大模型学习笔记(二)—— 大语言模型的结构与预训练流程
常见的transformer架构包括:encoder-decoder, encoder only, decoder only,区别如下:
| 模型类型 | 输入 | 输出 | 示例模型 | 应用场景 |
|---|---|---|---|---|
| Encoder-only | 文本(如句子) | 表示(embedding) | BERT, RoBERTa | 分类、问答、文本检索等 |
| Decoder-only | 文本(带上下文) | 下一词预测 | GPT, LLaMA | 文本生成、对话、补全等 |
| Encoder-Decoder | 输入(如图像或句子) | 输出(翻译后的句子等) | T5, BART, mBART | 翻译、摘要、图文理解、多模态任务等 |
当前,绝大多数大语言模型都采用类似GPT的架构,使用基于 Transformer结构构建的仅由解码器组成的网络结构,采用自回归的方式构建语言模型,但是在位置编码、层归一化位置、激活函数等细节上各有不同。
LLaMA模型结构
下图是LLaMA的模型结构,由12个decoder堆叠而成,下面与transformer的decoder放在一起做对比:
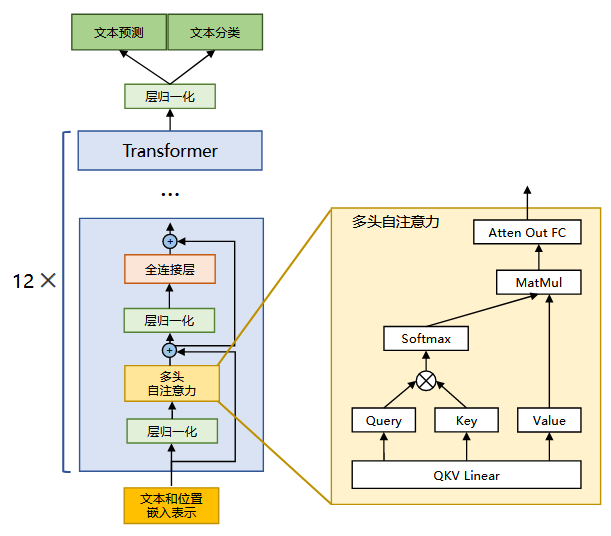
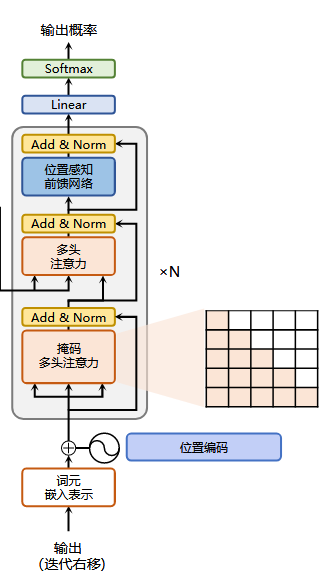
Decoder-only架构,不需要Cross-Attention,所以LLaMA的特点如下:
-
没有Cross-Attention:因为它不是Encoder-Decoder结构,只做自回归语言建模任务(如续写、对话),所以每个 Decoder Block中只有Masked Self-Attention,这个掩码是决定它是decoder的标志。
-
使用Pre-LayerNorm:LLaMA的每一层都使用
RMSNorm(Root Mean Square LayerNorm),而且是放在每个子模块的输入,不是输出之后再归一化,这称为Pre-Norm,相比Post-Norm稳定,支持训练更深的网络,输出经过Masked Self-Attention之后的层归一化,也是RMSNorm。 -
Rotary Position Embeddings(RoPE):LLaMA不使用传统的绝对位置编码,使用
RoPE,将位置编码融合进 Attention的Q/K中,使得位置感知更加平滑且易于推广到更长的序列。 -
多头Attention 更高效:LLaMA使用
FlashAttention等高效实现,使得推理和训练时内存与速度表现更优,在构建 Q/K/V 时的矩阵乘法优化也比早期Transformer更好。 -
更少的 Dropout、更紧凑的参数量设计:LLaMA没有
Dropout(或者极少使用),使用SwiGLU激活函数(而不是ReLU)。
RMSNorm归一化函数
针对输入向量a,RMSNorm函数的计算公式如下:
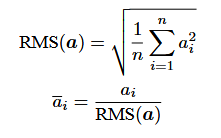
LayerNorm会对每个样本的所有特征做 均值为0,方差为1 的标准化,而RMSNorm只根据均方值(RMS)缩放输入,不进行中心化(不减均值)。LLaMA 选择RMSNorm的原因主要有:1. 计算效率更高(少一次均值计算)。 2. LayerNorm有时会破坏残差路径上的信息流,而RMSNorm没有中心化,更“温和”。3. 性能基本持平甚至略优。
SwiGLU激活函数
LLaMA的全连接层就相当于decoder的位置感知前馈网络,只是使用的激活函数不一样,decoder使用的是ReLU,LLaMA使用的是SwiGLU。

ReLU是简单、快速,直接把负数“砍掉”。而SwiGLU是一种门控激活机制(Gated Linear Unit 变种),在表现力和训练稳定性上明显优于ReLU,尤其适合大模型。对比可见它的优点:
| 特性 | ReLU | SwiGLU |
|---|---|---|
| 是否带门控机制 | ❌ 否 | ✅ 是(Gated) |
| 是否平滑 | ❌ 不平滑(0处不可导) | ✅ 平滑(可导) |
| 计算复杂度 | 低 | 中等(sigmoid + 乘法) |
| 表达能力 | 一般 | 更强(非线性更丰富) |
| 在大模型中表现 | 一般 | ✅ 更优(PaLM、GPT-4 使用) |
| 信息保留能力 | 容易截断(负值为0) | ✅ 更好(避免大量信息丢失) |
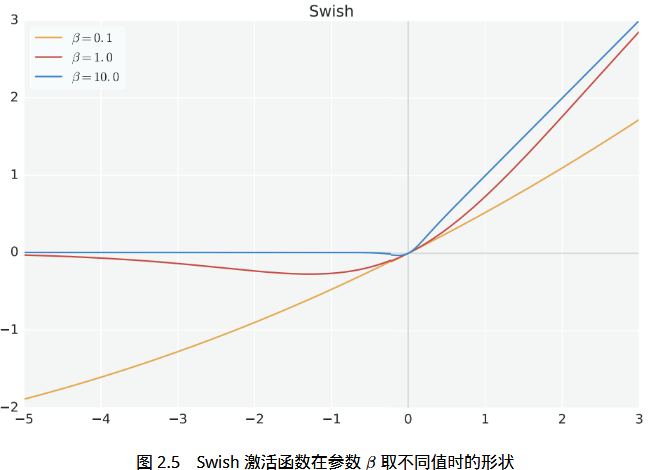
神经网络里,激活函数是为了增加非线性,又为了求导时保持导数连续有了sigmoid,而为了更大程度增加非线性,所以又有了SwiGLU,增加计算复杂度。
RoPE
使用旋转位置嵌入[48] 代替原有的绝对位置编码,绝对位置嵌入是指,每一个词的每一个嵌入的位置信息都是由位置本身计算的,且由于这种计算还有线性运算性质,所以位置信息被很好的保存了下来。
绝对位置的缺点是:位置是固定的;无法泛化到更长序列;只能处理训练时见过的位置。这里解释一下:虽然推理和训练时,使用的编码规则是一样的,但是如果训练的最大序列长度是512,那么只有512以内的位置编码对模型而言是熟悉的,对于512长度之外的位置编码,在模型眼里没有任何意义,甚至可能是噪声。
RoPE采用相对位置编码,相对位置编码和位置本身若相关,即使词是512位以外的位置,但是仍然是第520位词的相对增加n的位置。RoPE的编码原理是:通过改变每个 Query/Key 的“朝向”,让模型自然识别出词语之间的相对距离。将 Query 和 Key 通过一个二维旋转变换:
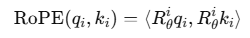
把 Query/Key 向量在不同位置进行不同角度的旋转变换。

其中:
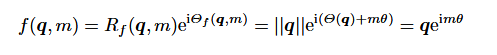
还可以写作:
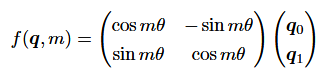
RoPE的角度θ与位置pos和频率freq挂钩:
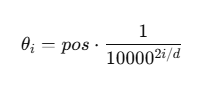
pos是token在序列中的位置(从 0 开始)i是维度的索引(一般按偶数编号)d是embedding的总维度- 10000 是一个经验超参数(同样用在原始Transformer中的
sin/cos位置编码)
旋转角度只和相对位置差有关,允许模型自然感知顺序信息,比如:位置5的token与位置6的token,二者旋转角度差值恒定。
注意力机制优化
对一些训练好的Transformer结构中的注意力矩阵进行分析时发现,其中很多是稀疏的,因此可以通过限制Query-Key对的数量来降低计算复杂度。这类方法称为稀疏注意力(Sparse Attention)机制。
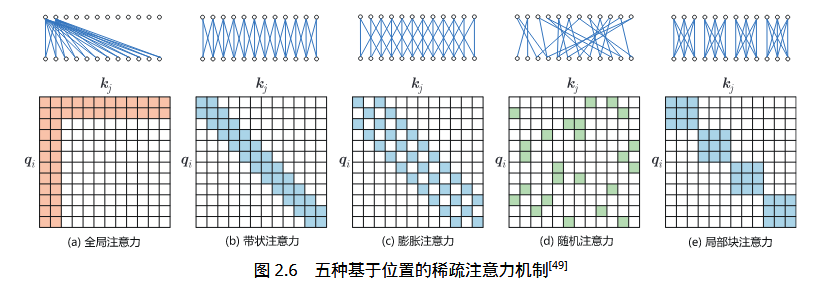
掩码注意力为了防止看到未来值,只是用下三角矩阵。类似的,为了保持稀疏性,各种注意力机制的优化也围绕着注意力矩阵的稀疏化,来降低计算复杂度。
FlashAttention
自注意力机制中,计算注意力矩阵、计算softmax、计算最终的结果分别要访问一次内存,共三次访问内存,GPU的计算速度比内存速度快得多,因此计算效率越来越受全局内存访问的制约。FlashAttention 的目标是尽可能高效地使用SRAM来加快计算速度,避免从全局内存中读取和写入注意力矩阵,它的核心思想是:不保存中间的注意力分数矩阵到内存,直接在SM内部原地softmax,然后加载V矩阵,在SM内计算计算最终结果,保存在显存HBM中。如下图所示:
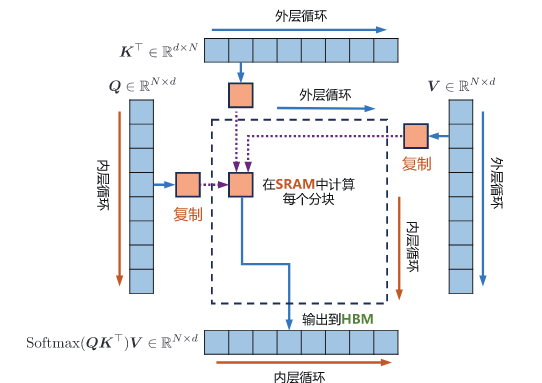
那么问题就是,softmax是首先需要你解决的,因为传统的softmax是以一行为单位做均一化,所以分母是一行的指数相加,但是为了保证精度不变,又必须使用整行为单位做归一化。那么方法就是分块:
-
将KQ按照分块加载到SM中,然后计算得到对应的socre。
-
找到每一个块的score的最大值,所有块的最大值比较,得到全局的最大值。
-
再遍历每一块,获得每一块的分母累加,再将所有块的分母累加,得到全局分母:
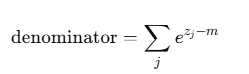
- 每一个块做自己的softmax。
Multi Query Attention
多查询注意力(Multi Query Attention)是多头注意力的一种变体。它的特点是,在多查询 注意力中不同的注意力头共享一个键和值的集合,每个头只单独保留了一份查询参数,因此键和值的矩阵仅有一份,这大幅减少了显存占用,使其更高效。
传统的多头注意力机制,将embedding进行了平均分配,然后每一个自注意力头都有了自己的KQV矩阵,最后得到的结果在embedding的维度进行合并就可以了。
大模型训练流程
大模型(尤其是语言模型、图像模型或多模态模型)的预训练,通常设计为自监督学习任务,不依赖人工标注,依靠大规模原始数据构建训练目标。
| 模型类型 | 预训练任务 | 描述 |
|---|---|---|
| GPT 系列 | Causal LM(自回归语言建模) | 给定前面所有词,预测下一个词 |
| BERT 系列 | Masked LM(掩码语言建模) | 随机mask掉输入中的某些token,预测它们 |
| T5 系列 | Text-to-Text | 把所有任务都转成文本到文本(翻译、摘要等) |
数据集
OpenWebText数据集示例段落:
Text: "The man walked into the bar and ordered a drink. The bartender asked, 'What'll it be?'"
Tokens: ["The", " man", " walked", " into", " the", " bar", ...]
目标是给定前 n 个 token,预测第 n+1 个 token。所有文本在训练前被:1. 分词(BPE 或 Byte-Pair Encoding)。2. 加入特殊 token(如 BOS、EOS)。 3. 拼接成固定长度序列(如1024个token一段)。
数据处理需要经过以下几个流程:原始文本 → 分句清洗 → 分词 → 编码成 token → 拼接为定长序列。
训练过程
GPT的预训练是自回归语言建模,也就是每一个位置都预测下一个位置是什么,所以对于一个输入长度为n的token,输出的张量大小就是n x V,其中V是词表长度。
| 位置 | 输入 Token(前缀) | 预测目标 |
|---|---|---|
| 1 | ["The"] | "cat" |
| 2 | ["The", "cat"] | "sat" |
| 3 | ["The", "cat", "sat"] | "on" |
| ... | ... | ... |
| n-1 | ["The", ..., "mat"] | "." |
这种自回归依赖于自注意力掩码实现,这样每一个位置就只能看到当前位置以及之前的词。
总的loss是所有位置的平均:
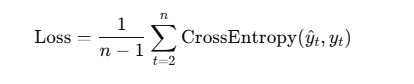
有监督下游微调
在有监督的下游微调任务中,我们通常根据目标任务(分类、问答、翻译、摘要等)使用结构化的标注数据集进行训练。以对话任务为例:
# 单轮问答
{
"question": "What is the capital of France?",
"context": "France is a country in Europe. Its capital is Paris.",
"answer": "Paris"
}
# 多轮问答
{
"dialogue": [
{"speaker": "user", "text": "Hi, I'm looking for a restaurant."},
{"speaker": "bot", "text": "Sure, what kind of food do you prefer?"},
{"speaker": "user", "text": "Something Chinese."}
],
"response": "There is a great Chinese restaurant called Peking Garden."
}
# 多轮对话(多参考答案)
{
"instruction": "Tell me a joke about cats.",
"input": "",
"outputs": [
"Why don't cats play poker in the jungle? Too many cheetahs.",
"What do you call a pile of kittens? A meow-tain.",
"Why did the cat sit on the computer? To keep an eye on the mouse!"
]
}
在对话任务中,微调是将问题和回答拼接一起送给模型进行预测,input = question + answer,输出和预训练是一样的,只是这里因为添加了问题,我们肯定不可以预测问题,所以使用 attention_mask 控制有效部分,将问题部分的预测值改为-100。由于模型是固定输入长度,所以输入的token序列长度设置为input的最大长度,长度不满足的用0来补齐。
input_ids = ["User:", "今天天气", "怎么样?", "Assistant:", "今天", "阳光", "明媚", "。"]
labels = [ -100 , -100 , -100 , -100 , "今天", "阳光", "明媚", "。" ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号