

Attention注意力机制
Encoder-Decoder 框架
谈起attention注意力机制就不得不谈起它依附的框架 Encoder-Decoder框架。事实上这也是很多深度学习所使用的大致框架,特别是NLP领域。对应的框架如图
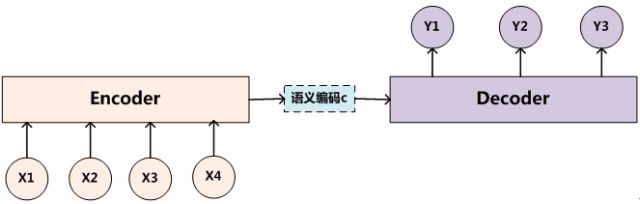
拿NLP领域举例,我们将一个句子或者是一篇文章其中的单词看作source集合 通过转化成target集合
其中语义编码c的就是Encoder的产物,然后再通过c进行Decoder生成target集合。这就是Encoder-Decoder框架。
Attention机制:
一般第i个单词的Encoder-Decoder框架中 Decoder的生成target的集合方式是计算关于前i-1个单词的Decoder结果和source中Encoder生成的语义编码c的非线性函数
但是语义编码c不变导致不能体现出相关性。Attention机制正是对于每个单词都计算出一个特殊的语义编码c使得文本、句子、单词之间的相关性便体现出来了。
Soft-Attention模型
Soft-Attention模型是比较传统的Attention模型,假设 I love you 这句话 翻译成中文 当翻译you这个单词的时候由于c一般默认相同所以非Attention的一般模型会体现不出 I love you 三个单词影响程度的大小,而soft-attention机制针对不同的单词动态分配了不同的注意力系数使得 使得Ci随单词变化,具体如下图:
Ci的计算方式如下:
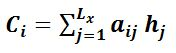
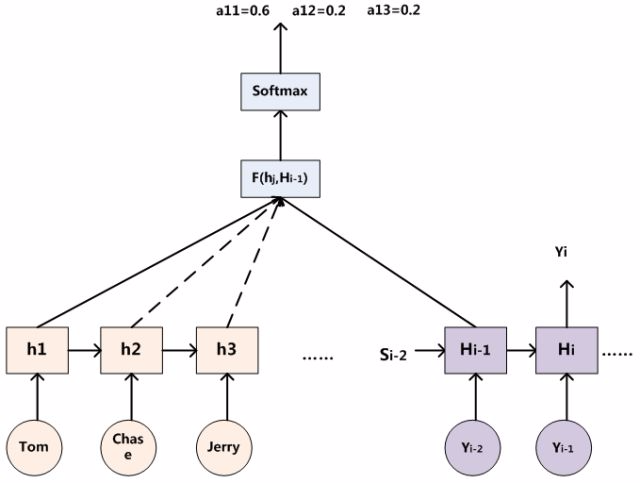
Lx代表句子的长度 aij是第i个target单词中source中第j个单词的注意力分配系数,hj就是输入句子中第j个单词的对应的非线性函数
所以Ci的计算本质上是加权求和
但是如何知道aij呢?下图提供了计算方式:
对于采用RNN的Decoder来说,在时刻i,如果要生成i单词,我们是可以知道Target在生成i之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“I”、“love”、“you”对i来说的注意力分配概率分布,那么可以用target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
所以我们有:
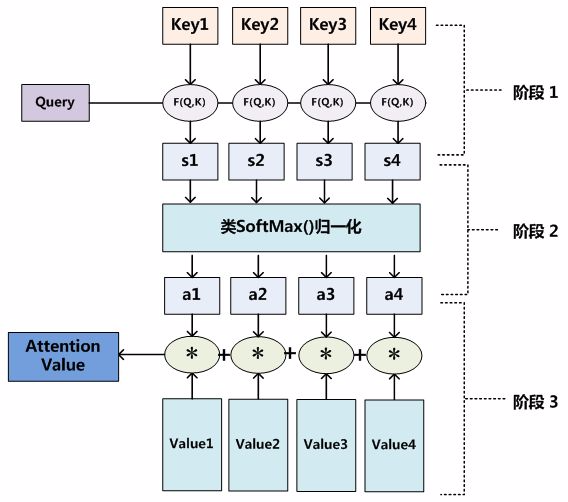
Query是i-1时刻隐藏层节点i-1的值 Keyi则是i对应的非线性函数的值,可以看出通过一种软地址的方式(查询Query=Key的地址但是遍历每个source中的每个地址寻找相似性)并且通过softmax函数算出权重aij,加权求和可以得到Ci的值,最后通过非线性函数即可得到对应的结果。
关于相似性的求法,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

Self Attention模型
顾名思义,发生在内部的Attention机制,即发生在source或者self自身内部的Attention机制,相较于需要依次计算的LSTM或者RNN,Self Attention模型通过内部对齐的思路,将单词与单词之间联系了起来,对于远距离相隔单词之间的联系非常有用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号