

pyhton爬虫爬取微博某个用户所有微博配图
前几天写了个java爬虫爬花瓣网,但是事后总感觉不够舒服,终于在今天下午写了个python爬虫(爬微博图片滴),写完之后就感觉舒服了,果然爬虫就应该用python来写,哈哈(这里开个玩笑,非引战言论)。话不多说进入正题。
1.分析页面
我之前去网上搜了一圈爬微博的爬虫大都是采用模拟登陆的方式爬取,我这里并没有采用那种方式,直接是通过模拟请求得到数据的。如下(爬取的微博:https://m.weibo.cn/profile/1792328230)
这个页面是该博主的个人简介页面,直接拉到底,会有一个查看所有微博,点击它会跳转到该博主的所有微博页面
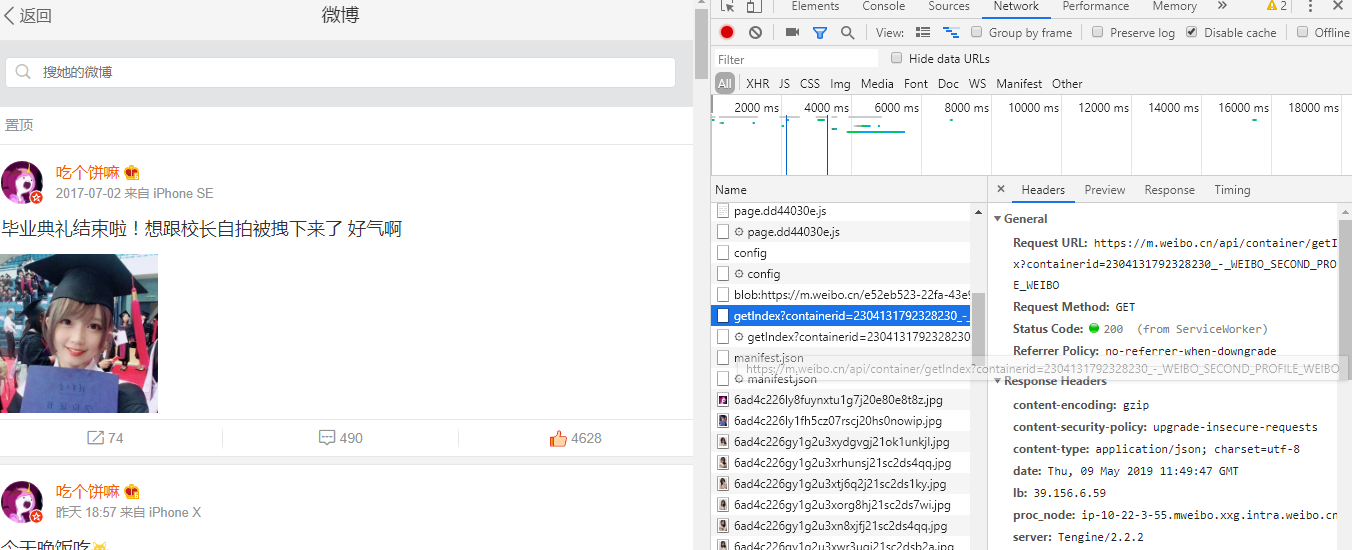
这里打开开发者工具查看网络请求,找到这个数据接口https://m.weibo.cn/api/container/getIndex?containerid=2304131792328230_-_WEIBO_SECOND_PROFILE_WEIBO,你会发现本页面所有内容都在该请求返回的json数据包中。
接着往下滑页面继续观察该请求窗口,就会发现这个接口的参数的规律。发现规律后就是老一套的模拟ajax加载获取多页数据,然后爬取目标内容。该数据接口参数如下:
https://m.weibo.cn/api/container/getIndex?containerid=?&page=? 其中参数id是指定该用户,page就是页数(默认从1开始).
(json数据可自行观察规律,很容易找到要爬的数据所在)
2.开始写代码
创建一个WbGrawler类,并在构造方法初始化固定参数,如下:
class WbGrawler(): def __init__(self): """ 参数的初始化 :return: """ self.baseurl = "https://m.weibo.cn/api/container/getIndex?containerid=2304131792328230&" self.headers = { "Host": "m.weibo.cn", "Referer": "https://m.weibo.cn/p/2304131792328230", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36", "X-Requested-with": "XMLHttpRequest" } # 图片保存路径 self.path = "D:/weibosrc/"
然后去写一个获取单个页面json数据的方法,因为变化的参数只有page,所以这里传入一个page即可,如下:
def getPageJson(self,page): """ 获取单个页面的json数据 :param page:传入的page参数 :return:返回页面响应的json数据 """ url = self.baseurl + "page=%d"%page try: response = requests.get(url,self.headers) if response.status_code==200: return response.json() except requests.ConnectionError as e: print("error",e.args)
拿到json数据后就要开始解析它并得到目标数据,所以这里写一个解析json数据的方法,传入一个json参数,如下:
def parserJson(self, json): """ 解析json数据得到目标数据 :param json: 传入的json数据 :return: 返回目标数据 """ items = json.get("data").get("cards") for item in items: pics = item.get("mblog").get("pics") picList = [] # 有些微博没有配图,所以需要加一个判断,方便后面遍历不会出错 if pics is not None: for pic in pics: pic_dict = {} pic_dict["pid"] = pic.get("pid") pic_dict["url"] = pic.get("large").get("url") picList.append(pic_dict) yield picList
这里返回的是一个个列表,列表里面的元素是存储图片信息的字典,得到图片信息后就可以开始下载了(最令人兴奋的下载环节),如下:
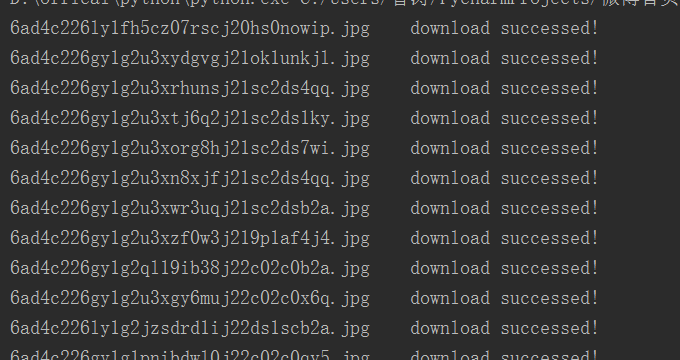
def imgDownload(self,results): """ 下载图片 :param results: :return: """ for result in results: for img_dict in result: img_name = img_dict.get("pid") + ".jpg" try: img_data = requests.get(img_dict.get("url")).content with open(self.path+img_name,"wb") as file: file.write(img_data) file.close() print(img_name+"\tdownload successed!") except Exception as e: print(img_name+"\tdownload failed!",e.args)

3.程序的优化
一开始试着爬了一页爬了好久(可能是电脑性能或者网络的问题),所以想着能不能开启多线程爬取,但是用户输入的页数是未知的,开启多少个子线程貌似很难取舍,这里我想到了在java里学的一个知识点--线程池,对利用线程池的特点就能完全规避掉这个尴尬。python线程池可参考这篇博客:https://www.cnblogs.com/xiaozi/p/6182990.html
def startCrawler(self,page): page_json = self.getPageJson(page) results = self.parserJson(page_json) self.imgDownload(results)
if __name__ == '__main__': wg = WbGrawler() pool = threadpool.ThreadPool(10) reqs = threadpool.makeRequests(wg.startCrawler,range(1,5)) [pool.putRequest(req) for req in reqs] pool.wait()
4.写在最后
最后就没了,源码:https://github.com/zengtao614/WbCrawler ,上文如有错误或者疏漏之处欢迎指出,万分感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号