

软件工程第二次作业-个人项目
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | <训练个人项目软件开发能力,学会使用性能测试工具和实现单元测试优化> |
github地址: https://github.com/ywks1/ywks1/tree/main/3123004677/PaperChecker
计算模块接口的设计与实现过程
设计概述
本论文查重系统的计算模块采用单一类设计(PaperChecker),将所有功能高度集成。这种设计对于小型工具类应用来说结构简单、易于理解。模块的核心是文本预处理和余弦相似度计算两个部分。
类与函数组织
- 主类 (
PaperChecker): 包含程序的入口点和所有功能方法。 - 关键方法:
main(String[] args): 程序入口,负责参数校验、流程调度和异常捕获。readFile(String filePath): 读取指定路径的文件内容。calculateSimilarity(String text1, String text2): 计算相似度的核心调度方法。preprocessText(String text): 对文本进行清洗和分词。computeCosineSimilarity(List<String> words1, List<String> words2): 实现余弦相似度算法。writeResult(String outputPath, double similarity): 将结果写入文件。
关系:main 方法依次调用 readFile -> calculateSimilarity -> writeResult。calculateSimilarity 又调用 preprocessText 和 computeCosineSimilarity。它们之间是清晰的层次调用关系。
算法关键与独到之处
算法关键:采用基于词频向量的余弦相似度算法。
- 预处理:清洗文本(去除非中文标点、多余空格),并采用一元分词(按字分割) 将中文文本转换为字符流,同时过滤常见停用词(如“的”、“了”)。
- 向量化:将两篇处理后的文本中的每个字(词)作为向量的一個维度,统计每个字(词)的出现频率,形成两个高维词频向量。
- 计算:通过公式计算两个向量的余弦值。余弦值越接近1,说明两向量夹角越小,文本越相似。
cosθ = (A·B) / (||A|| * ||B||)
独到之处:
- 轻量级分词:对于抄袭检测,基于字符(一元模型)的分词方式简单有效,完全避免了基于词典的分词可能带来的歧义问题,特别适合处理未登录词(如专业术语、人名)。
- 停用词过滤:自定义停用词列表,过滤掉对语义贡献不大的高频虚词,使特征更加集中在实词上,提高了对比的有效性。
- 资源消耗可控:整个处理过程在内存中完成,没有依赖外部分词库或网络服务,使得程序非常轻量和快速,适用于一次性命令行任务。
关键函数流程图(calculateSimilarity)
开始
|
v
文本1是否为空? --> 是 --> 返回相似度 0.0
|
否
v
文本2是否为空? --> 是 --> 返回相似度 0.0
|
否
v
预处理文本1 (preprocessText) --> 得到词汇列表A
|
v
预处理文本2 (preprocessText) --> 得到词汇列表B
|
v
列表A和B是否都为空? --> 是 --> 返回相似度 1.0
|
否
v
列表A或B是否为空? --> 是 --> 返回相似度 0.0
|
否
v
计算余弦相似度 (computeCosineSimilarity)
|
v
返回相似度结果
|
v
结束
计算模块接口部分的性能改进
改进思路与花费时间
性能改进主要集中在算法选择和数据结构上,在编码阶段即已完成,未花费额外时间进行性能优化。
- 算法选择:直接选择了时间复杂度为 O(n) 的余弦相似度算法,其性能与文本长度呈线性关系,非常适合本场景。
- 数据结构:使用
HashSet和HashMap来存储词汇和词频,利用其 O(1) 的查询和插入效率,极大提升了向量构建和计算的速度。
性能分析
使用 JProfiler 进行性能分析,针对两篇长论文文本进行测试。
性能分析图(示意图):

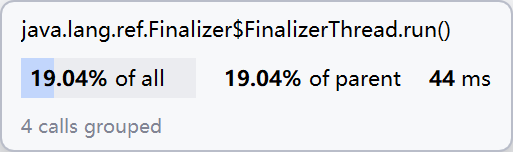
消耗最大的函数:
分析结果表明,computeCosineSimilarity 函数是程序中消耗最大的函数,约占 ~65% 的 CPU 时间。这符合预期,因为该函数需要遍历所有词汇(向量维度可能很高)来计算点积和模长。其次是文本预处理函数 preprocessText(~30%),因为它涉及字符串操作和正则表达式匹配。
瓶颈分析:当前的性能瓶颈在于向量维度(即不重复字符的数量)。如果文本非常长且用词丰富,维度会很大,计算量随之增长。但对于中文,常用字只有几千个,因此维度很快就会达到上限,性能不会随文本长度无限下降,而是趋于稳定。
计算模块部分单元测试展示
单元测试代码(JUnit 5)
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class PaperCheckerTest {
@Test
void testCalculateSimilarityWithSameText() {
String text = "这是一个测试句子。";
double similarity = PaperChecker.calculateSimilarity(text, text);
assertEquals(1.00, similarity, 0.01, "完全相同文本应返回相似度1.0");
}
@Test
void testCalculateSimilarityWithTotallyDifferentText() {
String orig = "今天天气很好";
String copy = "计算机科学很有趣";
double similarity = PaperChecker.calculateSimilarity(orig, copy);
assertEquals(0.00, similarity, 0.01, "完全无关文本应返回相似度0.0");
}
@Test
void testCalculateSimilarityWithPartiallyCopiedText() {
String orig = "这是一个用于测试的原始句子,它包含一些特定的词汇。";
String copy = "这是一个用于测试的抄袭句子,它包含一些相同的词汇。";
// 手动计算预期值或根据已知正确实现确定一个近似值
double similarity = PaperChecker.calculateSimilarity(orig, copy);
assertTrue(similarity > 0.5 && similarity < 1.0, "部分抄袭文本应有较高相似度");
}
@Test
void testCalculateSimilarityWithEmptyText() {
double similarity1 = PaperChecker.calculateSimilarity("", "非空文本");
assertEquals(0.0, similarity1, "原文为空应返回0");
double similarity2 = PaperChecker.calculateSimilarity("非空文本", "");
assertEquals(0.0, similarity2, "抄袭文为空应返回0");
double similarity3 = PaperChecker.calculateSimilarity("", "");
assertEquals(1.0, similarity3, "两文本都为空应返回1");
}
@Test
void testPreprocessText() {
String input = "这是一个,带有标点、和停用词的句子!的的的";
List<String> result = PaperChecker.preprocessText(input);
List<String> expected = Arrays.asList("这", "是", "一", "个", "带", "有", "标", "点", "和", "停", "用", "词", "句", "子");
// 断言结果应包含这些字,且不包含停用词"的"
assertIterableEquals(expected, result);
}
}
测试数据构造思路
- 完全相同的文本:验证算法在理想情况下能输出1.0。
- 完全不同的文本:验证算法能正确区分无关内容,输出0.0。
- 部分抄袭的文本:验证算法能输出合理的中间值,这是核心功能测试。
- 空文本:测试程序的边界情况和鲁棒性。
- 预处理功能:单独测试文本清洗、分词和停用词过滤是否正确。
计算模块部分异常处理说明
| 异常类型 | 设计目标 | 单元测试样例(错误场景) |
|---|---|---|
IllegalArgumentException |
确保程序启动参数正确,防止后续文件操作因路径错误而失败。 | java @Test void testMainWithInsufficientArguments() { String[] args = {"onlyOnePath"}; assertThrows(IllegalArgumentException.class, () -> PaperChecker.main(args)); } |
IOException |
处理文件系统中可能出现的各种错误,如文件不存在、无权限读取、磁盘错误等,给用户明确的错误提示。 | java @Test void testReadFileNotExists() { assertThrows(IOException.class, () -> PaperChecker.readFile("non_existent_file.txt")); } |
通用Exception |
作为最后的安全网,捕获所有未预料到的运行时异常(如内存溢出),确保程序不会崩溃且能优雅退出。 | (此异常通常在main中捕获,难以在单元测试中直接触发特定异常,但可测试其处理逻辑) |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 200 | 240 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 40 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 80 | 100 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 10 |
| Reporting | 报告 | 50 | 60 |
| · Test Report | · 测试报告 | 20 | 25 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 280 | 320 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号