hadoop完全分布式安装
环境介绍
| 操作系统 | CentOS 6.5 x86_64 |
| Java | 1.7.0_79 |
| hadoop | 2.6.1 |
| 主机名 | ip | 角色 |
| hadoop01 | 192.168.103.137 | ResourceManager/NameNode/SecondaryNameNode |
| hadoop02 | 192.168.103.138 | NodeManager/DataNode |
| hadoop03 | 192.168.103.140 | NodeManager/DataNode |
环境配置
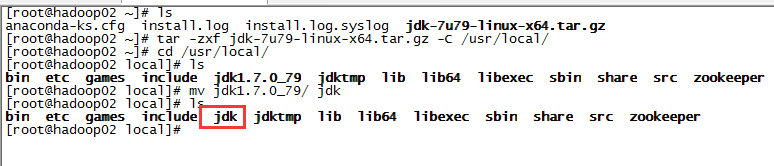
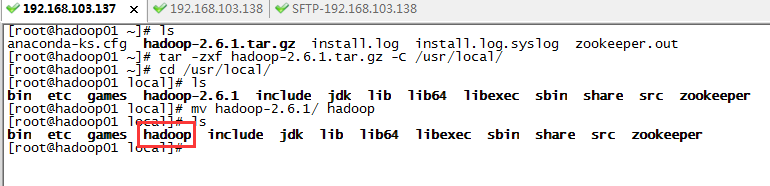
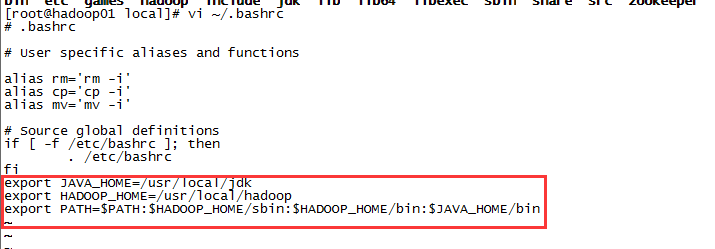
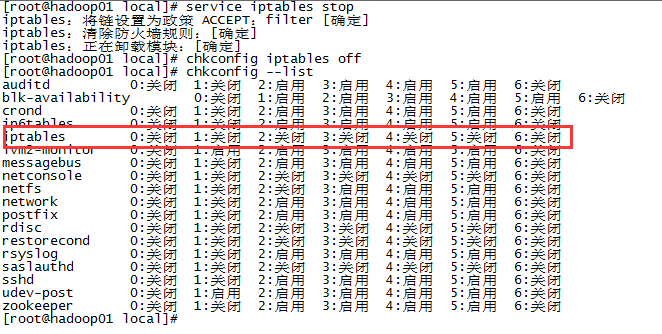


三台服务器分别执行ssh-keygen -t rsa生成密匙对,然后通过ssh-copy-id
root@192.168.103.137,将公匙加到三台服务器授权列表,注意每台服务器都要全部配到三台,包括当前所在主机。配置好后三台服务器能相互ssh登入

安装hadoop
对三台服务器都进行如下操作,修改hadoop配置文件,配置文件在安装目录etc/hadoop下,需要修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。
创建/usr/local/hadoop/tmp目录:
修改core-site.xml为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml为:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
将mapred-site.xml.template更名为mapred-site.xml,并mapred-site.xml修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
</configuration>

启动hadoop
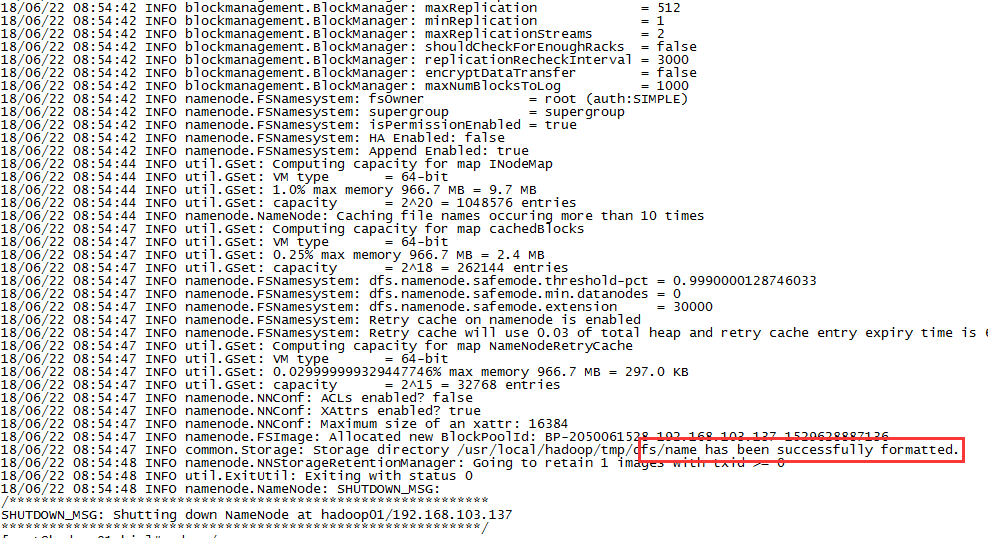
1)格式化文件系统,hadoop可以在任意目录执行,因为配置了path环境变量,其实调用的是/usr/local/hadoop/bin下的hadoop命令
hadoop namenode -format
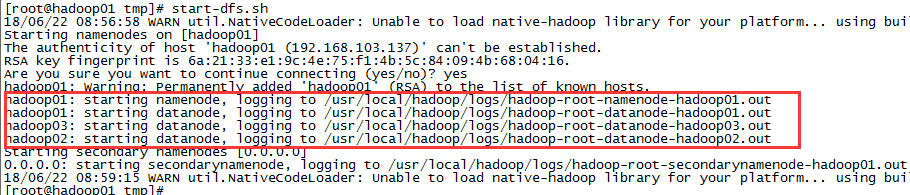
2)启动hdfs,hadoop可以在任意目录执行,因为配置了path环境变量,其实调用的是/usr/local/hadoop/sbin下的start-dfs.sh命令
start-dfs.sh
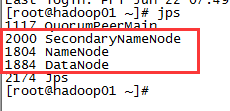
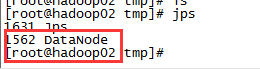
启动成功后通过jps命令查看进程,hadoop01节点启动了三个进程SecondaryNameNode、NameNode、DataNode,hadoop02和hadoop03启动进程一样,只启动了DataNode进程。
3)启动yarn
start-yarn.sh

通过jps命令查看进程,hadoop01节点启动了两个进程ResourceManager、NodeManager,hadoop2和hadoop03启动进程一样,只启动了NodeManager进程。
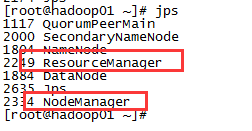
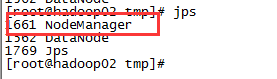
4)运行效果
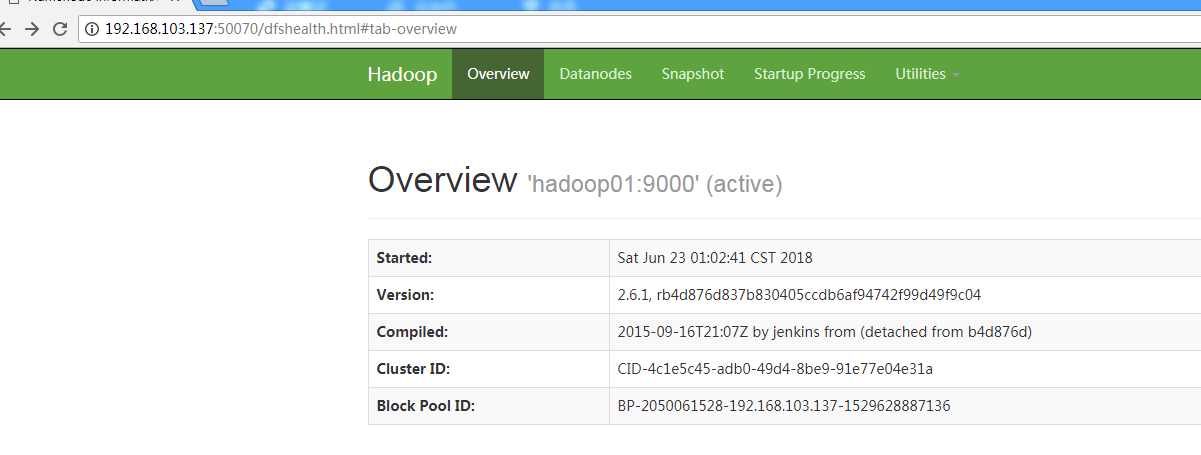
在window浏览器访问http://192.168.103.137:50070
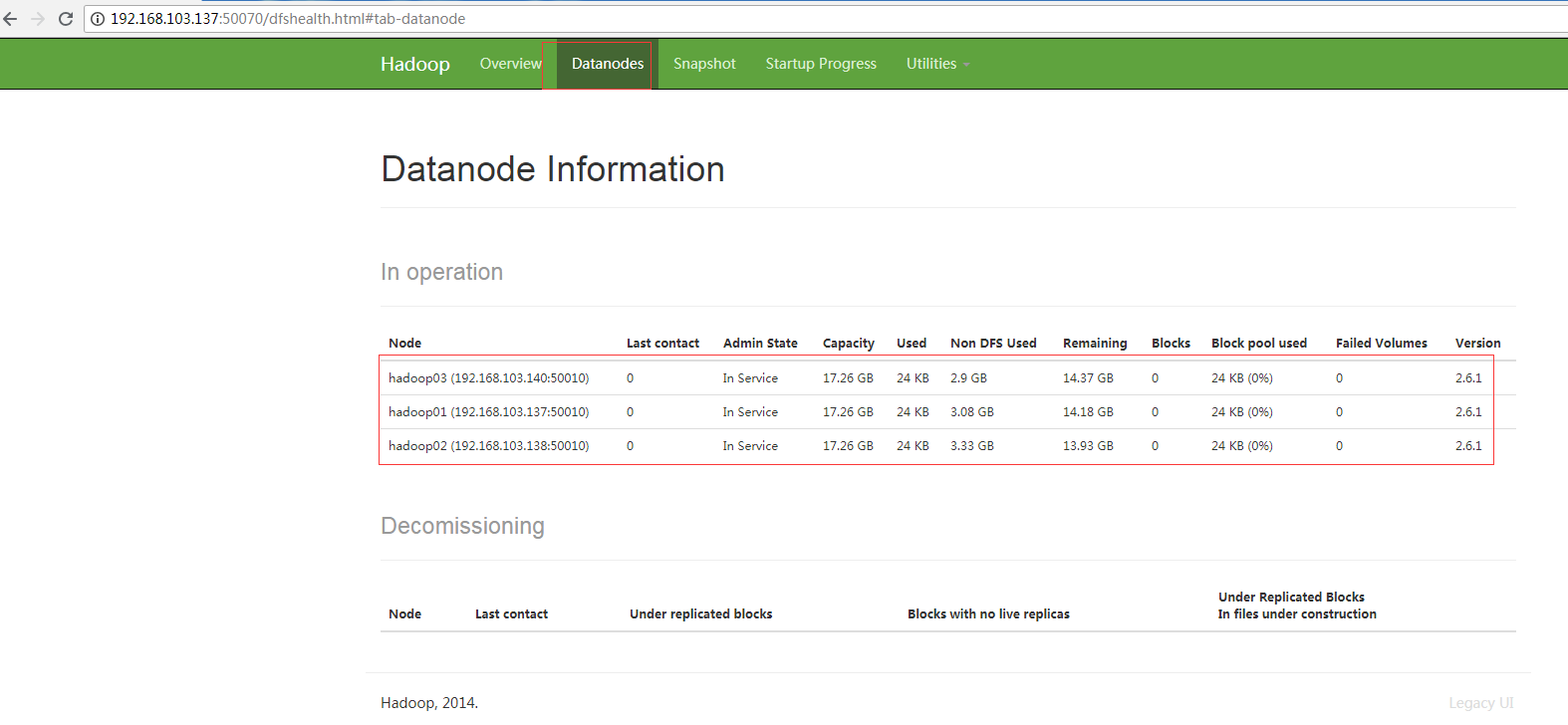
点击datanode查看数据节点
访问http://192.168.103.137:8088,查看MR任务


 浙公网安备 33010602011771号
浙公网安备 33010602011771号