结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
一、以fork和execve系统调用为例分析中断上下文的切换
1、fork函数
头文件:#include<unistd.h>,#include<sys/types.h>
函数原型:pid_t fork( void);
返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
函数说明:在Unix/Linux中用fork函数创建一个新的进程。进程是由当前已有进程调用fork函数创建,分叉的进程叫子进程,创建者叫父进程。该函数的特点是调用一次,返回两次,一次是在父进程,一次是 在
子进程。两次返回的区别是子进程的返回值为0,父进程的返回值是新子进程的ID。子进程与父进程继续并发运行。如果父进程继续创建更多的子进程,子进程之间是兄弟关系,同样子进程也可以创建自己的子
进程,这样可以建立起定义关系的进程之间的一种层次关系。
2、execve函数
函数定义:int execve(const char *filename, char *const argv[ ], char *const envp[ ]);
返回值:函数执行成功时没有返回值,执行失败时的返回值为-1.
函数说明:execve()用来执行参数filename字符串所代表的文件路径,第二个参数是利用数组指针来传递给执行文件,并且需要以空指针(NULL)结束,最后一个参数则为传递给执行文件的新环境变量数组。exec
函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数。
3、编写分析fork函数和execve函数系统调用的代码
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); if (pid < 0) { /* error occurred */ fprintf(stderr, "Fork Failed!"); exit(-1); } else if (pid == 0) { /* child process */ execlp("/bin/ls", "ls", NULL); } else { /* parent process */ /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete!"); exit(0); } }
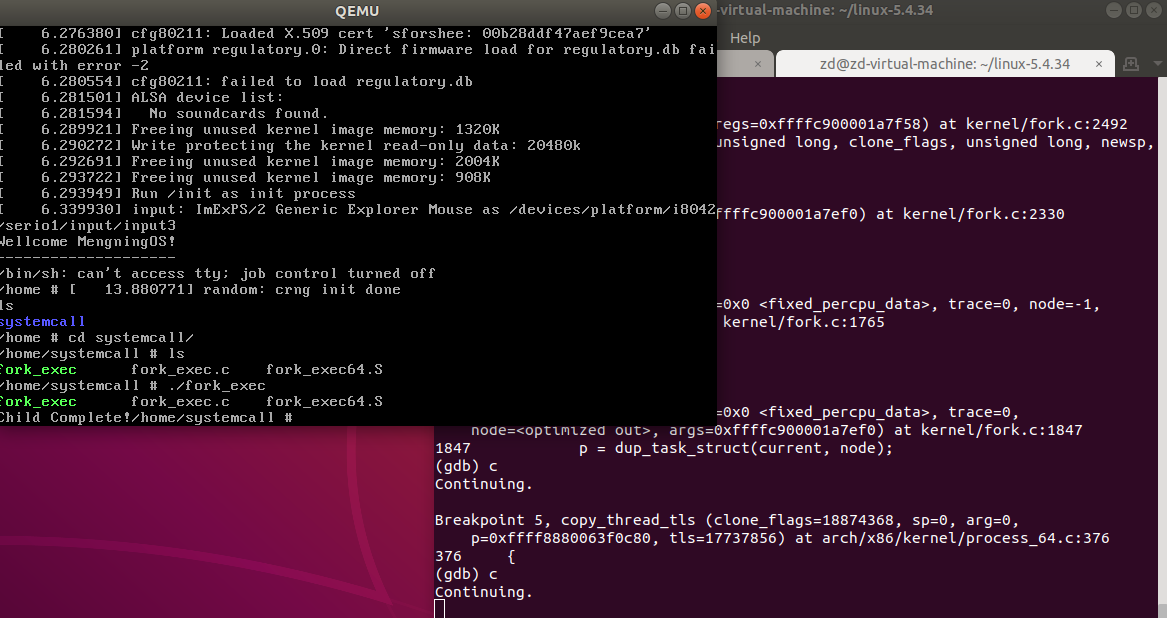
代码中包括fork函数和execve函数,可以同时进行debug,了解函数的调用过程。代码运行结果如下

4、根据上次的实验,将编写的函数打包到rootfs中,运行qemu,进行debug,对代码进行分析。
(1)分析fork调用
查看fork的系统调用号,在相应的地方打上断点
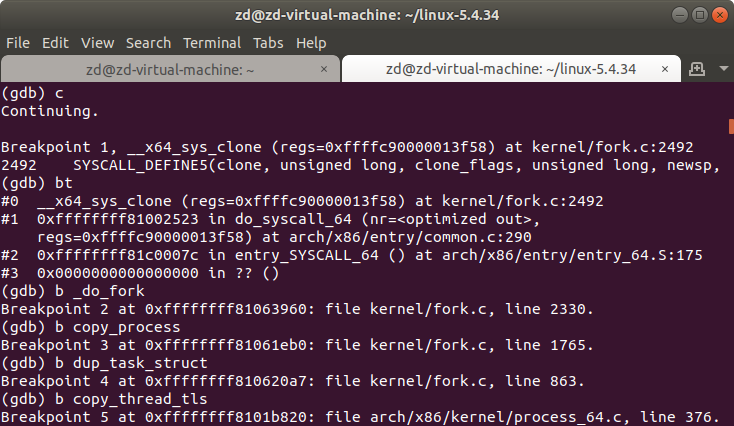
继续运行,在断点处输入bt,查看详细的调用过程。__x64_sys_clone —> __se_sys_clone —> __do_sys_clone —> _do_fork —> copy_process —> copy_thread_tls
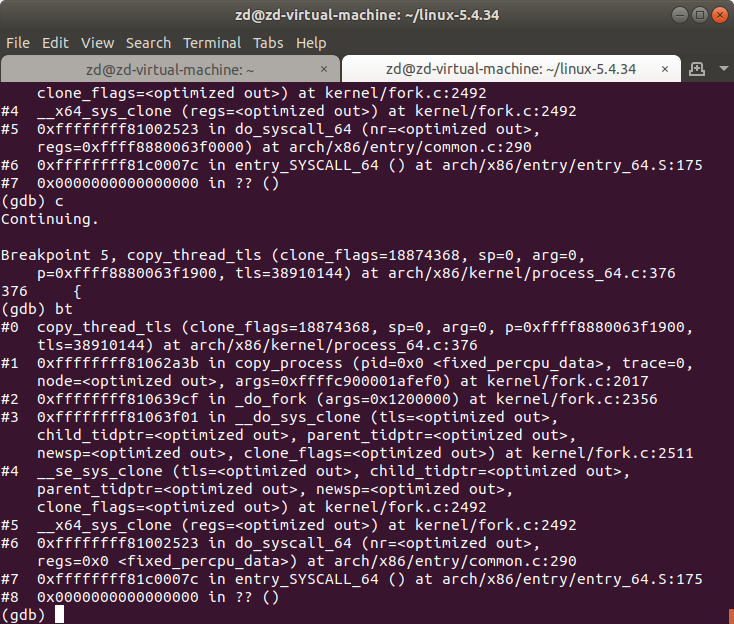
继续运行,结果如下
(2)分析execve函数调用
过程和fork函数类似,首先打断点,运行测试程序
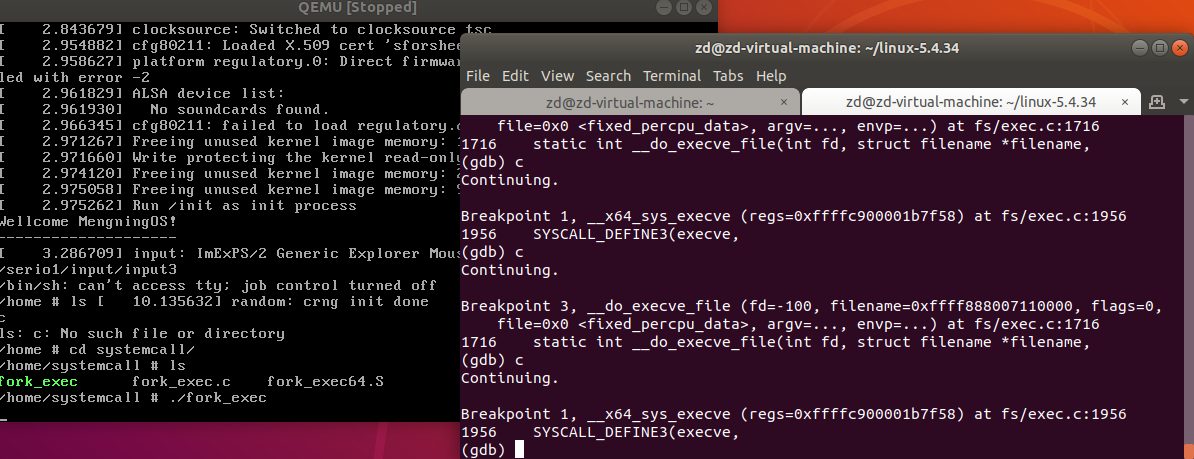
程序在断点处停止,输入bt,查看系统的调用过程。__x64_sys_execve —> __se_sys_execve —> __do_sys_execve —> _do_execve —> do_execveat_common —> __do_execve_file
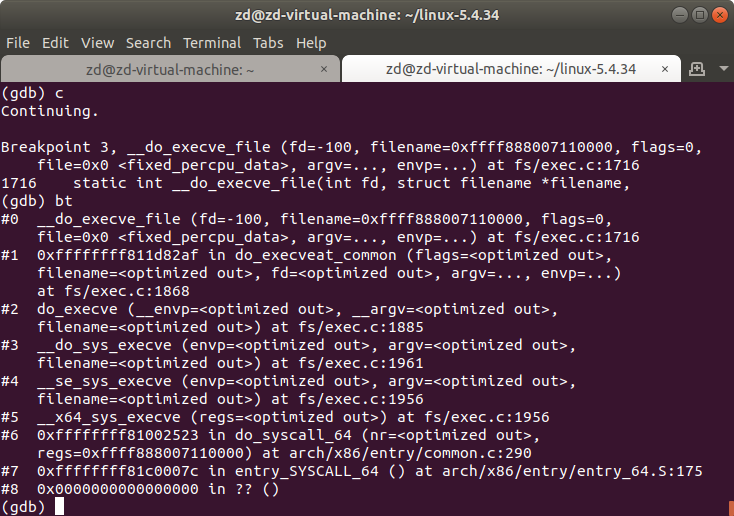
继续运行,结果如下
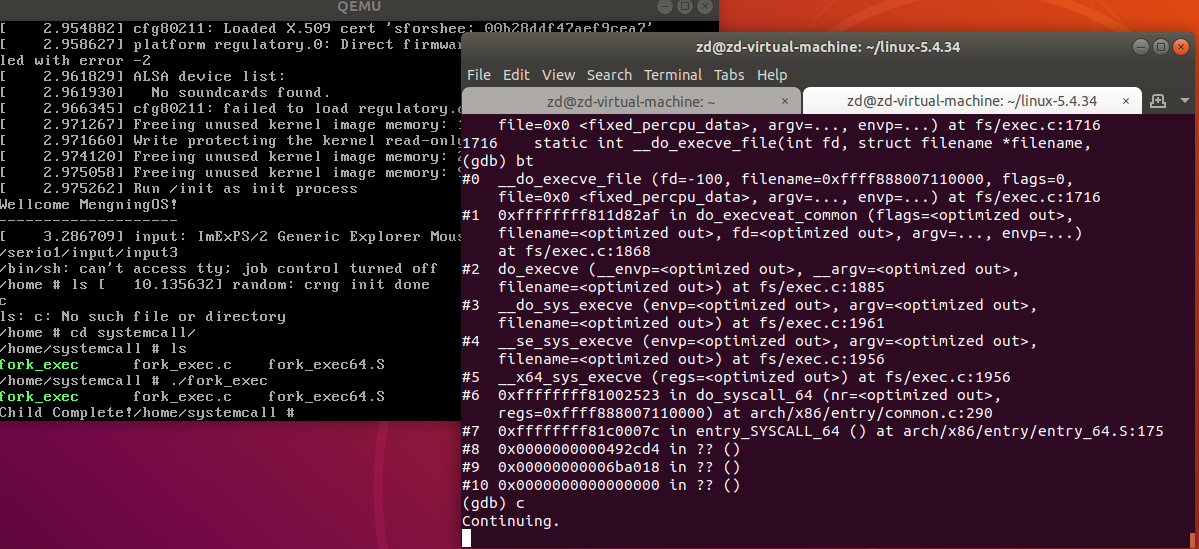
5、至此,我们根据debug的结果,知道了fork函数和execve函数的系统调用过程,下面通过阅读源码,进行详细的分析。
二、分析execve系统调用中断上下文和其特殊之处
1、根据debug的结果,execve函数首先进行系统调用,调用函数位于linux-5.4.34/fs/exec.c中,通过传入参数,调用do_execve()函数
SYSCALL_DEFINE3(execve, const char __user *, filename, const char __user *const __user *, argv, const char __user *const __user *, envp) { return do_execve(getname(filename), argv, envp); }
2、do_execve()函数将参数转换成相应的结构体,然后调用do_execveat_common()函数
int do_execve(struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) { struct user_arg_ptr argv = { .ptr.native = __argv }; struct user_arg_ptr envp = { .ptr.native = __envp }; return do_execveat_common(AT_FDCWD, filename, argv, envp, 0); }
3、do_execveat_common()函数继续调用__do_execve_file()函数
static int do_execveat_common(int fd, struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp, int flags) { return __do_execve_file(fd, filename, argv, envp, flags, NULL); }
4、__do_execve_file()比较复杂,主要的工作是把前面函数传入的参数复制到bprm结构体中,接着调用exec_binprm()进行可执行文件的加载
struct linux_binprm *bprm; struct files_struct *displaced; int retval; if (IS_ERR(filename)) return PTR_ERR(filename); /* * We move the actual failure in case of RLIMIT_NPROC excess from * set*uid() to execve() because too many poorly written programs * don't check setuid() return code. Here we additionally recheck * whether NPROC limit is still exceeded. */ if ((current->flags & PF_NPROC_EXCEEDED) && atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) { retval = -EAGAIN; goto out_ret; } /* We're below the limit (still or again), so we don't want to make * further execve() calls fail. */ current->flags &= ~PF_NPROC_EXCEEDED; retval = unshare_files(&displaced); if (retval) goto out_ret; retval = -ENOMEM; bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); //创建了一个结构体bprm, 把环境变量和命令行参数都复制到结构体中 if (!bprm) goto out_files; retval = prepare_bprm_creds(bprm); if (retval) goto out_free; check_unsafe_exec(bprm); current->in_execve = 1; if (!file) file = do_open_execat(fd, filename, flags); retval = PTR_ERR(file); if (IS_ERR(file)) goto out_unmark; sched_exec(); bprm->file = file; if (!filename) { bprm->filename = "none"; } else if (fd == AT_FDCWD || filename->name[0] == '/') { bprm->filename = filename->name; } else { if (filename->name[0] == '\0') pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd); else pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s", fd, filename->name); if (!pathbuf) { retval = -ENOMEM; goto out_unmark; } /* * Record that a name derived from an O_CLOEXEC fd will be * inaccessible after exec. Relies on having exclusive access to * current->files (due to unshare_files above). */ if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt))) bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE; bprm->filename = pathbuf; } bprm->interp = bprm->filename; retval = bprm_mm_init(bprm); if (retval) goto out_unmark; retval = prepare_arg_pages(bprm, argv, envp); if (retval < 0) goto out; retval = prepare_binprm(bprm); if (retval < 0) goto out; retval = copy_strings_kernel(1, &bprm->filename, bprm); if (retval < 0) goto out; bprm->exec = bprm->p; retval = copy_strings(bprm->envc, envp, bprm); //把传入的shell上下文复制到bprm中
if (retval < 0) goto out; retval = copy_strings(bprm->argc, argv, bprm); //把传入的命令行参数复制到bprm中
if (retval < 0) goto out; would_dump(bprm, bprm->file); retval = exec_binprm(bprm); //准备交给真正的可执行文件加载器了 if (retval < 0) goto out; /* execve succeeded */ current->fs->in_exec = 0; current->in_execve = 0; rseq_execve(current); acct_update_integrals(current); task_numa_free(current, false); free_bprm(bprm); kfree(pathbuf); if (filename) putname(filename); if (displaced) put_files_struct(displaced); return retval; out: if (bprm->mm) { acct_arg_size(bprm, 0); mmput(bprm->mm); } out_unmark: current->fs->in_exec = 0; current->in_execve = 0; out_free: free_bprm(bprm); kfree(pathbuf); out_files: if (displaced) reset_files_struct(displaced); out_ret: if (filename) putname(filename); return retval; }
6、调用exec_binprm(),函数中调用search_binary_handler(bprm),寻找可执行文件的处理函数
static int exec_binprm(struct linux_binprm *bprm) { pid_t old_pid, old_vpid; int ret; /* Need to fetch pid before load_binary changes it */ old_pid = current->pid; rcu_read_lock(); old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent)); rcu_read_unlock(); ret = search_binary_handler(bprm); if (ret >= 0) { audit_bprm(bprm); trace_sched_process_exec(current, old_pid, bprm); ptrace_event(PTRACE_EVENT_EXEC, old_vpid); proc_exec_connector(current); } return ret; }
7、search_binary_handler()中寻找能解析当前可执行文件的代码并加载,调用load_binary函数
int search_binary_handler(struct linux_binprm *bprm) { bool need_retry = IS_ENABLED(CONFIG_MODULES); struct linux_binfmt *fmt; int retval; /* This allows 4 levels of binfmt rewrites before failing hard. */ if (bprm->recursion_depth > 5) return -ELOOP; retval = security_bprm_check(bprm); if (retval) return retval; retval = -ENOENT; retry: read_lock(&binfmt_lock); list_for_each_entry(fmt, &formats, lh) { if (!try_module_get(fmt->module)) continue; read_unlock(&binfmt_lock); bprm->recursion_depth++; retval = fmt->load_binary(bprm); bprm->recursion_depth--; read_lock(&binfmt_lock); put_binfmt(fmt); if (retval < 0 && !bprm->mm) { /* we got to flush_old_exec() and failed after it */ read_unlock(&binfmt_lock); force_sigsegv(SIGSEGV); return retval; } if (retval != -ENOEXEC || !bprm->file) { read_unlock(&binfmt_lock); return retval; } } read_unlock(&binfmt_lock); if (need_retry) { if (printable(bprm->buf[0]) && printable(bprm->buf[1]) && printable(bprm->buf[2]) && printable(bprm->buf[3])) return retval; if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0) return retval; need_retry = false; goto retry; } return retval; }
8、因为可执行文件的种类很多,比如elf,a.out等格式。我们需要从内核全局linux_binfmt队列中找到一个能够处理参数中所给的可执行文件的linux_binfmt结构,具体就是依次试用linux_binfmt结构
中各自的load_binary()函数。如果找到,就返回load_binary获得的代码。
9、根据返回的解析函数,调用start_thread(),进行新程序的初始化,start_thread()中的eip来自 ex.a_entry,这就是该二进制文件的代码的起始地址而esp来自stark_stack,这是设置好用户堆栈的
函数参数后的堆栈指针位置。这样,当cpu从系统调用返回到用户空间时,就从ex.a_entry确定的地址开始执行。
start_thread(structpt_regs *regs, unsigned long new_ip, unsigned long new_sp) { set_user_gs(regs, 0); regs->fs = 0; regs->ds = __USER_DS; regs->es = __USER_DS; regs->ss = __USER_DS; regs->cs = __USER_CS; regs->ip = new_ip; regs->sp = new_sp; regs->flags = X86_EFLAGS_IF; /* * force it to the iret return path by makingit look as if there was * some work pending. */ set_thread_flag(TIF_NOTIFY_RESUME); }
10、execve系统调用的过程
(1)execve系统调用陷入内核,并传入命令行参数和shell上下文环境
(2)execve陷入内核的第一个函数:do_execve,do_execve封装命令行参数和shell上下文
(3)do_execve调用do_execve_common,do_execve_common打开ELF文件并把所有的信息一股脑的装入linux_binprm结构体
(4)do_execve_common中调用search_binary_handler,寻找解析ELF文件的函数
(5)search_binary_handler找到ELF文件解析函数load_elf_binary
(6)load_elf_binary解析ELF文件,把ELF文件装入内存,修改进程的用户态堆栈(主要是把命令行参数和shell上下文加入到用户态堆栈),修改进程的数据段代码段
(7)load_elf_binary调用start_thread修改进程内核堆栈(特别是内核堆栈的ip指针)
(8)进程从execve返回到用户态后ip指向ELF文件的main函数地址,用户态堆栈中包含了命令行参数和shell上下文环境
11、execve系统调用的不同之处
当前的可执⾏程序在执⾏,执⾏到execve系统调⽤时陷⼊内核态,在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来
的那个可执⾏程序了,⽽是新的可执⾏程序。 execve返回的是新的可执⾏程序执⾏的起点,静态链接的可执⾏⽂件也就是main函数的⼤致位置,动态链接的可执⾏⽂件还需要ld链接好动态链接
库再从main函数开始执⾏。
三、分析fork子进程启动执行时进程上下文和其特殊之处
1、fork、vfork和clone这3个系统调用和kemel_thread内核函数都是通过do_fork函数来创建进程的。而直接从 do_fork 来跟踪分析代码。do_fork的代码很复杂,我们通过主要的函数来了解其调用
过程即可。do_fork()主要完成 调用 copy_process()复制父进程信息 、获得 pid 、调用 wake_up_new_task 将子进程加入调度器队列等待获得分配 CPU 资源运行、 通过clone flags 标志做一些辅
助工作, 其中 copy_process()是创建一个进程内容的主要的代码。 接下来分析 copy_process()函数是如何复制父进程的。
long _do_fork(struct kernel_clone_args *args) { ..... //复制进程描述符和执⾏时所需的其他数据结构 p = copy_process(NULL, trace, NUMA_NO_NODE, args); ...... wake_up_new_task(p);//将⼦进程添加到就绪队列 ....... return nr;//返回⼦进程pid(⽗进程中fork返回值为⼦进程的pid) }
2、 copy_process()函数主要完成了:
(1)调用 dup_task_struct 复制一份task_struct结构体,作为子进程的进程描述符;
(2)初始化与调度有关的数据结构,调用了sched_fork,这里将子进程的state设置为TASK_RUNNING;
(3)复制所有的进程信息,包括fs、信号处理函数、信号、内存空间(包括写时复制)等;
(4)调用copy_thread_tls,设置子进程的堆栈信息;
(5)为子进程分配一个pid。
static __latent_entropy struct task_struct *copy_process( struct pid *pid, int trace, int node, struct kernel_clone_args *args) { ... p = dup_task_struct(current, node); ... /* copy all the process information */ shm_init_task(p); retval = security_task_alloc(p, clone_flags); if (retval) goto bad_fork_cleanup_audit; retval = copy_semundo(clone_flags, p); if (retval) goto bad_fork_cleanup_security; retval = copy_files(clone_flags, p); if (retval) goto bad_fork_cleanup_semundo; retval = copy_fs(clone_flags, p); if (retval) goto bad_fork_cleanup_files; retval = copy_sighand(clone_flags, p); if (retval) goto bad_fork_cleanup_fs; retval = copy_signal(clone_flags, p); if (retval) goto bad_fork_cleanup_sighand; retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; retval = copy_namespaces(clone_flags, p); if (retval) goto bad_fork_cleanup_mm; retval = copy_io(clone_flags, p); if (retval) goto bad_fork_cleanup_namespaces; retval = copy_thread_tls(clone_flags, args->stack, args->stack_size, p, args->tls); if (retval) goto bad_fork_cleanup_io; ... return p; ...
3、dup_task_thread()主要为子进程分配好内核栈
static struct task_struct *dup_task_struct(struct task_struct *orig, int node) { … //实际完成进程描述符的拷⻉,具体做法是*tsk = *orig err = arch_dup_task_struct(tsk, orig); … tsk->stack = stack; ... //实际完成进程描述符的拷⻉,具体做法是*tsk = *orig setup_thread_stack(tsk, orig); clear_user_return_notifier(tsk); clear_tsk_need_resched(tsk); set_task_stack_end_magic(tsk); }
4、copy_thread_tls()函数调用copy_thread,在早期版本3.18.6该函数叫copy_thread,它负责构造fork系统调⽤在⼦进程的内核堆栈,也就是fork系统调⽤在⽗⼦进程各返回⼀次,⽗进程中和其
他系统调⽤的处理过程并⽆⼆致,⽽在⼦进程中的内核函数调⽤堆栈需要特殊构建,为⼦进程的运⾏准备好上下⽂环境。另外还有线程局部存储TLS(thread local storage) 则是为⽀持多线程编
程引⼊的,我们不去深究。它的作用主要是对子进程幵始执行的起点 ret_from_kernel_thread(内核线程) 或 ret_from_fork(用户态进程), 以及在子进程中 fork 系统调用的返回值等都进行赋值。
5、fork()系统调用的不同之处
正常的⼀个系统调⽤都是陷⼊内核态,再返回到⽤户态,然后继续执⾏系统调⽤后的下⼀条指令。fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置
继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调⽤返回到⽤户态,所以它稍微
特殊⼀点。
四、以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
1、中断上下文
中断是由CPU实现的,所以中断上下⽂切换过程中最关键的栈顶寄存器sp和指令指针寄存器ip是由CPU协助完成的;中断上下⽂代表当前进程执⾏,所以中断上下⽂中的get_current可获取⼀个指向当前进程描述符的指针,
即指向被中断进程,相应的中断上下⽂切换的信息存储于该进程的内核堆栈中 。
2、进程上下文
进程切换是由内核实现的,所以进程上下⽂切换过程中最关键的栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的。 切换进程需要在
不同的进程间切换。但⼀般进程上下⽂切换是嵌套到中断上下⽂切换中的,⽐如前述系统调⽤作为⼀种中断先陷⼊内核,即发⽣中断保存现场和系统调⽤处理过程。其中调⽤了schedule函数发⽣进程上下⽂切换,当系统调
⽤返回到⽤户态时会恢复现场,⾄此完成了保存现场和恢复现场,即完成了中断上下⽂切换。
3、以系统调用为中断,分析linux系统的一般执行过程
(1)正在运行的⽤户态进程X。
(2)发生中断(包括异常、系统调用等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下文切换,具体包括如下⼏点:
swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调用入口处的汇编代码实现⽤户堆栈和内核堆栈的切换。
save cs:rip/ss:rsp/rflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调用是由系统调用入口处的汇编代码实现的。
此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5)switch_to调用了__switch_to_asm汇编代码做了关键的进程上下问文切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程 上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下文恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,而(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X切换到进程Y了
(7)为了对应中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7)iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完 成了中断上下⽂的切换, 即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运行用户态进程Y。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号