

深入解析Linux内核I/O剖析(open,write实现)
struct files_struct {大多数情况, 避免动/* count为文件表files_struct的引用计数 */
atomic_t count;
/* 文件描述符表 */
/*
为什么有两个fdtable呢?这是内核的一种优化策略。fdt为指针, 而fdtab为普通变量。一般情况下,
fdt是指向fdtab的, 当需要它的时候, 才会真正动态申请内存。因为默认大小的文件表足以应付大多数
情况, 因此这样就可以避免频繁的内存申请。
这也是内核的常用技巧之一。在创建时, 使用普通的变量或者数组, 然后让指针指向它, 作为默认情况使
用。只有当进程使用量超过默认值时, 才会动态申请内存。
*//*
struct fdtable __rcu *fdt;
struct fdtable fdtab;
* written part on a separate cache line in SMP
*/
/* 使用____cacheline_aligned_in_smp可以保证file_lock是以cache
line 对齐的, 避免了false sharing */
spinlock_t file_lock ____cacheline_aligned_in_smp;
/* 用于查找下一个空闲的fd */
int next_fd;
/* 保存执行exec需要关闭的文件描述符的位图 */
struct embedded_fd_set close_on_exec_init;
/* 保存打开的文件描述符的位图 */
struct embedded_fd_set open_fds_init;
/* fd_array为一个固定大小的file结构数组。struct file是内核用于文
件管理的结构。这里使用默认大小的数组, 就是为了可以涵盖态分配 */
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct file- {
struct list_head f_list; /*所有打开的文件形成一个链表*/struct dentry *f_dentry; /*指向相关目录项的指针*/struct vfsmount *f_vfsmnt; /*指向VFS安装点的指针*/struct file_operations *f_op; /*指向文件操作表的指针*/mode_t f_mode; /*文件的打开模式*/loff_t f_pos; /*文件的当前位置*/unsigned short f_flags; /*打开文件时所指定的标志*/unsigned short f_count; /*使用该结构的进程数*/unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;/*预读标志、要预读的最多页面数、上次预读后的文件指针、预读的字节数以及预读的页面数*/int f_owner; /* 通过信号进行异步I/O数据的传送*/unsigned int f_uid, f_gid; /*用户的UID和GID*/int f_error; /*网络写操作的错误码*/unsigned long f_version; /*版本号*/void *private_data; /* tty驱动程序所需 */};
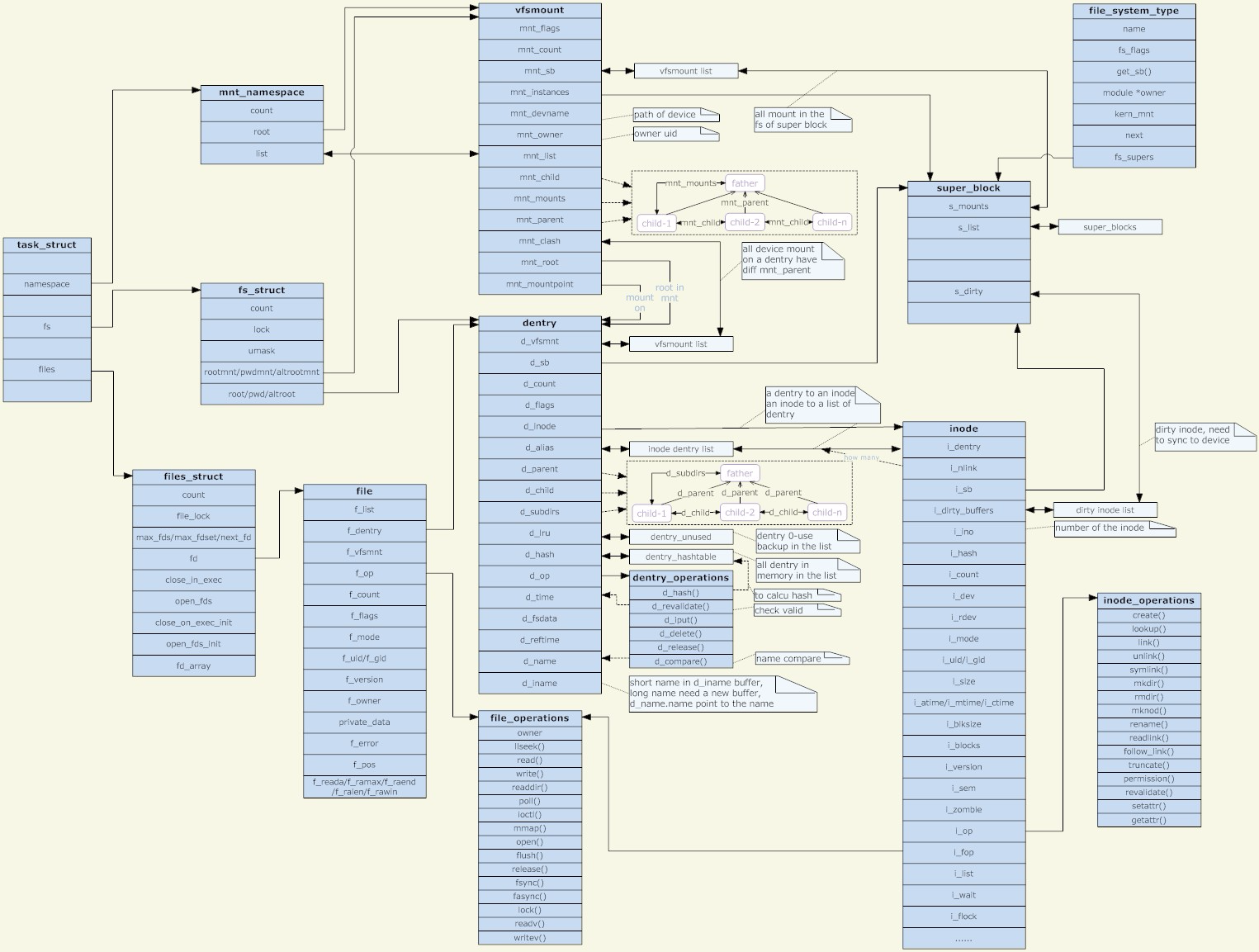
内核中,对应于每个进程都有一个文件描述符表,表示这个进程打开的所有文件。文件描述表中每一项都是一个指针,指向一个用于 描述打开的文件的数据块———file对象,file对象中描述了文件的打开模式,读写位置等重要信息,当进程打开一个文件时,内核就会创建一个新的 file对象。需要注意的是,file对象不是专属于某个进程的,不同进程的文件描述符表中的指针可以指向相同的file对象,从而共享这个打开的文件。 file对象有引用计数,记录了引用这个对象的文件描述符个数,只有当引用计数为0时,内核才销毁file对象,因此某个进程关闭文件,不影响与之共享同 一个file对象的进程.
int open(const char *pathname, int flags);int open(const char *pathname, int flags, mode_t mode);
long do_sys_open(int dfd, const char __user *filename, int flags, int mode){struct open_flags op;/* flags为用户层传递的参数, 内核会对flags进行合法性检查, 并根据mode生成新的flags值赋给 lookup */int lookup = build_open_flags(flags, mode, &op);/* 将用户空间的文件名参数复制到内核空间 */char *tmp = getname(filename);int fd = PTR_ERR(tmp);if (!IS_ERR(tmp)) {/* 未出错则申请新的文件描述符 */fd = get_unused_fd_flags(flags);if (fd >= 0) {/* 申请新的文件管理结构file */struct file *f = do_filp_open(dfd, tmp, &op, lookup);if (IS_ERR(f)) {put_unused_fd(fd);fd = PTR_ERR(f);} else {/* 产生文件打开的通知事件 */fsnotify_open(f);/* 将文件描述符fd与文件管理结构file对应起来, 即安装 */fd_install(fd, f);}}putname(tmp);}return fd;}
int alloc_fd(unsigned start, unsigned flags){struct files_struct *files = current->files;//获取当前进程的对应包含文件描述符表的结构unsigned int fd;int error;struct fdtable *fdt;/* files为进程的文件表, 下面需要更改文件表, 所以需要先锁文件表 */spin_lock(&files->file_lock);repeat:/* 得到文件描述符表 */fdt = files_fdtable(files);/* 从start开始, 查找未用的文件描述符。在打开文件时, start为0 */fd = start;/* files->next_fd为上一次成功找到的fd的下一个描述符。使用next_fd, 可以快速找到未用的文件描述符;*/if (fd < files->next_fd)fd = files->next_fd;/*当小于当前文件表支持的最大文件描述符个数时, 利用位图找到未用的文件描述符。如果大于max_fds怎么办呢?如果大于当前支持的最大文件描述符, 那它肯定是未用的, 就不需要用位图来确认了。*/if (fd < fdt->max_fds)fd = find_next_zero_bit(fdt->open_fds->fds_bits,fdt->max_fds, fd);/* expand_files用于在必要时扩展文件表。何时是必要的时候呢?比如当前文件描述符已经超过了当前文件表支持的最大值的时候。 */error = expand_files(files, fd);if (error < 0)goto out;/** If we needed to expand the fs array we* might have blocked - try again.*/if (error)goto repeat;/* 只有在start小于next_fd时, 才需要更新next_fd, 以尽量保证文件描述符的连续性。*/if (start <= files->next_fd)files->next_fd = fd + 1;/* 将打开文件位图open_fds对应fd的位置置位 */FD_SET(fd, fdt->open_fds);/* 根据flags是否设置了O_CLOEXEC, 设置或清除fdt->close_on_exec */if (flags & O_CLOEXEC)FD_SET(fd, fdt->close_on_exec);elseFD_CLR(fd, fdt->close_on_exec);error = fd;#if 1/* Sanity check */if (rcu_dereference_raw(fdt->fd[fd]) != NULL) {printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);rcu_assign_pointer(fdt->fd[fd], NULL);}#endifout:spin_unlock(&files->file_lock);return error;}
void fd_install(unsigned int fd, struct file *file){struct files_struct *files = current->files;//获得进程文件表(包含文件描述符表)struct fdtable *fdt;spin_lock(&files->file_lock);/* 得到文件描述符表 */fdt = files_fdtable(files);BUG_ON(fdt->fd[fd] != NULL);/*将文件描述符表中的file类型的指针数组中对应fd的项指向file。这样文件描述符fd与file就建立了对应关系*/rcu_assign_pointer(fdt->fd[fd], file);spin_unlock(&files->file_lock);}
SYSCALL_DEFINE1(close, unsigned int, fd){struct file * filp;/* 得到当前进程的文件表 */struct files_struct *files = current->files;struct fdtable *fdt;int retval;spin_lock(&files->file_lock);/* 通过文件表, 取得文件描述符表 */fdt = files_fdtable(files);/* 参数fd大于文件描述符表记录的最大描述符, 那么它一定是非法的描述符 */if (fd >= fdt->max_fds)goto out_unlock;/* 利用fd作为索引, 得到file结构指针 */filp = fdt->fd[fd];/*检查filp是否为NULL。正常情况下, filp一定不为NULL。*/if (!filp)goto out_unlock;/* 将对应的filp置为0*/rcu_assign_pointer(fdt->fd[fd], NULL);/* 清除fd在close_on_exec位图中的位 */FD_CLR(fd, fdt->close_on_exec);/* 释放该fd, 或者说将其置为unused。*/__put_unused_fd(files, fd);spin_unlock(&files->file_lock);/* 关闭file结构 */retval = filp_close(filp, files); //这里将引用计数/* can't restart close syscall because file table entry was cleared */if (unlikely(retval == -ERESTARTSYS ||retval == -ERESTARTNOINTR ||retval == -ERESTARTNOHAND ||retval == -ERESTART_RESTARTBLOCK))retval = -EINTR;return retval;out_unlock:spin_unlock(&files->file_lock);return -EBADF;}EXPORT_SYMBOL(sys_close);
static void __put_unused_fd(struct files_struct *files, unsigned int fd){/* 取得文件描述符表 */struct fdtable *fdt = files_fdtable(files);/* 清除fd在open_fds位图的位 */__FD_CLR(fd, fdt->open_fds);/* 如果fd小于next_fd, 重置next_fd为释放的fd */if (fd < files->next_fd)files->next_fd = fd;}

每个file结构体都指向一个file_operations结构体,这个结构体的成员都是函数指针,指向实现各种文件操作的内核函数。比如在用户程序中read一个文件描述符,read通过系统调用进入内核,然后找到这个文件描述符所指向的file结构体,找到file结构体所指向的file_operations结构体,调用它的read成员所指向的内核函数以完成用户请求。在用户程序中调用lseek、read、write、ioctl、open等函数,最终都由内核调用file_operations的各成员所指向的内核函数完成用户请求。file_operations结构体中的release成员用于完成用户程序的close请求,之所以叫release而不叫close是因为它不一定真的关闭文件,而是减少引用计数,只有引用计数减到0才关闭文件。对于同一个文件系统上打开的常规文件来说,read、write等文件操作的步骤和方法应该是一样的,调用的函数应该是相同的,所以图中的三个打开文件的file结构体指向同一个file_operations结构体。如果打开一个字符设备文件,那么它的read、write操作肯定和常规文件不一样,不是读写磁盘的数据块而是读写硬件设备,所以file结构体应该指向不同的file_operations结构体,其中的各种文件操作函数由该设备的驱动程序实现。
每个file结构体都有一个指向dentry结构体的指针,“dentry”是directory entry(目录项)的缩写。我们传给open、stat等函数的参数的是一个路径,例如/home/akaedu/a,需要根据路径找到文件的inode。为了减少读盘次数,内核缓存了目录的树状结构,称为dentry cache,其中每个节点是一个dentry结构体,只要沿着路径各部分的dentry搜索即可,从根目录/找到home目录,然后找到akaedu目录,然后找到文件a。dentry cache只保存最近访问过的目录项,如果要找的目录项在cache中没有,就要从磁盘读到内存中。
每个dentry结构体都有一个指针指向inode结构体。inode结构体保存着从磁盘inode读上来的信息。在上图的例子中,有两个dentry,分别表示/home/akaedu/a和/home/akaedu/b,它们都指向同一个inode,说明这两个文件互为硬链接。inode结构体中保存着从磁盘分区的inode读上来信息,例如所有者、文件大小、文件类型和权限位等。每个inode结构体都有一个指向inode_operations结构体的指针,后者也是一组函数指针指向一些完成文件目录操作的内核函数。和file_operations不同,inode_operations所指向的不是针对某一个文件进行操作的函数,而是影响文件和目录布局的函数,例如添加删除文件和目录、跟踪符号链接等等,属于同一文件系统的各inode结构体可以指向同一个inode_operations结构体。
inode结构体有一个指向super_block结构体的指针。super_block结构体保存着从磁盘分区的超级块读上来的信息,例如文件系统类型、块大小等。super_block结构体的s_root成员是一个指向dentry的指针,表示这个文件系统的根目录被mount到哪里,在上图的例子中这个分区被mount到/home目录下。
file、dentry、inode、super_block这
几个结构体组成了VFS的核心概念。对于ext2文件系统来说,在磁盘存储布局上也有inode和超级块的概念,所以很容易和VFS中的概念建立对应关
系。而另外一些文件系统格式来自非UNIX系统(例如Windows的FAT32、NTFS),可能没有inode或超级块这样的概念,但为了能mount到Linux系统,也只好在驱动程序中硬凑一下,在Linux下看FAT32和NTFS分区会发现权限位是错的,所有文件都是rwxrwxrwx,因为它们本来就没有inode和权限位的概念,这是硬凑出来的
static const struct file_operations socket_file_ops = {.owner = THIS_MODULE,.llseek = no_llseek,.aio_read = sock_aio_read,.aio_write = sock_aio_write,.poll = sock_poll,.unlocked_ioctl = sock_ioctl,#ifdef CONFIG_COMPAT.compat_ioctl = compat_sock_ioctl,#endif.mmap = sock_mmap,.open = sock_no_open, /* special open code to disallow open via /proc */.release = sock_close,.fasync = sock_fasync,.sendpage = sock_sendpage,.splice_write = generic_splice_sendpage,.splice_read = sock_splice_read,};
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,&socket_file_ops);
struct file *alloc_file(struct path *path, fmode_t mode,const struct file_operations *fop){struct file *file;/* 申请一个file */file = get_empty_filp();if (!file)return NULL;file->f_path = *path;file->f_mapping = path->dentry->d_inode->i_mapping;file->f_mode = mode;/* 将自定义的文件操作函数指针结构体赋给file->f_op */file->f_op = fop;……}
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count){struct file *file;ssize_t ret = -EBADF;int fput_needed;/* 通过文件描述符fd得到管理结构file */file = fget_light(fd, &fput_needed);if (file) {/* 得到文件的当前偏移量 */loff_t pos = file_pos_read(file);/* 利用vfs进行真正的read */ret = vfs_read(file, buf, count, &pos);/* 更新文件偏移量 */file_pos_write(file, pos);/* 归还管理结构file, 如有必要, 就进行引用计数操作*/fput_light(file, fput_needed);}return ret;}
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos){ssize_t ret;/* 检查文件是否为读取打开 */if (!(file->f_mode & FMODE_READ))return -EBADF;/* 检查文件是否支持读取操作 */if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))return -EINVAL;/* 检查用户传递的参数buf的地址是否可写 */if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))return -EFAULT;/* 检查要读取的文件范围实际可读取的字节数 */ret = rw_verify_area(READ, file, pos, count);if (ret >= 0) {/* 根据上面的结构, 调整要读取的字节数 */count = ret;/*如果定义read操作, 则执行定义的read操作如果没有定义read操作, 则调用do_sync_read—其利用异步aio_read来完成同步的read操作。*/if (file->f_op->read)ret = file->f_op->read(file, buf, count, pos);elseret = do_sync_read(file, buf, count, pos);if (ret > 0) {/* 读取了一定的字节数, 进行通知操作 */fsnotify_access(file);/* 增加进程读取字节的统计计数 */add_rchar(current, ret);}/* 增加进程系统调用的统计计数 */inc_syscr(current);}return ret;}
int udp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,size_t len, int noblock, int flags, int *addr_len)……ulen = skb->len - sizeof(struct udphdr);copied = len;if (copied > ulen)copied = ulen;……
mutex_lock(&inode->i_mutex);//加锁blk_start_plug(&plug);ret = __generic_file_aio_write(iocb, iov, nr_segs, &iocb->ki_pos);//发现文件是追加打开,直接从inode读取最新文件大小作为偏移量mutex_unlock(&inode->i_mutex); //解锁
if (file->f_flags & O_APPEND)*pos = i_size_read(inode);
int dup(int oldfd);int dup2(int oldfd, int newfd);
SYSCALL_DEFINE1(dup, unsigned int, fildes){int ret = -EBADF;/* 必须先得到文件管理结构file, 同时也是对描述符fildes的检查 */struct file *file = fget_raw(fildes);if (file) {/* 得到一个未使用的文件描述符 */ret = get_unused_fd();if (ret >= 0) {/* 将文件描述符与file指针关联起来 */fd_install(ret, file);}elsefput(file);}return ret;}
void fd_install(unsigned int fd, struct file *file){struct files_struct *files = current->files;struct fdtable *fdt;/* 对文件表进行保护 */spin_lock(&files->file_lock);/* 得到文件表 */fdt = files_fdtable(files);BUG_ON(fdt->fd[fd] != NULL);/* 让文件表中fd对应的指针等于该文件关联结构file */rcu_assign_pointer(fdt->fd[fd], file);spin_unlock(&files->file_lock);}
SYSCALL_DEFINE2(dup2, unsigned int, oldfd, unsigned int, newfd){/* 如果oldfd与newfd相等, 这是一种特殊的情况 */if (unlikely(newfd == oldfd)) { /* corner case */struct files_struct *files = current->files;int retval = oldfd;/*检查oldfd的合法性, 如果是合法的fd, 则直接返回oldfd的值;如果是不合法的, 则返回EBADF*/rcu_read_lock();if (!fcheck_files(files, oldfd))retval = -EBADF;rcu_read_unlock();return retval;}/* 如果oldfd与newfd不同, 则利用sys_dup3来实现dup2 */
return sys_dup3(oldfd, newfd, 0);}
int stat(const char *path, struct stat *buf);int fstat(int fd, struct stat *buf);int lstat(const char *path, struct stat *buf);
struct stat {dev_t st_dev; /* ID of device containing file */ino_t st_ino; /* inode number */mode_t st_mode; /* protection */nlink_t st_nlink; /* number of hard links */uid_t st_uid; /* user ID of owner */gid_t st_gid; /* group ID of owner */dev_t st_rdev; /* device ID (if special file) */off_t st_size; /* total size, in bytes */blksize_t st_blksize; /* blocksize for file system I/O */blkcnt_t st_blocks; /* number of 512B blocks allocated */time_t st_atime; /* time of last access */time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last status change */
};
SYSCALL_DEFINE2(stat, const char __user *, filename,struct __old_kernel_stat __user *, statbuf){struct kstat stat;int error;/* vfs_stat用于读取文件元数据至stat */error = vfs_stat(filename, &stat);if (error)return error;/* 这里仅是从内核的元数据结构stat复制到用户层的数据结构statbuf中 */return cp_old_stat(&stat, statbuf);}
int vfs_getattr(struct vfsmount *mnt, struct dentry *dentry, struct kstat *stat){struct inode *inode = dentry->d_inode;int retval;/* 对获取inode属性操作进行安全性检查 */retval = security_inode_getattr(mnt, dentry);if (retval)return retval;/* 如果该文件系统定义了这个inode的自定义操作函数, 就执行它 */if (inode->i_op->getattr)return inode->i_op->getattr(mnt, dentry, stat);/* 如果文件系统没有定义inode的操作函数, 则执行通用的函数 */generic_fillattr(inode, stat);return 0;}
void generic_fillattr(struct inode *inode, struct kstat *stat){stat->dev = inode->i_sb->s_dev;stat->ino = inode->i_ino;stat->mode = inode->i_mode;stat->nlink = inode->i_nlink;stat->uid = inode->i_uid;stat->gid = inode->i_gid;stat->rdev = inode->i_rdev;stat->size = i_size_read(inode);stat->atime = inode->i_atime;stat->mtime = inode->i_mtime;stat->ctime = inode->i_ctime;stat->blksize = (1 << inode->i_blkbits);stat->blocks = inode->i_blocks;}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号