大模型学习笔记(四)—— 大语言模型预训练数据
数据处理
典型的数据处理流程如图所示,主要包括质量过滤、冗余去除、隐私消除、词元切分这几个步骤。

数据清洗
收集来的数据往往具有不一样的格式,数据清洗的目的是剔除明显的垃圾和无效内容,统一格式,包括:
-
格式清理:去除HTML标签、特殊符号、转义字符等。
-
空文本:删除空字符串或纯空格/标点。
-
编码错误:非 UTF-8 字符、乱码(如\x89\xfa\x91...)。
-
重复内容:彻底相同的文本块(如网页镜像)去重。
-
标准化:小写化、去 BOM、统一换行符等。
质量过滤
训练数据的质量对于大语言模型效果具有重大影响。因此,从收集到的数据中删除低质量数据成为大语言模型训练中的重要步骤。大语言模型训练中所使用的低质量数据过滤方法可以大致分为两类:基于分类器的方法和基于启发式的方法。
分类器可以是简单的逻辑回归、SVM(用于小数据或特征工程),也可以是预训练模型如BERT/DeBERTa/DistilBERT微调后的分类模型,通常需要一个人工标注的数据集作为训练集,例如:正样本是百科文章、新闻;负样本是论坛灌水、低质量评论。自动化程度高,泛化能力强,适合大规模数据,可对多种低质量特征进行联合建模。
启发器使用规则或统计特征来过滤明显的低质量文本,不依赖标注数据,快速上手,可解释性强,适合预过滤,但是灵活性差,尤其在处理大规模的数据集时。
文本重复检测其目标是发现不同粒度上的文本重复,包括句子、段落、文档等不同级别。句子级别的过滤使用的是类似KMP算法的公共子串匹配算法,去掉两个文档中重复长度超过len的句子。在文档级别上,大部分大语言模型依靠文档之间的表面特征相似度(例如 n-gram 重叠比例) 进行检测并删除重复文档。
删除隐私数据最直接的方法是采用基于规则的算法,利用命名实体识别算法检测姓名、地址、电话号码等个人信息内容并进行删除或者替换。
从大量的数据中选择最佳数据可能非常昂贵,因此该过程中常见的第一步是使用上述的各种过滤器删除数据,并且可能需要将多个过滤器连接在一起才能获得所需的数据集。
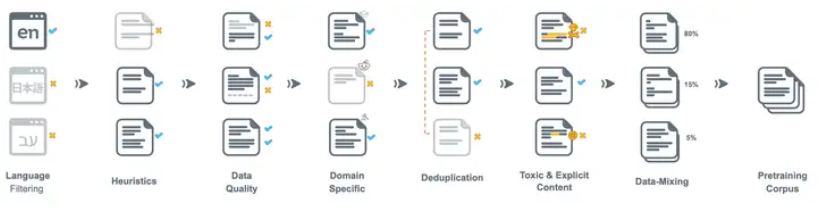
数据混合
不同来源质量差异大,但各有价值,高质量数据(百科、论文)可以提高语言理解能力,低质量/口语数据(论坛、对话)可以提升生成多样性,混合比例不同,模型能力会变化。数据混合根据数据来源、质量等级等因素,有策略地混合不同数据源,构建目标训练集。混合方法可以手动比例,也可以根据质量分数加权采样,对每条样本打质量分数,按概率采样。
⭐词元切分
主流的开源大语言模型几乎都提供了自己的分词器和编码器,把原始文本转换成模型可处理的Token序列,现代大语言模型基本不再使用词级词表,而是使用子词单元作为基本token单位进行建模和训练。因为词级词表会带来词表爆炸,无法处理未知词,稀疏性高等问题。传统的词级词表构建,是统计文本中出现的单词频率,按照频率编号。子词词元化方法会将单词划分为子词,也就是字母或词根片段。子词词表的构建,首先对初始分词按字符进行切分,之后统计字符对的频率,
合并频率最高的对并更新词表,重复合并直到词表达到设定大小。确定词元词表之后,对输入词序列中未在词表中的全词进行切分,若出现未登录词元,即未出现在 BPE 词表中的词元,则采取和未登录词类似的方式,为其赋予相同的表示,最终获得输入的词元表示序列。
词元切分可以生成更小的词表(32k-100k),兼顾语义和通用性,自动处理新词。
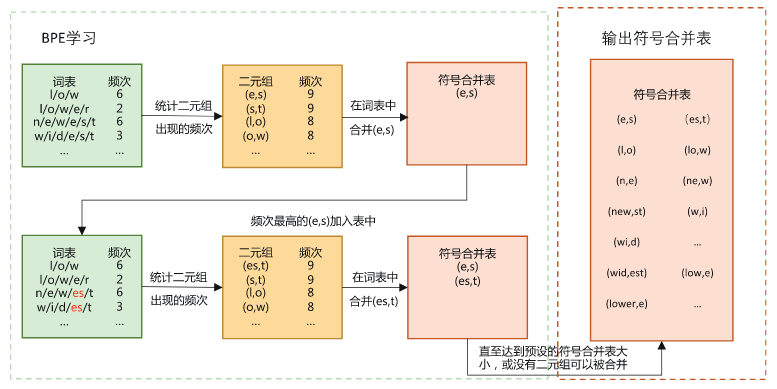
以unbelievably举例常见词元分词器的分词结果:
| 分词器类型 | 分词结果 |
|---|---|
| 词级词表 | "unbelievably"(若词表没有则OOV) |
| BPE | ["un", "believ", "ably"] |
| WordPiece | ["un", "##believ", "##ably"] |
| SentencePiece | ["▁un", "believably"] 或 ["▁un", "bel", "iev", "ably"] |
训练数据影响分析
数据规模
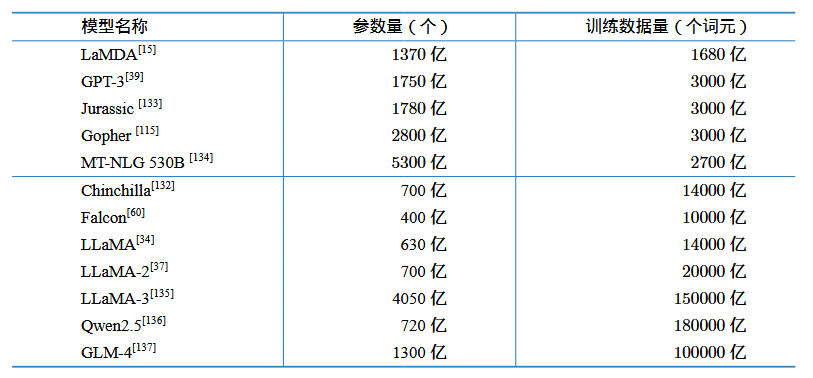
上图是目前比较流行的大模型的参数量和训练数据量,参考资料一里没有给出明确的结论,只是介绍了三个研究:1.DeepMind研究人员认为如果希望模型训练达到计算最优,则模型大小和训练词元数量应该等比例缩放,即模型大小加倍则训练词元数量也应该加倍。2.存在一个最佳模型参数量和训练数据量配置,给定计算量的情况下,随着参数量的增加,loss先下降后上升。3.LLaMA模型的训练发现,增大训练数据量,模型的表达能力随之增加,因此LLaMA不同版本的训练数据量在持续增加。
数据质量
除了对于文本的质量的研究,还有一些研究关注于数据时间对大模型的影响:
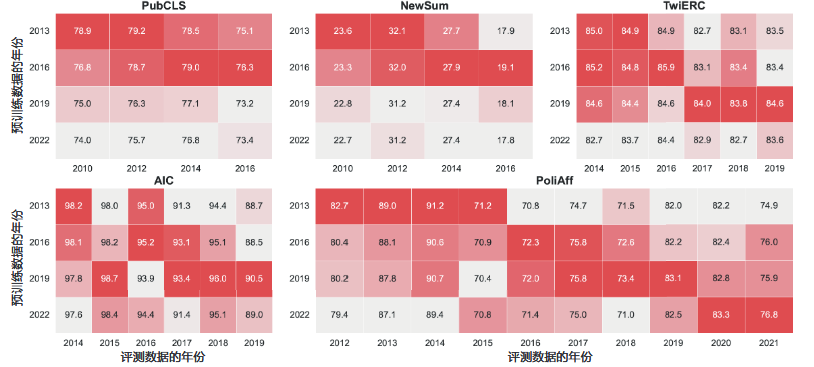
研究用的数据集分别是:PubCLS——生物医学文献分类数据集、NewSum——新闻文本摘要数据集、PoliAffs——政治意图识别数据集、TwiERC——社交媒体情绪识别数据集、 AIC——中文情感分析数据集。上图可知,训练数据和测试数据时间上的差异会带来明显的表现下降,相近年份的数据训练的模型预测效果最好。预训练数据和评估数据之间的时间不一致无法通过微调来解决,预训练数据时效性的影响对于较大的模型比较明显。
另一些研究显示出,重复数据会加强大模型的记忆能力,下图给出了出现次数和记忆率的关系,但是个人认为并没有参考性,只能作为一个了解。
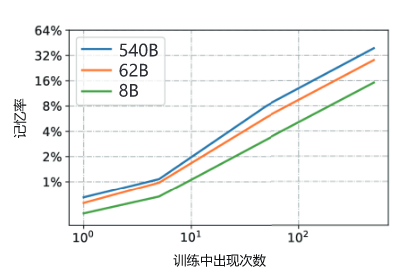
数据多样性
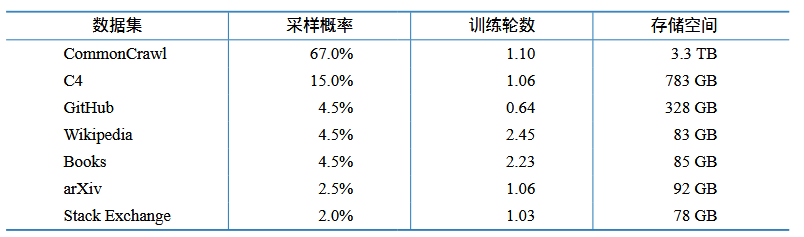
表3.2 给出了LLaMA 模型训练所使用的数据集。可以看到LLaMA 模型训练混合了大量不同来源的数据,包括网页、代码、论文、图书等。针对不同的文本质量,LLaMA模型训练针对不同质量和重要性的数据集设定了不同的采样概率,表中给出了不同数据集在完成 1.4 万亿个词元训练时的采样轮数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号