

STCKA
核心:
针对因为没有足够上下文的导致语义模糊的短文本进行分类
具体思路:
利用外部资源加强短文本的语义 通过两个attention分别评估权重 综合进行文本分类
模型整体架构:
整体架构如下:
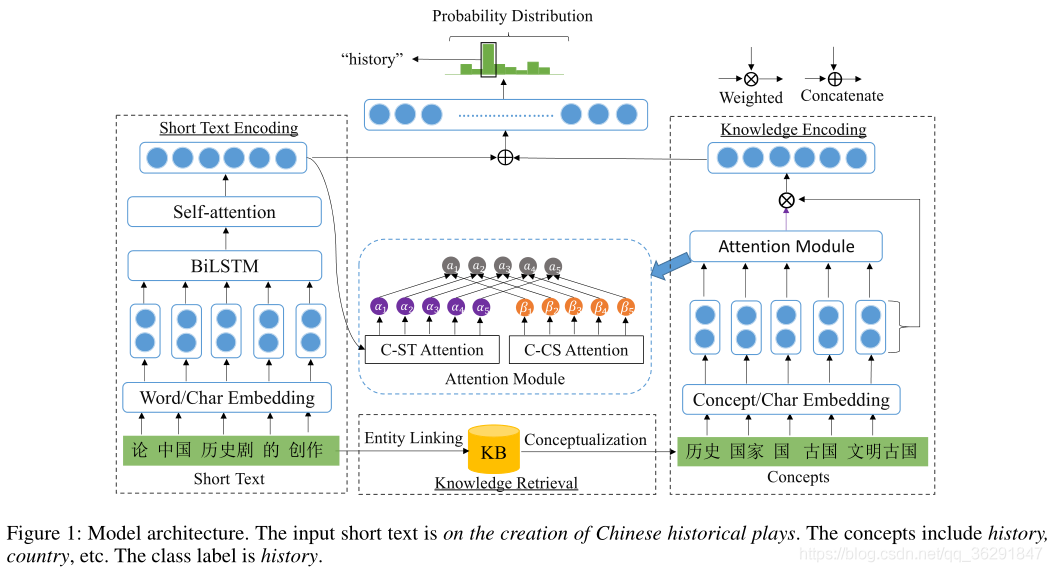
知识检索
通过实体链接技术将短文本中的实体链接到图谱中,然后获取到该实体在图谱中的概念化的知识(通过KBs)。如: 论“中国历史剧的创作”中的实体包括“中国”和“历史剧”; 从图谱中找出“中国”,然后获取它的概念得到“国家”、“国”、“古国”、“文明古国”; 从图谱中找出“历史剧”,然后获取它的概念得到“历史”;
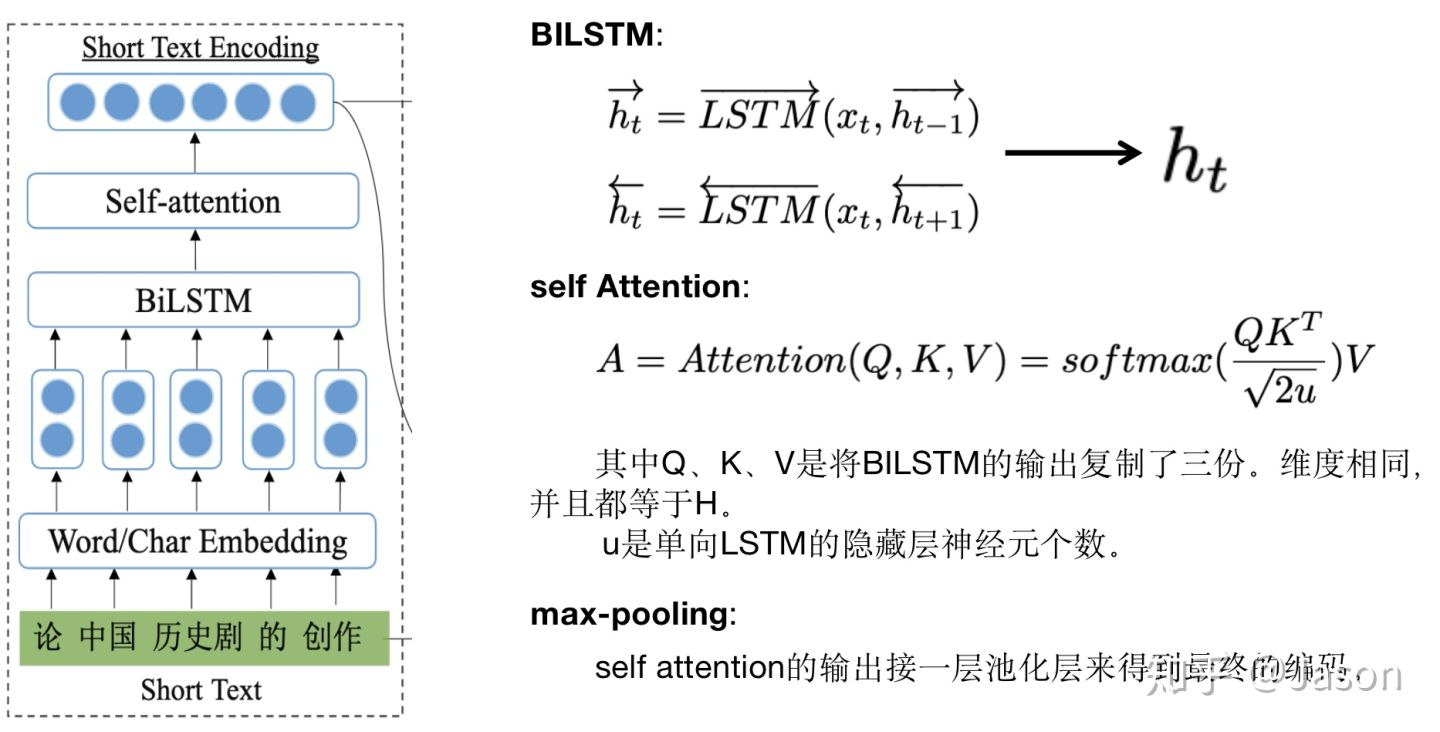
短文本编码
知识编码
为了防止attention的结果带来的网络退化问题,引入了残差神经网络结构。

输出部分
作者将两个编码部分的输出进行拼接,然后接一层全连接的层,将输出维度变换成我们的类别数,然后进行类别的预测,实现文本分类。
模型试验结果对比

Attention机制
结合了C-ST Attention(Concept towards Short Text)和C-CS(Concept towards Short Text)两种attention机制。
其中C-ST Attention是为了减少歧异词对模型的影响

而C-CS Attention 是判断概念重要性的自注意力机制
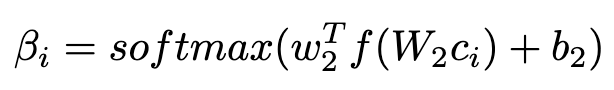
最后将两个注意力机制合并并引入了调节因子γ,取值范围为[0,1],用于调节两个attention之间的权重
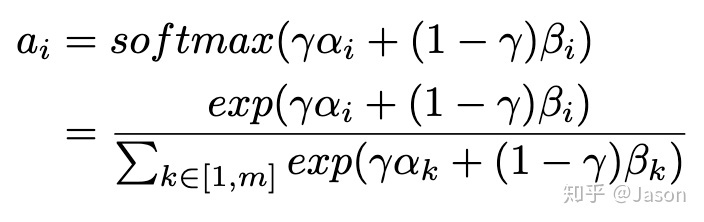

 浙公网安备 33010602011771号
浙公网安备 33010602011771号