person) {
for (int i = 0; i < personArrayList.size(); i++) {
if (personArrayList.get(i).getId() == person.getId()) {
personArrayList.remove(i);
i--;
} else {
valueSum = valueSum -
2 * Relation.queryValue(((MyPerson)
personArrayList.get(i)).getMapId(), currentId);
}
}
}
最重要的是,当一条新的关系加入的时候,需要遍历所有的Group,去找到包含这条两个人的Group,加上新的权值。
public void addRelation(int id1, int id2, int value) {
for (Group group : groups) {
MyGroup myGroup = (MyGroup) group;
if (myGroup.contain(p1) && myGroup.contain(p2)) {
myGroup.addValue(2 * Relation.queryValue(p1.getMapId(), p2.getMapId()));
}
}
}
(三)第三次作业
第三次作业中最容易出现性能问题的就是sendIndirectMessage函数,这个函数本质上要求两个结点之间的最短路。
这需要用dijkstra算法来解决这个问题。
传统的O(n^2)的dijkstra是不行的(数据范围10000),我本地也出了能卡暴力dijkstra到50s的数据。
需要使用堆优化的dijkstra去解决这个问题(使用pair或者新的类),时间复杂度O(n log n)。
为了不大量使用Map,我将每一个人的id离散化到了[1, 5000]的范围内,这样就可以数组存这些值了。
一个小优化,当我们的dijkstra找到终点之后直接break(而不是跑完),这样的剪枝可以快很多。
五、作业架构梳理
主要依据第三次作业进行梳理。
(一)架构类图
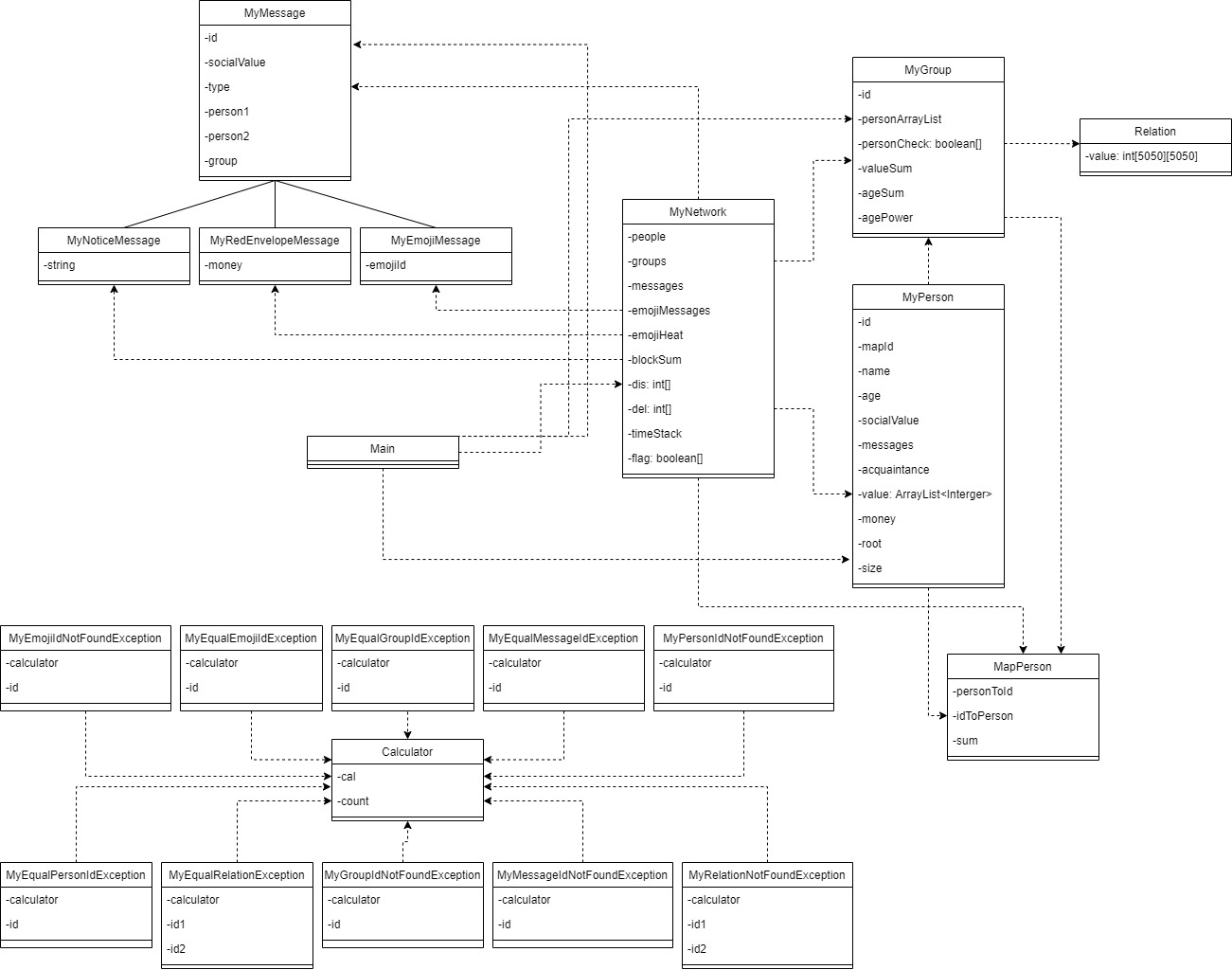
(二)各类介绍
有关图的维护和构建,主要是由MyPerson,MyPerson,MyNetwork,MyMessage类管理的。
MyPerson
存储网络中人的类,对应于图中的节点。
里面包括人的各种信息(这里面的MapId是我把所有人的id映射到了[1,5000]的映射之后的id,这样方便我使用数组来跑一些算法,减小常数)
还包括一些并查集的信息(包括该节点的father和该节点所组成的并查集树下方的大小)。
MyGroup
存储网络中分的组的类,对应于图中的一些点组成的集合。
里面包括使用该组的Value和和年龄和等。
当Person类元素从Group类元素加入或者删除时,需要动态修改Value、年龄和、年龄平方和等。
当然如果NetWork类中新加入一个Relation,也需要向包含这组Relation中两个人的Group中修改Value。
MyNetwork
存储整个网络的类,对应于图中点和边的集合。
存储包含了人的类、组的类、消息的类、表情消息的类的数据结构。
同时还包含了跑dijkstra的dis数组和是否访问过的flag数组,维护删除冷表情的del数组和时间戳timeStack。
里面实现的方法都是调用Person、Group类的方法,包括按照JML规格的其他逻辑,同时抛出对应的10个异常。
从面向对象角度来说,我的这次MyNetwork类实际上是非常不面向对象的,因为它维护了很多本该不需要它来维护的方法(比如dijkstra、时间戳法等),最好还是去写一些额外的类来统一处理这些其他的算法。
因此我的这次MyNetwork类非常长(500行),之后构建时需要再仔细思考。
Relation
存储人与人之间的关系类,对应于图的邻接矩阵。
使用邻接矩阵的原因是可以减小在dijkstra中的常数。
MapPerson
做高id到[1,5000]映射的类。
使用map来管理。
MyMessage
管理传递的消息类,类似于图中边的各种属性。
存储了消息的所有属性。
MyNoticeMessage
继承了MyMessage类,增加了字符串的属性。
MyRedEnvelopeMessage
继承了MyMessage类,增加了钱的属性。
MyEmojiMessage
继承了MyMessage类,增加了表情的编号的属性。
Calculator
计数器类,用来存储异常出现的次数。
My*Exception
10个异常类,用来表示不同的异常。
Main
整个工程的入口。
六、心得体会与反思
- 通过第三次作业的磨练,对JML相关内容有了进一步的了解。
- 更加认识到一个良好的架构,对于写代码的好处。
- 对于社交网络模型有了更加深入的理解,大体对这个模型有了一个概念。
- 对于规格化编程、契约化编程有了一个更加清醒的认识,意识到这种编程的重要性。
- 明白了JML规格不是让我们照抄,而是要根据功能设计架构和使用方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号